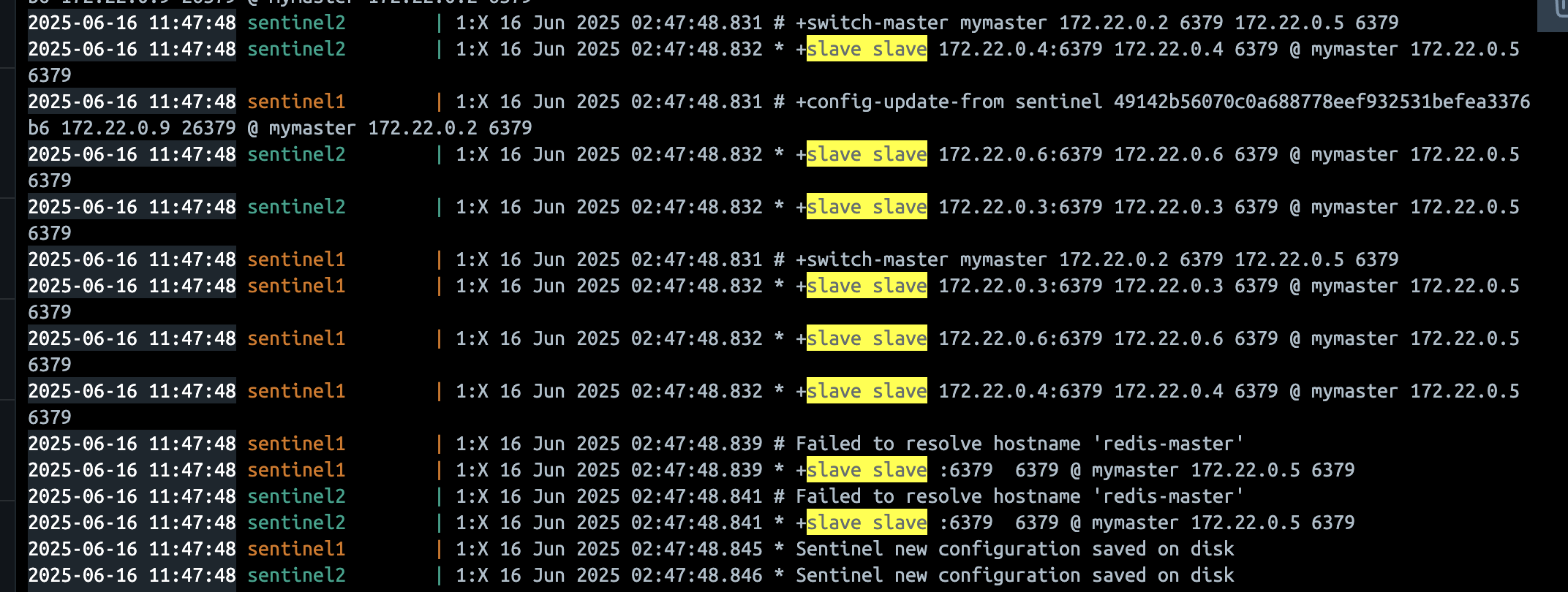
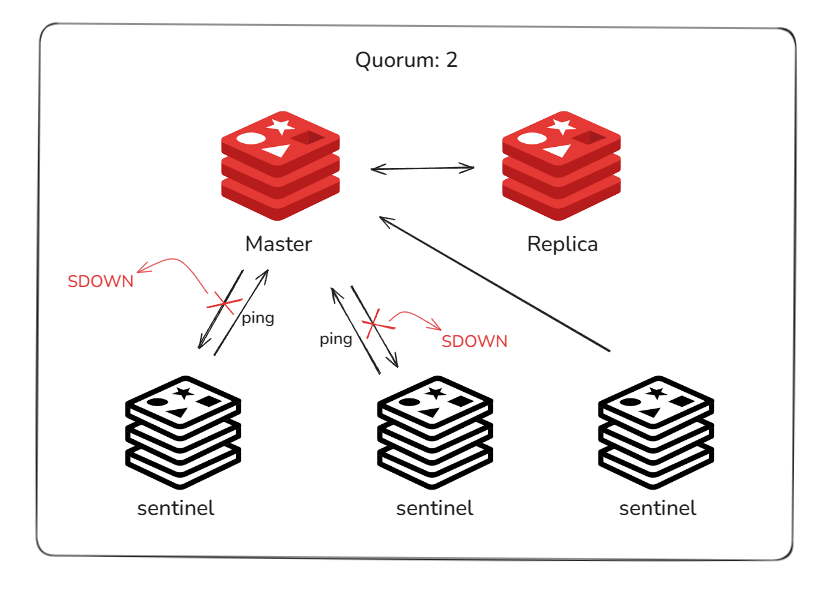
Sentinel은 Redis와는 별도의 구성으로, Redis Sentinel 문서에서 권장하는 최소 Sentinel인 3대의 Sentinel을 띄워 quorum을 만족시키도록 구성했다. 위 포스팅에서도 언급한 바 있지만, Sentinel은 failover 시 quorum을 만족해야 마스터를 전환할 수 있는데, 2개 이상의 Sentinel이 동의해야 객관적 장애(odown)로 판단할 수 있기 때문이다.
#entrypoint.sh
#!/bin/sh
sed -i "s/\$SENTINEL_QUORUM/$SENTINEL_QUORUM/g" /etc/redis/sentinel.conf
sed -i "s/\$SENTINEL_DOWN_AFTER/$SENTINEL_DOWN_AFTER_MS/g" /etc/redis/sentinel.conf
sed -i "s/\$SENTINEL_FAILOVER/$SENTINEL_FAILOVER_TIMEOUT/g" /etc/redis/sentinel.conf
exec docker-entrypoint.sh redis-server /etc/redis/sentinel.conf --sentinel
# sentinel.conf
# Example sentinel.conf can be downloaded from http://download.redis.io/redis-stable/sentinel.conf
port 26379
dir /tmp
# 도커 서비스명을 hostname으로 인식,
# 해당 설정이 없으면 `Can't resolve master instance hostname` 오류 발생.
sentinel resolve-hostnames yes
# master redis를 감시.
sentinel monitor mymaster redis-master 6379 $SENTINEL_QUORUM
# 장애 간주 시간 설정 (MS)
sentinel down-after-milliseconds mymaster $SENTINEL_DOWN_AFTER_MS
# 새로운 master가 된 redis에 동기화할 수 있는 slave(repl) 제한
sentinel parallel-syncs mymaster 1
# failover과정 전체의 timeout
sentinel failover-timeout mymaster $SENTINEL_FAILOVER_TIMEOUT
bind 0.0.0.0
이전 글에서 메시지 큐의 장애 발생 상황을 여러가지로 가정하고, 간단한 해결책들을 생각해서 서술했었다.
이번 글에서는 그 중에서도 특히 많은 메시지 큐에서 Redis를 저장소로 사용하거나 지원하는 만큼, Redis의 failover전략 중 하나인 Redis Sentinel에 대해 공식 문서와 실제 사례를 기반으로 공부한 내용을 작성한다.
Redis에 장애가 발생한다면?
생각해보면 Redis는 애플리케이션을 구성할 때 거의 대부분 사용했던 것 같다. 질의를 위한 쿼리에 대한 최적화를 수행해도 UX를 저해하는 경우에 캐싱하여 사용하고 있다. 추가로 랭킹 등의 집계 후 자주 변하지 않는 데이터에도 Redis에 올려 사용하고, 주기적으로 갱신하곤 했다. 기타 여러 상황들이 있겠지만, 나의 경우는 이 대부분의 모든 카테고리가 캐싱 이다.
내가 사용하는 Redis사례나 기타 사례 등은 Redis의 빠른 응답 특성을 이용해 최대한 DB 조회를 피하고자 하는 전략이 대부분이다.
보통의 이런 캐싱 전략에서, 정해놓은 주기가 만료된 후의 최초 요청에서는 캐싱된 데이터가 Redis에 존재하지 않기 때문에 DB Fetching 후 Redis에 적재하는 일련의 과정을 거친다. 만약에 이 Redis에 문제가 생겨서 Redis 서버가 다운됐다고 가정해보자.
Redis에 데이터가 없는 것을 포함한 모든 예외 상황 시 DB에서 데이터를 가져오게 만들었다고 가정해보자. 이제 Redis 장애로 인해 모든 캐시 미스 요청이 DB로 직행하게 되고, 이는 곧 DB의 TPS가 급증하게 되어 DB CPU의 과부하로 이어진다. 단일 DB 인프라에서는 특히 감당하지 못하고 서버 전체가 죽는 시나리오로 연결될 수 있다.
직전 포스팅에서도 메시지 큐가 레디스의 문제로 동작하지 않는다면, 서비스 직원분들의 업무 알림이 전혀 발생하지 않아 모든 업무가 마비될 것이다. 이는 곧 매출에 심각한 영향이 발생할 수 있다.
간단히 Redis의 장애 발생 시 여파들에 대해 알아봤다. Redis의 확장을 고려해야할 때가 온다면, Cluster에 대해서도 깊게 다뤄볼 예정이다. 하지만 고가용성만을 목적으로 했기 때문에 아래에서부터는, 현재의 환경에 맞춘 failover 을 구성하기 위한 Sentinel만을 다룬다.
Redis Sentinel
Redis Sentinel은 Redis의 고가용성(HA: High Availability)을 보장하기 위한 구성방식이다.
Sentinel의 특징
Sentinel은 Active-Passive 구조로 동작한다. 즉, 하나의 Master 노드가 활성화되어 있고, 나머지 Replica 노드들은 대기 상태에 있다. Sentinel은 이 Redis 인스턴스들을 모니터링 하며, 장애가 발생했을 때 해당 상태를 감지 하고, 알림을 전송 하며, 필요 시 Replica중 하나를 Master로 승격시켜 자동으로 failover를 수행 한다.
Sentinel 사용 권장사항
Sentinel은 단순한 Redis 프로세스가 아니다. 서로 통신하고 감시하며 장애 발생 시 투표를 통해 Failover을 트리거하는 분산시스템의 일부 이다. 이런 Sentinel이 하나만 있다면, 그것이 죽는 순간 전체 시스템의 복구 능력도 함께 사라진다. Sentinel을 1개만 두는 경우, 해당 인스턴스에서 장애 발생 시 아무도 Redis를 감지할 수 없고, 자동 failover도 동작하지 않는다. 가용성을 위한 감시 시스템 자체가 SPOF 이 되는 셈이다.
그래서 Redis 공식 문서에서도 항상 3개 이상의 Sentinel 프로세스를 운영할 것을 가장 우선해서 권장한다. 이런 이유로 Sentinel은 독립적으로 장애가 발생할 것으로 예상되는 서버에 배치하는게 좋다. 아래 예시 구성에서는 도커 컨테이너로 세 개의 Sentinel을 띄워 테스트해 볼 예정이다.
다시 정리하고 넘어가자면, Sentinel을 분산 배치하는 이유는 장애 감지의 신뢰성 확보와 더불어 자체 장애에 대한 복원력 확보에 있다. 특정 Sentinel의 오탐지로 잘못 바뀌는걸 방지하며, Sentinel이 죽더라도 다른 Sentinel들이 감시를 이어갈 수 있기 때문이다.
Sentinel들은 다음과 같은 방식으로 협업한다.
모든 Sentinel들은 Redis Master의 상태를 독립적으로 모니터링한다.
Master에 문제가 생긴 것으로 의심되면, 이를 다른 Sentinel에게 전파한다.
이 상태에서 정해진 정족수(Quorum)이상이 Master가 죽었다고합의(Voting)하면, Failover가 시작된다.
Sentinel들은Quorum이라는 설정된 최소 합의 Sentinel 수가 서로 합의되어야 failover를 수행한다. 이 때 Quorum은 기본적으로 과반수를 따르지만, 설정을 통해 지정할 수도 있다.
Sentinel은 "하나의 Sentinel은 누구도 믿지 않는다" 는 전제를 기반으로 신뢰 기반의 감시 구조를 만들기 위해 반드시 다중 구성과 투표 기반 구조를 요구한다.
그렇다면, Sentinel은 언제 어떤 기준으로 Master가 죽었다고 판단할까? 장애 인식 과정을 간단하게 알아보자.
장애 인식과 Failover
Sentinel은 SDOWN(주관적 다운)과 ODOWN(객관적 다운)을 통해 Master 노드의 장애를 인식한다.
우선 각 Sentinel은 개별적으로 ping을 보내 상태를 감시하는데, 이 때 응답이 없다면 SDOWN으로 간주한다.
잠시 네트워크 이상 등의 일시적인 현상일 수도 있기 때문에, 주관적 다운 상태로 변경된다. 하지만 여러 Sentinel들이 동일하게 이 SDOWN을 감지한다면 Master 노드에 문제가 있는 상태로 간주한다. Quorum 이상의 SDOWN이 감지되는 이 때, ODOWN으로 승격되고 failover 작업이 시작된다.
가장 먼저 투표 요청을 보내고, 과반수 이상의 동의를 얻은 Sentinel이 리더로 선출된다. 이 때 리더는 다음과 같은 역할을 수행한다.
Replica 노드들 중 적절한 노드를 선택하여 새로운 Master로 전환한다
나머지 Replica를 새 Master를 바라보도록 설정
다른 Sentinel들과 클라이언트에게 새로운 Master의 정보를 전파
새로운 Master 노드가 선정되더라도 시스템 전체가 기존처럼 하나의 구성으로 수렴되어야한다. 리더 Sentinel은 새로운 레디스의 구성을 Configuration Epoch 값과 함께 전파한다. 이 값은 일종의 버전 관리를 위한 값으로 가장 최신의 구성이 무엇인지를 구분할 수 있게 해준다.
또한, 모든 Sentinel들은 __sentinel__: hello 채널을 통해 주기적으로 구성 정보를 공유 하는데, 이 때 더 높은 epoch를 가진 구성을 선택하여 자연스럽게 일관적인 시스템 구성으로 수렴 된다.
1년 전쯤에,고잉버스(GoingBus) 구독 공유를 통해 ChatGPT를 사용했던 후기를 공유한 적이 있었다. 그래서일까, 일종의 광고 문의 같은게 들어왔다. 유튜브, 넷플릭스, 디즈니 등을 비롯해서 최근에는 AI들도 필수 요소들이 되어 필수 소비재가 늘어남에 따라 누군가 겜스고를 이용하고자할 때 싸게 이용했으면 하는 바램에서 작성하는 글이다.
필자는 유튜브 프리미엄 외에는 딱히 OTT는 이용하지 않는다. 하지만 개발자라는 직업 특성상 AI 활용은 트렌드를 넘어 필수 역량이 되었다. 그렇기 때문에 IDE인 Cursor 결제를 포함해서, OpenAI, Claude 등을 구독 결제를 통해 매달 60달러 정도를 필수 지출로 사용중이다.
가입 후 최초화면
나처럼 AI를 많이 사용하던, OTT를 결제해서 이용을 하든 요즘 사회의 필수 소비재들의 구독제 시스템의 과소비(?)의 문제를 해결하고자 여러 구독 공유 서비스들이 나온 것 같고, 이 겜스고도 이 구독 공유 서비스중 하나로 보인다.
1년 전에 고잉버스를 이용했을 때와의 차이점이라고 한다면, 이제 여러 AI들이 서로 경쟁하며 발전하고 있기 때문에 이에 따라 기본적인 Chat GPT와 더불어 Claude, Gemini, 퍼플렉시티까지 지원하고 있고 몇 달전 화제였던 딥시크도 있는 게 인상적이다. 이 외에도 다양한 직군에서 사용되는 MS의 SaaS들과 피그마 등 다양한 서비스를 지원하고 있다.
플랫폼을 돌아보면서, 1년 전의 고잉버스와 가장 크게 다르다고 느껴졌던 부분은 몇 명의 사용자와 공유할지에 대한 선택지가 있다는 것이었다. (확인해본 바로는 고잉버스 또한 현재는 6인, 3인 공유는 선택 가능하다.)
구매를 완료하고나면, 오늘 날짜 기준으로는 GPT 4o 모델 ( + mini 등) 의 사용이 가능한데, 유의할 점은 공유 계정일 경우 다른 사용자 또한 GPT 질의 내용을 볼 수 있다는 점이다. 나는 이 점이 불편해서 고잉버스를 사용하지 않았었는데, 겜스고에서는 이런 구독 공유 플랫폼의 단점이 GPT 1인 계정을 통해 해소되었다.
또 메리트가 있다고 생각한 부분이, 바로 유튜브 프리미엄인데 생각보다 유튜브 프리미엄을 싸게 사용할 수 있는 것처럼 보인다.
자꾸 고잉버스와 비교하게되는데 (고잉버스만 1년 전에 써봐서..) 고잉버스는 아래처럼 5인 공유밖에 없는데다가 가격도 월 5달러 정도로 책정되어 있었다.
겜스고는 1인 계정 구독도 가능한데, 가격 측면에서도 20% 정도 저렴해서, 유튜브 프리미엄을 보다 더 싸게 이용할 수 있다.
유튜브는, 유튜브 계정을 겜스고에 입력해서 가족 계정에 초대받는 포맷이다 .아래 흐름대로 유튜브 프리미엄 가족 그룹에 초대되고 나면, 정상적으로 프리미엄을 이용할 수 있다.
정리
1년 전에 고잉버스 글을 게시했을 때에도, ChatGPT의 구독 공유의 단점을 지적한 바 있다.
광고 글이라고 생각이 달라진 건 없다. 여전히 많은 AI를 사용하고 있지만, 앞으로도 구독 공유가 되는 부분이 치명적인 단점이라 생각하기 때문에, 금액을 조금 줄이고자 누군가와 같이 AI를 사용할 생각은 없다. 고잉버스를 사용했을 때는, 유튜브 프리미엄조차 다른 계정과 공유되기 때문에 사생활이 침해될까 싶어 1달 사용 후 해지를 했었다.
하지만 겜스고에서 유튜브 프리미엄 정도는 결제해서 사용해도 괜찮겠다는 생각이 들었다. 무엇보다 개인 계정이라는게 가장 큰 메리트였고, 6~70% 더 싼 가격에 이용하는 것도 한 몫 하는 것 같다.
마지막으로, 한 번 더 추천인 링크와 프로모션 코드를 남기며 글을 마무리한다. 필요한 사람이 있다면 한 번 써보는 것도 좋을 것 같다.
내가 어떤 조직에 속하게 되었을 때, 조직에서 관리하는 애플리케이션을 한 번씩 사용자 관점에서 돌아보고, 개발자 관점에서 돌아보고 문제점을 리스트업하는 습관이 있다. 이를 통해 당장의 애플리케이션에 대한 이해를 넘어서, 어느 정도의 주인의식과 우선적으로 해결해야하는 과제는 무엇인지 선정하는 연습(?)을 같이 하고 있다.
이 포스팅은, 속했던 조직에서 가장 먼저 개선해야한다고 판단했던 실시간 채팅 기능의 개선기이며, 2년차인 현재 시점에서 더 개선할 부분은 없었는지가 첨가된 포스팅이다.
모자란 내용에 혹여 더 좋은 의견 남겨주시면 성장에 큰 도움이 됩니다. 감사합니다!
문제 파악하기
속했던 조직은, 커머스 비스무리한(?) 서비스를 운영하고 있었지만, 도메인 특성상 결제는 곧 예약이었다.
결제 후 오프라인으로 상품을 직접 소비(?)하는 특징과 더불어 상품들이 우리가 자주 소비하는 필수 소비재들의 성격이 아닌, 특정 니즈에 따라 대부분 일회성으로 구매하는 상품들이기 때문에 결제 전/후로 채팅을 통한 상담이 서비스의 코어였다.
이런 핵심 기능인 채팅에서 응답 속도가 평균 3초정도로 매우 느리게 동작했고, 이는 시간을 갈아넣어서라도 반드시 해결해야하는 최우선 과제라고 판단했다.
최초에 파악했던, 채팅 전반의 플로우를 그림으로 나타내보았다. 메시지를 전송하면, 기본적인 메시지 관련 데이터베이스 I/O 작업과 더불어 메시지 전송에 처리되어야 할 모든 기능들이 함께 동기적으로 처리 되고 있었다. 근본적으로 응답 속도가 느릴 수 밖에 없는 구조였다.
더불어 아이러니하게도 이 실시간 채팅을 포함해 애플리케이션 내부에서 MyISAM 엔진을 사용하고 있었다. 동시성 제어를 위해 테이블 락 매커니즘을 사용하는 MyISAM의 특성상 쓰기 작업이 느릴 수 밖에 없었다. 여기저기 쓰기 작업을 하게 되는데, 메시지가 많아지면 많아질 수록 여러 테이블에서 서로 쓰기 작업을 위해 기다리는 현상이 기하급수적으로 늘어날 수 밖에 없다.
효과적인 테스트와 구현을 위해, 당시 최대 TPS를 산정해서 예상 최대 지점까지 고려했다면 어땟을까?
여기까지 생각이 미치지 않았다보니, 워커의 처리량보다 큐에 작업 유입량이 많을 때 어떻게 대처할지 등의 비동기 작업의 안전성을 보장하지 못했다고 생각한다.
비동기 처리를 위해
스토리지 엔진의 한계 외에도 단순 하나의 로직에 이리저리 얽혀있는 여러 비즈니스 로직들을 살펴보고, 메시지 전송 과정에서 반드시 수행되어야 할 로직과 아닌 로직들을 분리 했다. 메시지 전송이 성공했다. 라는 의미는 메시지를 저장하는 chat_message 테이블에만 입력을 보장하면 된다고 판단했고, 나머지 로직들을 전부 분리했다.
이 분리한 로직들을 다시 네 개의 구간들로 나눴고, 원자성을 보장해야하는 구간을 추가 DB 입력 구간인 추가 I/O와 업무 알림으로, 실패해도 괜찮다고 판단되는 부분들을 푸시알림과 SMS전송으로 구분했다.
메시지 전송 로직과 분리하여 비동기 처리를 수행하기 위해 BullMQ라는 메시지 큐를 사용했다. Kafka나 RabbitMQ 등도 Nest의 공식 문서에 UseCase등을 문서화해뒀는데 사용하지 않았다. 이들을 사용하기에는 발톱의 때 만큼의(?) TPS였다. 또 Nest에서 기본적인 Queue 사용문서 에 친절하게 언급되어있는 BullMQ의 실패 시 재시도와 스케줄링과의 연동, 이벤트 기반 처리와 이벤트 리스너를 통한 통합 로깅 등을 구현하기에 용이했기 때문에 BullMQ를 사용했다.
TPS를 산정했을 때, 최대 TPS는 1.55였다. 단일 워커에서 DB I/O와 외부 API의 연동 작업들의 평균 latency가 1초대라고 가정하더라도 큐에는 작업이 계속 쌓이게된다. 위에서 언급한 것 처럼, 이러한 상황들을 먼저 가정하고 접근했더라면 워커의 concurrency를 늘리는 등의 동시 처리 방법까지 자연스레 고려할 수 있었을 것 같다.
원자성 보장을 위해
메시지의 추가 I/O는 단일 테이블의 insert라고 하더라도, 업무 알림은 여러개의 테이블을 insert/update하는 연속적인 과정이다.
MyISAM은 항상 auto-commit한 쓰기 작업을 보장한다. 롤백을 무시하며 트랜잭션을 지원하는 엔진이 아니기 때문에, 이런 연속적인 과정에서 트랜잭션을 보장하기 위해서는 소위 transaction-like한 무언가를 직접 구현해야했다.
type InsertRecord = {
table: string;
id: number;
deleteFn: (id: number) => Promise<void>;
};
class JobTransactionContext {
private inserts: InsertRecord[] = [];
recordInsert(record: InsertRecord) {
this.inserts.push(record);
}
async rollback() {
for (const record of this.inserts.reverse()) {
await record.deleteFn(record.id);
}
}
}
이를 해결하기 위해 위처럼 트랜잭션 컨텍스트 객체를 사용해서, 트랜잭션을 보장해야하는 로직에 활용하게 되었다.
실패 후속 처리
워커에서 작업을 실패할 경우 원자성을 보장해야하는 경우는 실패로 간주되지만, 위에서 말했던 것 처럼 실패했을 경우에도 운영 상에 지장이 없다고 판단했던 SMS 발송과 푸시 알림은 실패로 간주되지 않는다.
위 정책에 따라 분리하여 트랜잭션이 롤백되는 상황에서만 실패로 간주하여 작업을 종료시키고, 실패 시 재시도 전략을 수립했다.
재시도는 BullMQ에서 기본으로 구현되어있는 지수 백오프(Exponential Backoff)를 사용했다.
모든 재시도에 지수 백오프만 사용할 경우 모든 실패한 작업들이 동시에 백오프 될 경우도 고려해야한다. 실패한 작업에 대해 재시도를 분산하기 위해 사용하는 전략임에도 재시도 과정에서 다시 요청이 몰리는 것은 똑같다. 이를 해결하기 위해 AWS에서는 지연 변이(Jitter)라는 개념의 추가 전략을 통해 일정의 랜덤 시간을 추가로 부여하여 재시도의 동시성을 분산했다고 한다. (자세한 내용은 AWS의 공식 포스팅1 / 포스팅2 를 참조)
추가 개선
최근에 이 내용들을 복기하면서 추가로 고려하지 못했던 사항들이 무엇이었는지, 내가 1년 반 전과 비교해서 어디까지 고려하는 개발자가 되어있었는지 확인해보고 싶었다. 위에 잠깐 언급했던 트러블 슈팅을 위한 TPS 산정을 포함해서 정리한 피드백 내용은 다음과 같다.
위에서 언급한 TPS를 조기에 산정했더라면
큐에 메시지가 계속 쌓인다면? (처리량보다 유입량이 많은 경우)
BullMQ의 심장(?)인 Redis에 장애가 발생한다면?
위 세 가지 상황이 모두 연관이 있는 것 같다. 1번을 조기에 고려하지 못해서 자연스레 2번 문제를 캐치하지 못했고, 2번 문제를 계속 방치하다보면 결국 최종에는 Redis에도 문제가 생기지 않을까? 추가 개선을 위해, BullMQ는 어떻게 Redis를 활용해서 Job을 입력하는지 알아보는 게 좋겠다.
여기서 생각해보아야할 부분은, Redis의 SET은 중복된 키값이 있다면 내부 데이터를 덮어 쓰는 방식으로 동작 한다는 점이다. 이해를 돕기 위해, 실제 Job 등록에 사용되는 여러 자료구조 중 Hashes를 직접 CLI를 통해 입력해본 결과를 아래에 서술해두었다. 결과를 보면 중복 방지를 디폴트로 수행하지 않는다는 것을 알 수 있다.
127.0.0.1:6379> HSET user-1 name test
(integer) 0
127.0.0.1:6379> HGETALL user-1
1) "name"
2) "test"
127.0.0.1:6379> HSET user-1 name test2
(integer) 0
127.0.0.1:6379> HGETALL user-1
1) "name"
2) "test2"
그렇다면 BullMQ를 사용하는 우리 개발자들은 중복 처리를 사전에 확인하는 모듈을 따로 구성해야할까? 그렇지 않다. BullMQ에서는 편의를 위해 중복된 Job은 등록이 되지 않도록 처리해두었다. 우선 BullMQ의 소스 코드를 실제로 분석해 본 후 동작 과정에 대한 간략한 플로우를 그려봤다.
Redis에 데이터를 등록하기 위해 실행되는 add....Job-*.lua 스크립트에서 입력 전 중복 확인에 대한 로직이 같이 수행된다.
else
jobId = args[2]
jobIdKey = args[1] .. jobId
if rcall("EXISTS", jobIdKey) == 1 then
return handleDuplicatedJob(jobIdKey, jobId, parentKey, parent,
parentData, parentDependenciesKey, KEYS[5], eventsKey,
maxEvents, timestamp)
end
end
추가적으로 priority나 delayed 작업을 위한 ZSET 활용, 작업 로그를 위한 Streams등에 추가로 입력하지만, 이 부분은 현재 주안점에 벗어나니 생략하겠다. 관심 있으신 분들은 BullMQ 소스코드를 참고하면 될 것 같다.
이제 이러한 이해들을 바탕으로, 추가 개선을 어떻게 해야하는지 한 번 생각해보았다.
처리량 < 유입량
우선 처리량보다 유입량이 많은 경우부터 따져보자.
워커의 처리 속도가 생산 속도를 따라가지 못할 경우 큐에는 자연스레 Job이 쌓이게 된다.
이 상황이 지속되면 메모리 부담은 물론이고(Redis) 뒤에 들어온 Job의 처리 시간은 기하급수적으로 증가하게 된다.
위의 비즈니스 흐름을 예시로 절망적인 상황을 들어보자면 고객님이 어제 채팅을 보냈는데, 담당자는 오늘 업무 알림을 받아볼 수도 있다.
큐에 작업이 원활하게 처리되지 못하는 상황을 해결하기 위해 워커에서 동시 처리량을 제어할 수 있다. TPS가 최대 1.55였기 때문에 645ms당 1개의 요청이 발생한다고 가정하고, 워커의 처리 속도는 외부 API에 의해 최대 2초가 걸린다고 가정한다면 concurrency는 3~4정도가 적당할 것이다. 이처럼 적절한 동시 처리나 워커 자체를 늘리는 방향도 고려해볼 수 있다.
하지만 동시성을 제어할 경우에는 현재 사용중인 리소스, 여기서는 데이터베이스의 총 Connection과 평균 활성 Connection, 현재 서버의 Connection Pool과 할당된 메모리 자원 등을 고려하는 것이 필수이다. 이 모든 리소스간의 밸런스를 고려하는 엔지니어링이 개발자의 필수 덕목인 것 같다.
유입량이 많은 경우 중 또 고려해야할 부분은, 처리해야할 메시지가 중복해서 들어오는 경우이다.
하지만 위의 BullMQ의 기본 Job 적재 방식에 대한 이해를 바탕으로 중복 방지에 선 조회 후 early-return하는 코드는 오히려 추가 I/O가 발생할 것이라는 것을 짐작할 수 있다.
Redis 장애 대응을 위해
근본적으로 Redis 장애 발생 시 당연히 BullMQ는 더이상 메시지를 받을 수 없다. 또한 이미 enqueued된 작업조차 Redis의 휘발성이라는 특성 때문에 손실될 수 있다.
개발자로서 이런 현상을 미리 대응할 수 있도록 설계하여 이미 enqueued된 작업을 복구할 수 있도록 구성할 수 있어야한다.
아직까지 서비스에서 사용중인 Redis에 장애가 발생한 적은 없지만, 혹시 모를 Fail Over에 대비한 전략이 하나도 구성되어있지 않다는 것을 인지했다. 서비스 도메인 특성상 트래픽이 엄청나게 성장할 일은 없다고 판단해서 Sentinel로 FailOver 시 노드 승격 전략과 장애 발생 알림 처리를 구성했다. 서비스 레벨에서 Redis 연결 재시도를 허용하여 마스터 노드 전환 시에도 워커가 자동으로 재연결되도록 처리했다.
이와 더불어 꾸준히 큐들의 작업 개수를 주기적으로 수집하여 모니터링하고 대기열이 일정 수치를 초과하면 알림을 받아볼 수 있도록 구성하여 장애 징후를 빠르게 감지할 수 있도록 했다.
마무리
당시의 개선 방향과 현재 시점에서 생각나는 추가 개선 사항들을 정리하여 쭉 정리해보았다.
점진적으로 이런저런 시도를 해보면서 현재 트래픽을 감당하기 여유로운 상황이다보니 엣지 케이스들을 또 고려하지 못했나 싶기도 하다.
조금씩 알면 알수록 더 어려운 빌어먹을 엔지니어링의 세계 ㅡㅡ.. 외부 레퍼런스들을 많이 찾아보면서 실제 개선 사례들을 대입해보면서 무엇을 놓쳤는지, 지금 방식이 최적이었는지 계속 생각해보고있다. 언젠가 이 글을 다시 꺼내먹는 날 예전의 내가 한심해질지도..?
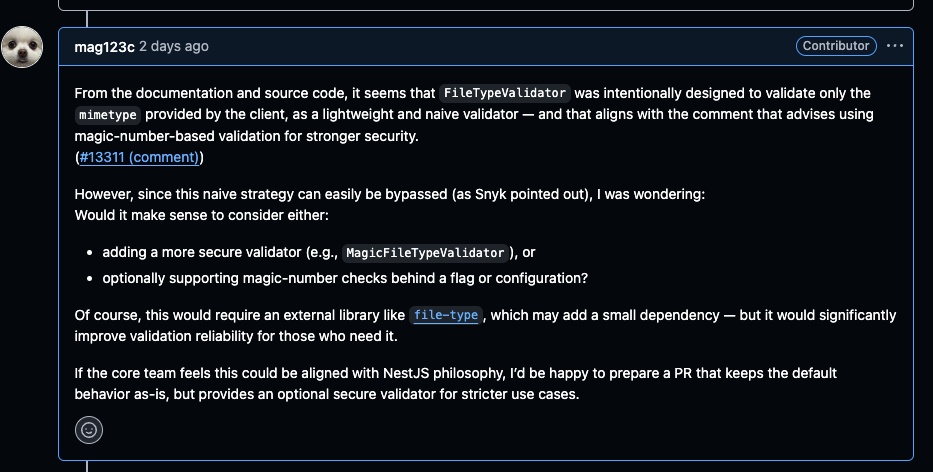
파일 검증에 대한 보안 취약점을 개선하기 위해 Nest의 FileTypeValidator에 파일의 Magic Number(바이너리 시그니처)를 기반으로 파일 타입을 검사하도록 변경되었다. 이 변경은 보안적으로 더 개선되었지만, 실제 애플리케이션에서는 다음과 같은 부작용을 낳았다.
.txt, .csv, .json등 Magic Number가 없거나 너무 짧은 파일들은 파일 타입을 판단하지 못해 업로드 실패로 이어진다. 이로 인해 기존 애플리케이션에서 잘 작동하던 업로드 로직이 갑자기 실패하게 되었다.
에러메세지가 기존과 같이 file type에 대한 에러 메세지가 나오게 되어 왜 실패했는지 알 수 없다.
위 문제를 바로 피부로 겪었는데, 현재 조직에서도 새로 구축하고 있던 애플리케이션에서 잘 동작하던 파일 업로드가 갑자기 되지 않았고, 문제를 직접 해결하기 위해 나는 유연한 검증을 위한 옵션과, 에러 메세지의 적절한 분기 처리를 PR로 제출했다.
Swagger은 OpenAPI의 표준이 아닌 확장(사용자 정의) 속성을 지원하고 있는데, SecuritySchema는 이 확장 속성들 중 API 요청을 인증할 때 어떤 방식으로 인증해야하는 지 정의하는 설정이다. Nest에서는 이 옵션을 래핑하는 DocumentBuilder을 메서드 체이닝을 이용하여 보통 아래처럼 스웨거 명세를 만든다.
하지만,OpenAPI Extensions 문서의 예시처럼, 이 API Key에 추가적인 필수 옵션들이 들어가야하는 상황이라면? 예를 들어 AWS API Gateway처럼 특정 플랫폼에 맞춘 커스텀 인증을 구현해야하는 상황에서, 스웨거를 통해서는 헤더에 원하는 커스텀 옵션을 넣을 수 없게 되어있다.
Nest의 Swagger Plugin은 컴파일 타임에 ts의 Transformer을 사용해서 Swagger 명세를 추상 구문 트리로 만들어낸다. JavaScript 엔진을 공부할 때 나오는 그 추상 구문 트리(Abstract Syntax Tree) 이다. 이렇기에 위 예제처럼 런타임 시에 정해지는 값은 추론되지 않아 JavaScript 함수의 name값인 Function을 넣어버리게 된다.
컴파일 타임에 제어하기 위해, Swagger Plugin Option을 추가하고, 옵션에 따라 아예 옵션을 활성화하면, Default로 추론할 수 없는 값들은 Swagger 명세에 Default로 추가되지 않는다.
기여를 계속 하다보니 자연스레 깨닫게 된 점이 있다. 바로 조직 내에서 사용하는 기술 스택에 익숙해져감에 따라, 그것이 나의 개발 판단 기준을 점점 좁히고 있었다는 점이다. 예를 들어, 런타임 타입 검사를 위한 Zod를 typia로 변경하여 훨씬 빠르고 간결한 코드 작성이 가능한 오픈소스도 있고, 항상 tsc로 트랜스파일하던 것을 swc로 바꿔본다던가 하는 등의 퍼포먼스 개선이 가능하다. 당장 적용해도 충분히 기술 선택의 근거가 명확하고, 임팩트가 있는 선택지들이 많다는 걸 느낀다.
오픈 소스 기여는 단지 코드 변경에 머무르지 않는다. 생태계의 흐름을 눈으로 확인하고, 직접 만지며 왜 이런 기능이 추가됐는지를 맥락과 함께 이해하는 경험이라고 생각한다. 이런 과정을 겪으며 자연스럽게 내 기술의 선택 기준도 명확해지고 조직 내 기술뿐 아니라 개인적으로 사용할 기술에도 더 많은 관심을 기울이게 된다.
내가 사용하는 기술을 불편 없이 쓰는 것에서 멈추는 것이 아니라, 더 나은 방향으로 기여하거나 기존에 없는 기능을 직접 만들어내는 것.
결국 불편함을 느끼고 나만의 방식으로 개선해보는 경험을 하나씩 쌓아나가는 것이 가장 이상적인 형태가 아닐까 싶다.
장황하게 나열했는데, 여튼 다음에는 조금 더 다양한 기여 경험을 가지고 돌아오도록 하겠다.
최근 LeetCode 등의 알고리즘, 구현 문제들을 풀면서 자료 구조를 직접 구현해보기 시작했다.
Heap에 대한 개념은 어느정도 있었다고 생각했는데, 막상 구현하려고 보니 입력, 삭제 시 어떻게 정렬을 보장할 수 있지? 에서 멈칫했다. 생각을 정리하고 코드를 짜보려 했지만, 선뜻 키보드에 손이 가지 않아 정리하는 마음으로 이 포스팅을 작성하게 되었다.
힙(Heap)
힙은 트리 기반의 자료구조이며, 반드시 부모노드와 자식 노드 사이에는 대소 관계가 성립해야한다는 규칙이 있다.
출처: 나무위키 - 힙
힙에는 규칙에 따라 최소 힙(Min Heap), 최대 힙(Max Heap)이 있으며, 위 대소관계에 따라 부모 노드가 자식 노드보다 작다면 최소 힙, 반대의 경우는 최대 힙이라 부른다. 이 대소 관계는 반드시 부모 노드와 자식 노드 간에만 성립하며, 형제 사이에서는 대소 관계가 정해지지 않는다.
일반적으로 힙이라고 하면, 완전 이진 트리(Complete Binary Tree) 기반의 Binary Heap을 의미한다. 완전 이진 트리란 이진 트리를 만족하면서, 모든 레벨이 왼쪽에서부터 차례대로 채워진 트리 구조를 말한다. 자식이 세 개 이상인 D-ary Heap이나, 비정형 트리를 사용하는 Fibonacci Heap 등 다양한 힙이 있지만, 이 포스팅에서는 일반적인 힙을 다룬다.
다시 돌아와서, 힙은 데이터를 꺼낼 때 항상 루트 노드에서 데이터를 꺼내는 방식으로 동작한다. 위의 특징들과 더해 유추해보면 최소값 최대값을 조회하는 데 O(1)의 시간이 걸린다. 그래서 주로 최소값이나 최대값을 빠르게 얻기 위해 사용된다. 선형 구조에서는 최소값 최대값을 얻기 위해 기본적으로 O(N)의 시간이 필요하다. 최적화된 탐색 알고리즘을 사용하더라도 O(logN)이다.
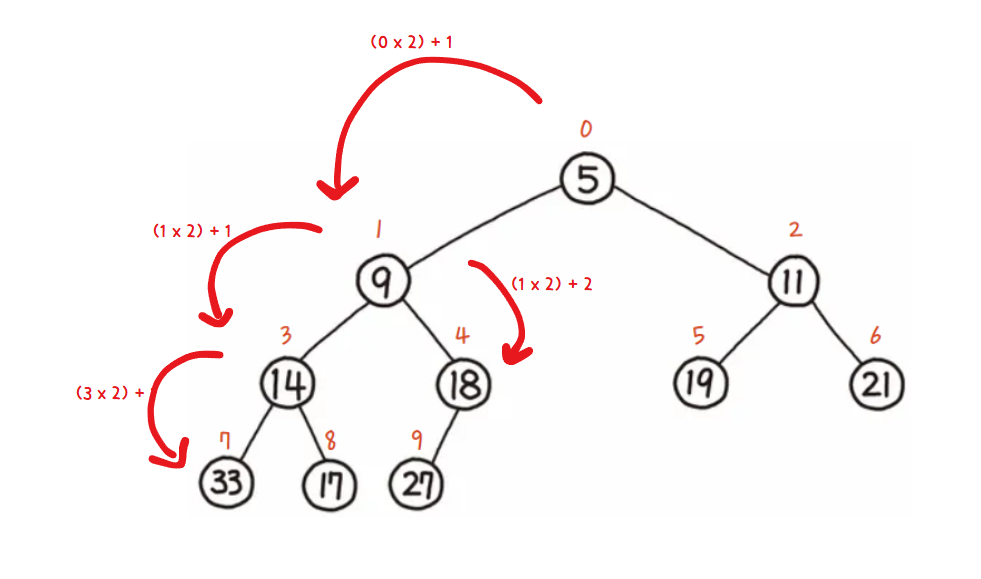
구현하기 전 마지막으로 알아야할 것이 있다. 위에서 언급한 일반적인 힙인 Binary Heap은 이진 트리 구조임에도 불구하고 배열로 구현할 수가 있다. 자식 노드들의 인덱스나 부모 노드의 인덱스를 구하는 명확한 규칙이 존재하기 때문이다. 이해가 쉽게 그림으로 표현해보았다. 아래 그림은, 배열을 트리 형태의 그림으로 표현한 것이기 때문에 size가 아니라 index임을 알아두자.
우리는 위 그림에서, 다음과 같은 규칙을 유추할 수 있다. 아래의 규칙을 인지하고 힙을 구현해보자.
왼쪽 자식 노드 인덱스 = 부모 노드 인덱스 * 2 + 1 오른쪽 자식 노드 인덱스 = 부모 노드 인덱스 * 2 + 2 부모 노드 인덱스 = (자식 노드 인덱스 - 1) / 2
구현하기
1. 기본 구조
위에서 언급한 것 처럼, 배열을 사용한 트리 형태의 기본적인 구조를 만들었다. 기본적인 메서드들과 함께 힙 정렬 과정에서 자주 사용되는 요소 교환 함수를 swap이라는 이름으로 구현했다.
여기서 Comparator 콜백을 필드로 사용한 이유는, Java의 Comparator 인터페이스에서 영감을 받아, 나중에 PriorityQueue를 구현할 때에 선택적으로 우선순위 정렬을 변경하기 위함이다. 선언 시에 선택적으로 결정할 수 있기 때문에 조금 더 활용하기 용이하다고 생각했다.
// Java
PriorityQueue<Integer> pq = new PriorityQueue<Integer>();
PriorityQueue<Integer> pq = new PriorityQueue<Integer>(Collections.reverseOrder());
// TS
const minHeap = new Heap<number>((a, b) => a - b);
const maxHeap = new Heap<number>((a, b) => b - a);
class PriorityQueue<T> extends Heap<T> {}
const pq = new PriorityQueue<number>((a, b) => a - b);
2. 삽입과 삭제
기본적인 insert와 remove를 구현했다. remove에서 T | null을 반환하는 것은 Stack이나 Queue의 pop, poll에서 착안했다.
insert와 remove를 구현할 때, heapify라는 함수를 사용한다. heapify을 직역하면 heap 형태로 바꾸겠다 라는 의미이다. 즉 삽입과 삭제에서 heap처럼 정렬하겠다는 의미라고 이해하면 된다. 재정렬을 위해 삽입 시에는 위로(Up), 삭제 시에는 아래(Down)으로 바라보며 정렬을 수행하게 된다.
remove에서 swap을 먼저 호출하는 이유는, 배열의 pop이 항상 마지막 요소를 삭제하기 때문이다. 위에서 언급한 것 처럼 힙에서 데이터를 꺼낼 때는 항상 루트 노드를 꺼내야하기 때문에, 먼저 swap을 수행한 후 pop으로 루트를 제거하는 방식을 사용한다. 이후 변경된 루트를 기준으로 heapify를 수행한다.
3. Heapify
private heapifyUp(): void {
let index = this.heap.length - 1;
while (
Math.floor((index - 1) / 2) >= 0 && // 부모 노드가 존재할 때
this.comparator(
this.heap[Math.floor((index - 1) / 2)],
this.heap[index]
) > 0 // 부모 노드가 현재 노드보다 우선 순위가 낮을 경우
) {
this.swap(Math.floor((index - 1) / 2), index); // 부모와 교환하며
index = Math.floor((index - 1) / 2); // 인덱스를 부모로 갱신함
}
}
private heapifyDown(): void {
let index = 0;
// 왼쪽 자식 노드가 존재하는 동안 (완전 이진 트리의 특성 상 왼쪽이 먼저)
while (index * 2 + 1 < this.heap.length) {
let smallerChildIndex = index * 2 + 1;
// 오른쪽 자식도 존재하고 오른쪽이 더 우선순위가 높다면
if (
index * 2 + 2 < this.heap.length &&
this.comparator(this.heap[index * 2 + 2], this.heap[index * 2 + 1]) < 0
) {
smallerChildIndex = index * 2 + 2; // 오른쪽 자식을 선택하고
}
// 현재 노드가 자식 노드보다 우선순위가 높다면 중단함
if (this.comparator(this.heap[index], this.heap[smallerChildIndex]) < 0) {
break;
}
this.swap(index, smallerChildIndex); // 자식과 교환하며
index = smallerChildIndex; // 다음 탐색 위치로 갱신함
}
}
insert에서 사용하는 heapify는 마지막 index에 삽입되기 때문에, 상향식을 통해 부모 노드와 계속 우선순위를 비교하여 정렬을 수행한다. 반대로 remove는 하향식을 통해 제거된 루트 노드의 위치에서부터 자식 노드와 계속 비교하며 정렬을 수행하게 된다. 즉, 삽입은 자식이 부모를 향해 올라가며 정렬하고, 삭제는 부모가 자식을 향해 내려가며 정렬하는 형태이다.
기본적으로 JavaScript는 고수준의 언어이다. 변수, 함수, 객체 등을 만들때 JavaScript 엔진(V8 등)은 자동으로 메모리를 할당(Allocate)하고, 더 이상 필요로 하지 않을 때 가비지 컬렉션에 의해 않을때 자동으로 해제된다. 그래서 메모리의 생명주기를 얘기할 때 할당(allocate)한다 > 사용(use, references)한다 > 해제(release)의 흐름으로 표현한다.
메모리는 JavaScript 엔진의 힙(Memory Heap)과 스택(Call Stack)에 저장된다. 힙과 스택은 JavaScript이 서로 다른 목적으로 사용하는 데이터의 구조이다.
스택(Stack)
스택은 함수가 호출될 때마다 생성되는 실행 컨텍스트(Execution Context)와 원시 타입 값이 저장되는 영역이다. 여기에는 객체나 함수를 가리키는 참조 주소를 포함한다.
(이 포스팅에서는 렉시컬 환경에 대한 개념 설명을 포함하지 않는다.)
JavaScript는 동적 타입 언어이지만, 엔진은 원시 타입 값들의 크기와 수명에 대한 예측이 가능하다.
원시 타입은 구조가 단순하고, 내부적으로 고정된 포맷으로 저장된다. 예를 들어, number은 대부분 IEEE 754표준의 64비트 부동소수점 형식을 따르며, boolean은 보통 1바이트로 표현된다.
또한 원시 타입은 대부분 함수 내부에서 선언되며, 함수가 종료되면 해당 스택 프레임과 함께 자동으로 해제된다. 객체처럼 여러 참조가 동일한 메모리를 공유하지 않기 때문에, 값의 수명 역시 명확하게 예측 가능하다.
이러한 여러 값들은 LIFO인 콜 스택에 저장하여 빠르고 효율적인 접근이 가능하도록 설계되어 있다.
스택은 연속된 메모리 공간을 사용하므로 CPU 캐시 적중률이 높고, 값의 스코프가 명확하여 GC의 개입 없이도 메모리 해제가 자동으로 이루어진다. 단, 브라우저나 JS 엔진마다 스택의 최대 크기와 내부 구현은 다를 수 있다.
힙(Heap)
힙은 JavaScript의 객체, 함수를 저장하는 또다른 공간이다. 스택과 달리 예측이 불가능하기 때문에 동적 메모리를 할당한다. 런타임시에 동적 데이터들이 메모리를 할당받아서 저장되게된다.
원시 값이 아닌 경우 스택에서는 힙의 객체에 대한 참조(References)를 저장한다. 참조는 일종의 메모리 주소라고 생각하는 것이 편하게 접근이 가능하다. 다시 정리하면, 힙에서 새 객체가 생성되고 스택에는 참조가 생성된다.
JavaScript의 메모리 구조에서 가장 큰 부분을 차지하는 힙 메모리는, 여러 공간들로 나뉘어 관리되는데 V8에서는 New space, Old space로 나뉘어 관리된다.
New space: 새로 생성된 객체가 저장되는 영역이다. 객체가 자주 생성되고 삭제되는 애플리케이션의 특성상 빠르고 효율적인 가비지 컬렉션이 가능하도록 설계되어있다.
Old space: New space에서 가비지 컬렉션의 대상이 되지 않은 오래된 객체가 저장되는 영역이다. 이 영역의 객체들은 비교적 수명이 길고 New space보다 가비지 컬렉션이 덜 수행된다.
가비지 컬렉션과 메모리 해제
가비지 컬렉션은 New space와 Old space에서 다른 방식으로 동작한다. 위에서 잠깐 언급했듯이 각 영역 별로 최적화된 minor, major GC로 관리한다. New space는 객체 생명 주기가 짧아 빠르게 가비지 컬렉션을 수행하고, 수명이 길고 메모리 사이즈가 큰 Old space는 major GC가 가비지 컬렉션을 수행한다.
minor GC (Scavenger)
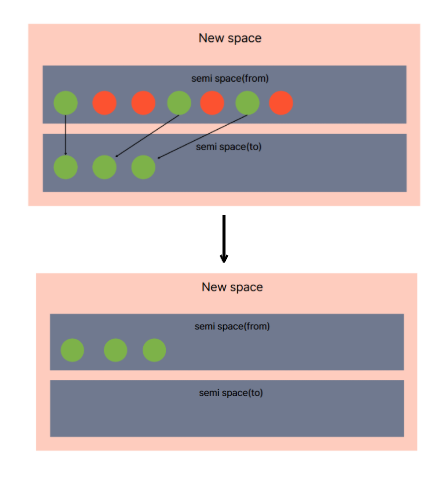
minor GC는 New space의 가비지 컬렉션을 담당하는 GC이다. New space는 두 개의 semi space로 관리되는데, 객체들이 머무르는 영역은 From space라 부르며 GC의 대상이 되지 않은 객체들이 잠시 머무르는 영역을 to space라 부른다.
to space는 GC가 동작하지 않을 때는 비어있는 상태로 시작한다. from space에 있는 객체들 중 살아남은 객체들만 to space로 복사하고, 그 후 from space는 초기화된다. 복사가 완료되면 to space는 새로운 from space로 전환되고, 초기화된 이전 from space는 다음 GC를 위한 to space가 된다. 이러한 단순한 복사 + 전체 초기화 매커니즘 덕에 minor GC는 최적화된 빠른 가비지 컬렉션을 수행할 수 있다.
JavaScript는 특성상 짧은 생명 주기를 가진 객체가 매우 많다. 콜백, 클로저, 이벤트 핸들러 등의 실행 흐름은 순간적으로 많은 객체를 만들고 금방 사라지게 만든다. 이런 특성 때문에 V8은 Scavenge 기반의 minor GC 전략을 통해 효율적으로 메모리를 관리할 수 있다.
단, 객체가 여러 번 minor GC를 거쳐 살아남게 되면, 이제 더 이상 short-lived하지 않다고 판단되어 Old Space로 승격된다. 이때부터는 Mark-and-Sweep 방식의 major GC가 동작하게 된다.
major GC
major GC는 오래 살아남은 객체들(Old space)에 대해 더이상 참조되지 않는 더이상 쓸모없는 객체로 간주한다.
Mark-Sweep-Compact, Tri-color 알고리즘을 사용해 도달할 수 없는 객체를 제거하거나 메모리를 압축한다.
마킹(Mark)
GC Roots라는 전역 객체, 실행 중인 함수, 클로저 등을 담고있는 곳에서 출발하여 도달 가능한 객체(Reachable)을 전부 dfs로 순회하면서 마킹을 한다. 루트에서 닿을 수 없는 객체는 마킹되지 않고 GC의 대상이 된다.
1. 루트 객체(Roots) 수집 및 마킹 시작
GC가 시작되면 deque 구조의 marking worklist와 tri-color알고리즘을 활용하여 마킹을 수행한다.
초기에는 marking worklist가 비어있고, 모든 객체는 white 상태이다. 이후 Roots는 바로 grey상태가 되어 marking worklist에 삽입(push front) 다.
white(00): 아직 탐색되지 않은 객체
grey(10): 발견됐지만 아직 내부 탐색되지 않음 (작업 대기중)
black(11): 완전히 마킹 완료된 객체 (내부 필드까지 탐색 완료)
Roots를 gray로 marking
2. worklist에서 꺼낸(pop front) 객체를 black으로 마킹한다.
꺼낸 객체가 참조하는 모든 필드를 따라가면서 새롭게 참조되는 white 객체들을 gray로 마킹하며 worklist에 추가한다. 이 때, white인 객체만 push front하며 이미 방문된 객체들은 worklist에 추가하지 않는다.
gray를 꺼내어 marking하는 과정
3. 모두 black이 되거나 white가 될 때 까지 위 과정을 반복한다.
마킹되지 않은 대상인 white 객체들은 GC의 대상으로 정리(sweep)된다.
dfs를 통한 순회
마킹 과정은, 객체 간의 참조 그래프를 DFS를 통해 순회하여 이루어진다. 이 때, 중요한 점은 탐색 중인 객체 그래프가 외부에 의해 변경되지 않아야 한다는 점이다. 만약 마킹 도중 애플리케이션이 동작하면서 객체 간 참조가 추가되거나 삭제된다면, GC는 이미 탐색을 마친 객체를 놓치거나 이미 삭제된 참조를 따라가며 잘못된 객체를 가지고 있는 등의 문제가 발생할 수 있다. 이는 곧 살아있는 객체를 실수로 마킹하지 않거나 불필요한 객체를 마킹하는 등 심각한 오류로 이어질 수 있다.
GC가 객체 그래프 전체를 안전하게 순회할 수 있도록 보장하기 위해서 마킹 단계에서 애플리케이션을 일시 중단(stop-the-world)시킨다. 이를 통해 객체 간 관계를 고정시켜 DFS를 안정적으로 수행할 수 있다.
GC가 동작할 때 애플리케이션은 잠시 멈춘다.
다만, stop-the-world는 앱의 응답성에 직접적인 영향을 주기 때문에, V8은 Parallel, Incremental Marking, Concurrent Marking과 같은 기술을 도입해 정지 시간을 최소화하면서도 객체 그래프의 정합성을 유지할 수 있는 방식을 사용하고 있다.
Parallel: 메인 스레드와 헬퍼 스레드가 거의 같은 양의 작업을 동시에 수행하는 방식이다. 총 일시 정지 시간은 스레드 수에 반비례하여 애플리케이션 중지 시간이 대폭 단축된다.
Incremental: 메인 스레드가 적은 양의 작업을 간헐적으로 수행한다. 메인 스레드에서 GC에 소요되는 시간을 줄이지 않고 분산시키는 방식으로 메인 스레드의 stop-the-world 시간을 줄일 수 있다.
Concurrent: 메인 스레드는 GC 작업을 수행하지 않고, 헬퍼 스레드가 백그라운드에서 GC를 100% 수행한다. JavaScript의 힙이 언제든지 변경될 수 있고, 동시성 문제가 있으므로 읽기/쓰기 경쟁에서 자유롭지 못하다. 메인 스레드의 stop-the-world는 0에 수렴하지만, 헬퍼 스레드와의 동시성 동기화 문제 때문에 약간의 오버헤드가 있다.
Parallel
Incremental Marking
Concurrent Marking
스위핑(Sweeping)
white으로 마킹된 객체는 도달 가능하지 못한 대상(Unreachable)으로 판단하여 정리 대상이 된다. 이 객체들의 메모리 주소를 free list에 추가한다. 여기서 free list란 linked list 구조로 동적 메모리 할당을 위해 사용되는 자료구조이다.
V8은 힙에서 무조건 새로운 메모리를 요청하지 않고, free list에 있는 빈 슬롯을 먼저 조회해서 해당 메모리 주소를 재사용하게 된다.
압축(Compact)
GC가 끝난 후 힙 메모리 내부에 여기저기 흩어지게 되는데, 이를 메모리 단편화라고 한다.
메모리 단편화가 심할 경우에만 조건적으로 compact를 수행한다.
마무리
포스팅을 정리하면서 파편화된 지식을 압축(Compact)하여 내가 면접 질문에서 서론과 같은 질문을 받았을 때에 대처할 수 있도록 압축한 내용을 다시 메모리(?)에 올려놓고 마무리한다.
스택은 구조상 크기와 수명이 명확한 값들을 저장하기에 적합하며, 특히 선형적인 구조로 인해 관리가 빠르다. 하지만 무한정 커질 수 있다고 해도 스택의 선형적인 구조가 객체 참조와 같은 동적 패턴을 효율적으로 처리할 수 있을지는 의문이다.
힙은 런타임 중에 크기가 가변적이며, 현재로서는 참조 기반 객체 데이터가 저장되는 유일한 구조이다. 만약 참조 기반 데이터를 스택에 담는다면, 스택에 담을 수는 있겠지만 객체 간 참조를 효율적으로 관리할 수 없고 결국 연속적인 메모리 탐색이 필요하며 최악에는 모든 메모리에 대한 탐색이 필요할 수도 있다. 사과 하나를 꺼내기 위해 냉장고에 있는 모든 음식들을 꺼내는 것 처럼 말이다.
즉, 아무리 스택의 스펙이 좋아진다고 하더라도 힙의 역할을 구조적으로 대체할 수 없다고 생각한다.
현재 내 백엔드 스택과 연관되어 JavaScript와 연계된 꼬리질문이 이어진다면
V8은 GC 최적화(Minor/Major GC와 구현된 알고리즘)를 통해 힙 메모리의 파편화 문제를 실질적으로 해결하고 있다.
물론 스택 메모리 자체도 V8 내부 최적화(Inlining, Espace Analysis)를 통해 더 빠르게 동작하도록 설계되어 있다. 다만 동적 객체의 수명 주기를 다루는 영역에서 힙은 여전히 핵심적인 역할이다.
1. NestJS의 내장 FileValidator은 파일 내용을 확인하지 않고 MIME Type만 정규 표현식으로 확인한다. (주석에도 언급되어 있다.)
2. 프로젝트를 구성하는 많은 파이프라인들 중 일부 요소들에서 (Snyk, GitHub Dependabot 등) 보안 취약점이라고 알림이 발생한다. 심할 경우 파이프라인이 제대로 동작하지 않는다.
3. 만약 NestJS에서 수정해야할 경우를 가정하고 작성한 포스팅이다. (파이프라인의 보안 취약점 수정 요청 등을 가정하지 않는다.)
서론
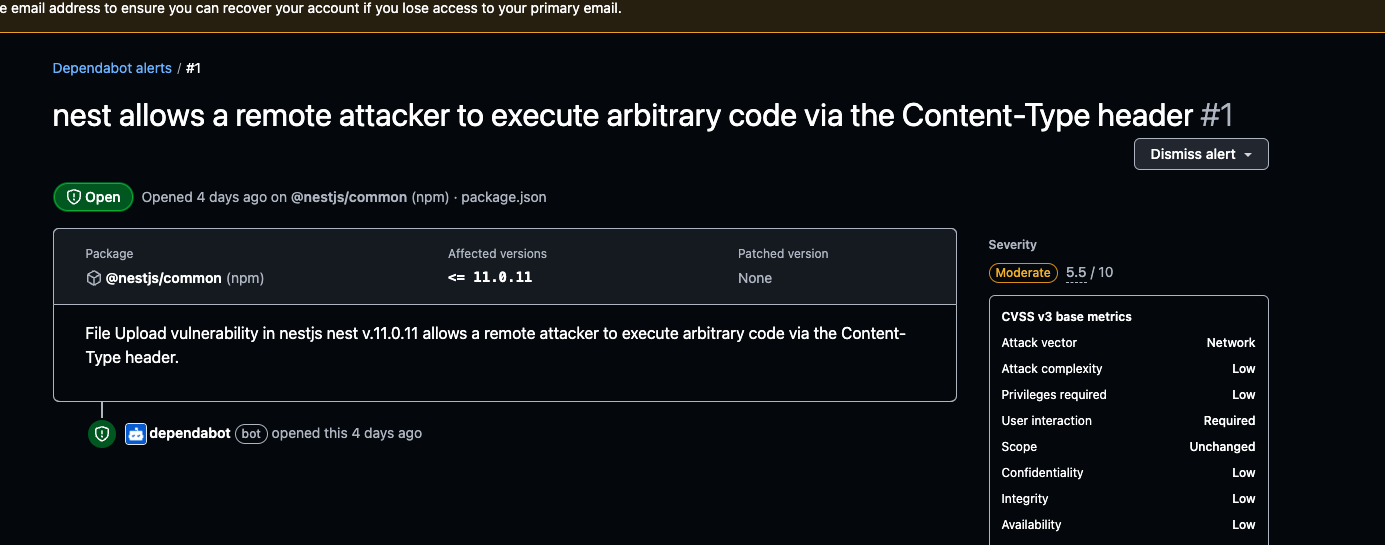
Affected versions of this package are vulnerable to Arbitrary Code Injection via the FileTypeValidator function due to improper MIME Type Validation. An attacker can execute arbitrary code by sending a crafted payload in the Content-Type header of a request.
최근에, NestJS에 제기됐던 FileTypeValidation의 보안 취약점 이슈가 대두되었다. MIME Type을 임의로 주입했을 때 검증할 수 없다는 내용이다.
/**
* Defines the built-in FileType File Validator. It validates incoming files mime-type
* matching a string or a regular expression. Note that this validator uses a naive strategy
* to check the mime-type and could be fooled if the client provided a file with renamed extension.
* (for instance, renaming a 'malicious.bat' to 'malicious.jpeg'). To handle such security issues
* with more reliability, consider checking against the file's [magic-numbers](https://en.wikipedia.org/wiki/Magic_number_%28programming%29)
*
* @see [File Validators](https://docs.nestjs.com/techniques/file-upload#validators)
*/
export class FileTypeValidator extends FileValidator<
FileTypeValidatorOptions,
IFile
> {
buildErrorMessage(file?: IFile): string {
if (file?.mimetype) {
return `Validation failed (current file type is ${file.mimetype}, expected type is ${this.validationOptions.fileType})`;
}
return `Validation failed (expected type is ${this.validationOptions.fileType})`;
}
isValid(file?: IFile): boolean {
if (!this.validationOptions) {
return true;
}
return (
!!file &&
'mimetype' in file &&
!!file.mimetype.match(this.validationOptions.fileType)
);
}
(예를 들어, 'malicious.bat'을 'malicious.jpeg'로 이름을 바꾸는 것입니다). 이러한 보안 문제를 해결하기 위해 더 신뢰성 있게 파일의 [magic-numbers] 을 확인해 보세요
import { FileTypeValidator, MaxFileSizeValidator, ParseFilePipe, UploadedFile } from '@nestjs/common';
export function CustomImageValidator(
maxSize: number = 1024 * 1024 * 15 + 1,
// application\/x-msdownload 추가
fileType: RegExp = /^(image\/jpg|image\/jpeg|image\/png|image\/gif|image\/bmp
|image\/svg\+xml|application\/x-msdownload)$/i,
) {
return UploadedFile(
new ParseFilePipe({
validators: [
new MaxFileSizeValidator({ maxSize }),
new FileTypeValidator({ fileType }),
],
}),
);
}
// 파일 업로드 시 Content-Type 조작
const fakeFile = new File([file], file.name, {
type: "application/x-msdownload", // .exe MIME
});
테스트를 위해 간단하게 프로필 이미지 업로드 코드를 만들고, 실제로 클라이언트에서 Content-Type을 조작한 뒤 파일을 업로드하게되면, 서버에 파일이 올바르게(?) 전달되게 되고 뒤 프로세스들이 그대로 실행되는 모습을 볼 수 있었다.
그래서 뭐가 문제임?
그렇다면 이게 왜, 어떤 문제가 되어 보안 취약점이라고 계속해서 말하는걸까?
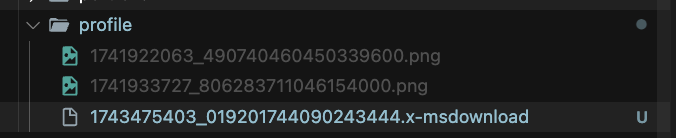
실제로 업로드된 파일의 내용을 보면, 파일은 PNG 이미지이지만, MIME Type은 application/x-msdownload로 설정되어 있었다.
서버는 이 MIME Type을 믿고 x-msdownload 확장자로 저장했고, 앞의 벨리데이션을 통과했기 때문에 이후 로직에서도 별다른 제약 없이 이 파일을 처리하게 된다.
서버는 신뢰할 수 없는 Content-Type값을 기준으로 벨리데이션을 처리했다. NestJS의 FileTypeValidator은 정의한 정규표현식을 통해서 파일의 타입을 단순 문자열 비교만 수행한다. 이 문자열 타입은 클라이언트에서 조작이 가능하므로 기본적으로 취약한 구조가 된다.
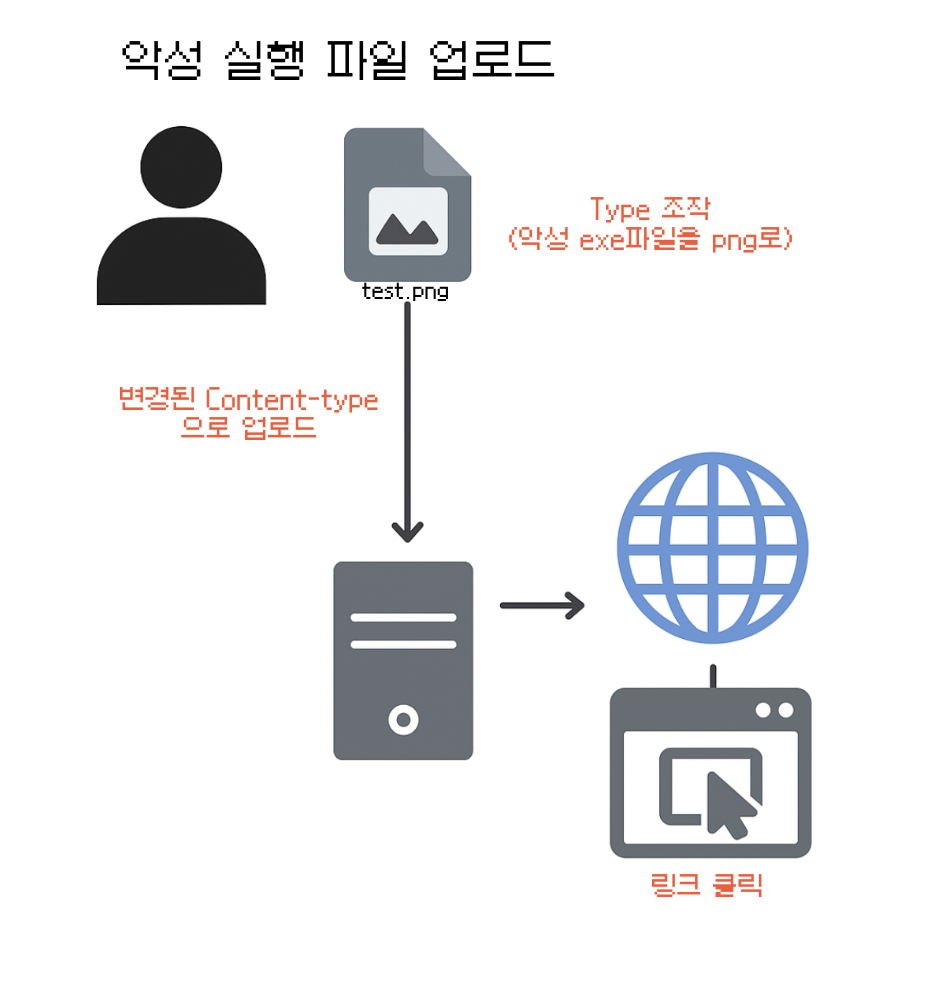
가상의 시나리오를 하나 구성해보았다. 공격자가 악성 실행 파일을 png인 것으로 인식하게끔 Content-Type만 위변조하여 업로드하였다. 나는 올바르게 ImageValidation Type을 설정했지만 서버 내부의 FileTypeValidator은 PNG로 인식하기 때문에 올바르게 벨리데이션을 통과하게 되며 이는 곧 서버와의 상호작용을 통해 어딘가 저장됨을 의미한다.
저장된 이 파일이 사용자에 의해 다시 실행되게 되면?? XSS, RCE(Remote Code Execution)등의 취약점이 발생하게 된다.
이 문제의 본질은, 계속 강조했던 것 처럼 서버가 신뢰할 수 없는 Content-Type값을 기준으로 벨리데이션을 수행하기 때문에 발생하는 문제이다. 이 MIME Type은 클라이언트가 조작이 가능하기 때문에 신뢰할 수 없다. NestJS에서는 이러한 MIME Type에 대한 정규표현식 검증만 수행하기 때문에 취약한 구조일 수 밖에 없다.
어떻게 개선할까?
이 문제를 해결하기 위해서는, Content-Type에 의존하는 것이 아닌, 파일의 실제 내용을 기반으로 판단해야한다.
파일 바이너리의 시작 부분에는 파일 형식을 식별하는 시그니처(Magic Numbers)가 들어있다. 예를들어 JPEG 이미지는 0xFFD8로 시작하고, PNG는 항상 0x89504E47로 시작한다. 매직 넘버는 파일의 형식을 정확하게 식별하는데 이미 널리 사용되고 있다.
이 문제를 처음 접했을 때 NestJS에서 작성 해 놓은 주석을 기반으로 나도 Magic Number을 사용할 수 있도록 개선하고자 했다. FileValidator라는 공통 인터페이스가 있으니, FileMagicTypeValidator같은 것을 확장해서 구현하려고 방향성을 정한 뒤 PR을 작성하기 전 NestJS의 개발 방향과 일치하는지 이슈 코멘트에 방향성을 재확인받고자 코멘트를 작성했다.
하지만 다른 누군가가 바로 PR을 올려버렸기 때문에 아쉽지만 기여에는 실패한 것 같다.
NestJS의 기존 의존성들에는, 이러한 파일 벨리데이션을 해결해줄 수 있는 라이브러리가 존재하지 않기 때문에, Node 진영에서 가장 많이 쓰이는 라이브러리 중 하나인 file-type을 사용하여 해결하고자 했다.
이미지 파일의 경우 - 이미지 변환, 리사이징 등을 통해 정말 이미지 파일이 맞는지 검증해보기
등의 추가 개선을 자체 서버에서 구현할 수도 있지 않을까? 라는 생각을 해본다.
마무리하며
우선, 오픈소스 PR은 올린 사람이 임자(?) 라는 것을 다시금 깨닫는다. 간만에 기여할 거리가 생겼는데 엄청 아쉽다.
이번 이슈는 단순히 NestJS에 보안 취약점이 있다. 라는 수준을 넘어서, 서버 사이드에서 클라이언트 입력값을 얼마나 신중하게 다뤄야하는지를 조금이나마 일깨워줬다. MIME Type은 단순히 HTTP 요청에 포함된 단순한 문자열일 뿐이고, 이를 신뢰할 경우 우리는 의도치 않게 악성 파일을 통과시킬 수도 있다.
NestJS에서도 이를 사전에 인지했기 때문에 주석을 통해 명시적으로 사용자들에게 알렸다. 결국 중요한 건 사용자 개개인이 어느 수준까지 보안을 신경쓰고 코드를 작성할까? 라는 인지를 하고 코드를 써내려가는 것 아닐까?
Redis Client 모듈을 직접 만들고 NPM에 배포하기 (NestJS + ioredis)
OpenSource2025. 3. 6. 20:30
728x90
728x90
동기
패키지 설치 시 경고 문구가 나오는 것을 정말 싫어한다. 새로운 서버 구축을 위해 Nest에서 기존에 사용하던 redis 모듈 오픈소스를 자연스레 설치했는데, 위와 같은 경고 문구가 발생했다. 경고에 따르면 이 오픈소스에서 terminus를 사용하는데, terminus의 의존성 버전들이 나의 현재 프로젝트 버전과 맞지 않는다고 한다.
terminus?
terminus를 간략히 설명하자면 NestJS에서 Health Check를 제공하는 모듈이다. 다양한 Health Indicator로 특히 마이크로서비스나 인프라등 애플리케이션의 기능들이 정상적으로 동작하는지 확인하는 기능을 제공하는 모듈이다. 단순 Redis Client Module에서 필요한 것은 아니라는 생각이 들었고, 위의 warning 의존성 문구와 더불어 이런 이유들로 인해 직접 NestJS의 11버전과 호환되는 모듈을 직접 만들어 배포하기로 했다.
NestJS의 DynamicModule은 동적으로 옵션을 받아서 런타임에 원하는 모듈을 구성할 수 있다. 물론 StaticModule 역시 런타임의 환경 변수 값 등의 변동에 따른 동적인 모듈 세팅을 할 수 있으나, 아래처럼 Redis를 상황에 따라 클러스터 모드로 모듈을 구성해야하는 경우, 극단적으로 외부 API 호출 값에 따라 변동되는 모듈 세팅 등 실행 환경에 따라 모듈 내부의 Providers 등을 다르게 주입해야한다면 StaticModule로는 불가능하다. (Nest에는 TypeOrmModule, ConfigModule 등 다양한 곳에 DynamicModule이 사용되고 있다.)
(Nest에는 TypeOrmModule, ConfigModule 등 다양한 곳에 DynamicModule이 사용되고 있다.)
라이브러리를 만들어보기 전에, 코어가 되는 의존성인 ioredis에 대해 먼저 확인해보아야했다.
ioredis란 Node 진영에서 많이 사용되는 Redis Client이다. 내부를 뜯어보니 내가 사용하고자하는 단일 레디스와 더불어 엄청나게 많은 기능을 제공하고 있었다. 우선 만들고자 하는 모듈이 ioredis에 의존적일 수 밖에 없어서, 혹시 직접 Redis Client를 직접 만들 수도 있을까 하고 연결 과정을 살펴보게 되었다.
확인해 본 결과 기본적으로 Node의 net 모듈을 통해 L4 연결을 수립하고 있었고, 필요 시 TLS Handshake가 추가 수립되었다. 추상커넥터를 통해서 단일 Redis와 센티넬 Redis를 자동으로 감지하여 연결을 수립시켜주고 있었다.
차후에 Node의 net 모듈을 통해 OS의 소켓 API를 직접 사용해보면서 레디스에 직접 연결해서 사용해보고, 필요한 기능들만 래핑해서 사용해보면 좋을 것 같았다. 이 부분은 차후에 개발 후 추가 포스팅으로 연계하려고 한다.
Redis Dynamic Module 만들기
위에서 언급한 DynamicModule을 바탕으로 실제 Redis와 연결하는 Dynamic Module을 구현해보았다.
NestJS의 DynamicModule 컨셉에 맞게 동기, 비동기 옵션 주입을 모두 지원하며 Redis 연결을 담당하는 Provider와 옵션을 useValue로 넣어주는 Provider을 분리하여 제작하였다.
모듈 생성과 Providers 주입 등에 사용될 인터페이스를 정의하고, Redis Connection 전용 Provider을 생성했다. RedisProvider을 통해 내가 레디스 클라이언트까지 생각하지 않고 옵션만 원하는 데로 넣어서 사용할 수 있게 유도했다.
// redis.factory.ts
import Redis from 'ioredis';
import { RedisModuleOptions } from './redis.interface';
export async function createRedisClient(options: RedisModuleOptions) {
const { type, commonOptions } = options;
if (type === 'cluster') {
return new Redis.Cluster(options.nodes, commonOptions);
}
if (type === 'single') {
return new Redis(options);
}
throw new Error('Invalid Redis options');
}
현재 개발 환경에서 레디스 클러스터를 사용할 일이 없어 만들지 않으려다가 ioredis에서 Cluster 인스턴스를 만들어서 Redis node별 host, port만 넣으면 되는 것을 확인하여 간단하게 작업이 될 수 있을 것 같아 클러스터 환경의 레디스 클라이언트도 추가해두었다. 이렇게 추가해도 실제 사용하는 레디스 인스턴스는 ioredis의 Redis Client이기 때문에 무리없이 사용이 가능하다.
(하지만 실제 사용하는 환경이 아니다보니 테스트 코드는 작성하지 않았다.)
import { Inject } from '@nestjs/common';
import { REDIS_CLIENT } from './redis.constasnts';
export const InjectRedis = () => Inject(REDIS_CLIENT);
마지막으로, Redis Client를 특정 모듈들에서 주입받아 원하는 구간에서 사용할 수 있도록 주입을 위한 데코레이터를 만들었다. 이제 아래처럼 다른 Providers에서 Redis Module을 통해 생성된 Redis Client를 사용할 수 있다.
import { Injectable } from '@nestjs/common';
import { InjectRedis } from './redis.decorator';
import Redis from 'ioredis';
@Injectable()
export class RedisService {
constructor(@InjectRedis() private readonly redis: Redis) {}
async getValue(key: string): Promise<string | null> {
return this.redis.get(key);
}
}
이 @InjectRedis()는 강제로 REDIS_CLIENT 상수를 넣어두었다. 내가 여러 대의 레디스를 사용하게 되거나, 누군가의 요청으로 인해 변경해야 한다면 상수 대신 옵션으로 넣고 옵션으로 들어온 값이 없다면 디폴트로 사용할 수 있게 구성할 생각이다.
실제 적용해보기
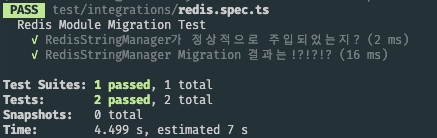
지금까지 만든 라이브러리를 NPM에 배포하고 새로 구축하고 있던 서버에서 기존 오픈소스를 제거한 뒤 내가 만든 라이브러리를 주입시켜보았다.
import { Test } from "@nestjs/testing";
import { RedisStringManager } from "../../src/infra/redis/managers/string.manager";
import { CustomRedisModule } from "../../src/infra/redis/redis.module";
import { setupApp, setupModule } from "../settings/setup";
describe('Redis Module Migration Test', () => {
let redisStringManager: RedisStringManager;
beforeAll(async () => {
const moduleRef = await setupModule([CustomRedisModule]);
redisStringManager = moduleRef.get<RedisStringManager>(RedisStringManager);
})
it ('RedisStringManager가 정상적으로 주입되었는지?', () => {
expect(redisStringManager).toBeDefined();
});
it ('RedisStringManager Migration 결과는!?!?!?', async () => {
await redisStringManager.set('test', 'test');
const sut = await redisStringManager.get('test');
expect(sut).toBe('test');
});
});
import { CustomRedisModule } from '../../src/infra/redis/redis.module';
import { setupModule } from '../settings/setup';
import { RedisAuthStore } from '../../src/app/auth/services/redis-auth-store';
describe('AuthModule Redis 연동 테스트', () => {
let redisAuthStore: RedisAuthStore;
beforeAll(async () => {
const moduleRef = await setupModule([CustomRedisModule]);
redisAuthStore = moduleRef.get<RedisAuthStore>(RedisAuthStore);
});
it('RedisAuthStore가 정상적으로 주입되었는지?', () => {
expect(redisAuthStore).toBeDefined();
});
it('Nonce 저장 및 조회 테스트', async () => {
// given
await redisAuthStore.setNonce('test-user', 'nonce-value', 600);
// when
const nonce = await redisAuthStore.getNonce('test-user');
// then
expect(nonce).toBe('nonce-value');
});
it('OTP 저장 및 조회 테스트', async () => {
// given
const otpData = { otp: '123456', issueDate: Date.now() };
await redisAuthStore.setOtp('test-user', otpData, 300);
// when
const retrievedOtp = await redisAuthStore.getOtp('test-user');
// then
expect(retrievedOtp).toMatchObject(otpData);
});
it('Nonce 삭제 테스트', async () => {
// given
await redisAuthStore.setNonce('delete-user', 'delete-value', 600);
// when
await redisAuthStore.delNonce('delete-user');
const afterDelete = await redisAuthStore.getNonce('delete-user');
// then
expect(afterDelete).toBeNull();
});
it('OTP 삭제 테스트', async () => {
// given
const otpData = { otp: '654321', issueDate: Date.now() };
await redisAuthStore.setOtp('delete-user', otpData, 300);
// when
await redisAuthStore.delOtp('delete-user');
const afterDelete = await redisAuthStore.getOtp('delete-user');
// then
expect(afterDelete).toBeNull();
});
});
둘 다 정상적으로 동작하는 모습을 볼 수 있다. 성공적으로 마이그레이션이 완료된 것 같다.
과제
NestJS 11버전을 기준으로 만들어졌는데, 사내 다른 NestJS 서버의 버전(v7, v10)들에도 사용할 수 있는지, 어느 버전까지 호환이 되는지 확인해보는 과정이 필요하다.
마치며
최근에 토스에서 발행한 NestJS 환경에 맞는 Custom Decorator 만들기 라는 포스팅을 봤다. 특정 모듈, 라이브러리, 기능 등이 필요한 상황에서 현재 사용중인 프레임워크, 라이브러리 전수 조사를 통해 함수 레벨에서 사용 가능한 데코레이터를 커스터마이징하여 사용한 것을 보고 충격을 받았다. 현재 사용중인 기술을 바탕으로 현재 기술에서 지원하지 않는 다른 무언가를 창조해낼 수 있다는 것이 신기하기도 했고 많이 부족하구나 라는 생각이 들었다.
이번 Redis Module을 만든 것은 어찌보면 기존의 nestjs-modules/ioredis라는 꽤 사용량이 높은 오픈소스가 기존에 있기도 했고, 단순 Dynamic Module을 하나 구성하여 ioredis와의 연계만 시켜주면 되기 때문에 쉬운 편이라고 생각한다. 하지만 난이도를 떠나 항상 무엇을 개선할 수 있을지 생각해보고 적용시킬 수 있다면 머리통이 깨지더라도(?) 적용해보는 편이 좋겠다는 생각이 든다. 오픈소스에서 필요 없는 기능을 빼서 커스터마이징하기만 하더라도 작게나마 리소스를 절감할 수 있기도 하고, 과정에서 배우는 것이 많기 때문이다. 단순히 필요 없는 기능을 걷어내고 최적화하는 과정도 소중하지 않을까? 라는 생각으로 마무리해본다.