내가 어떤 조직에 속하게 되었을 때, 조직에서 관리하는 애플리케이션을 한 번씩 사용자 관점에서 돌아보고, 개발자 관점에서 돌아보고 문제점을 리스트업하는 습관이 있다. 이를 통해 당장의 애플리케이션에 대한 이해를 넘어서, 어느 정도의 주인의식과 우선적으로 해결해야하는 과제는 무엇인지 선정하는 연습(?)을 같이 하고 있다.
이 포스팅은, 속했던 조직에서 가장 먼저 개선해야한다고 판단했던 실시간 채팅 기능의 개선기이며, 2년차인 현재 시점에서 더 개선할 부분은 없었는지가 첨가된 포스팅이다.
모자란 내용에 혹여 더 좋은 의견 남겨주시면 성장에 큰 도움이 됩니다. 감사합니다!
문제 파악하기
속했던 조직은, 커머스 비스무리한(?) 서비스를 운영하고 있었지만, 도메인 특성상 결제는 곧 예약이었다.
결제 후 오프라인으로 상품을 직접 소비(?)하는 특징과 더불어 상품들이 우리가 자주 소비하는 필수 소비재들의 성격이 아닌, 특정 니즈에 따라 대부분 일회성으로 구매하는 상품들이기 때문에 결제 전/후로 채팅을 통한 상담이 서비스의 코어였다.
이런 핵심 기능인 채팅에서 응답 속도가 평균 3초 정도로 매우 느리게 동작했고, 이는 시간을 갈아넣어서라도 반드시 해결해야하는 최우선 과제라고 판단했다.

최초에 파악했던, 채팅 전반의 플로우를 그림으로 나타내보았다. 메시지를 전송하면, 기본적인 메시지 관련 데이터베이스 I/O 작업과 더불어 메시지 전송에 처리되어야 할 모든 기능들이 함께 동기적으로 처리 되고 있었다. 근본적으로 응답 속도가 느릴 수 밖에 없는 구조였다.

더불어 아이러니하게도 이 실시간 채팅을 포함해 애플리케이션 내부에서 MyISAM 엔진을 사용하고 있었다. 동시성 제어를 위해 테이블 락 매커니즘을 사용하는 MyISAM의 특성상 쓰기 작업이 느릴 수 밖에 없었다. 여기저기 쓰기 작업을 하게 되는데, 메시지가 많아지면 많아질 수록 여러 테이블에서 서로 쓰기 작업을 위해 기다리는 현상이 기하급수적으로 늘어날 수 밖에 없다.
효과적인 테스트와 구현을 위해, 당시 최대 TPS를 산정해서 예상 최대 지점까지 고려했다면 어땟을까?
여기까지 생각이 미치지 않았다보니, 워커의 처리량보다 큐에 작업 유입량이 많을 때 어떻게 대처할지 등의 비동기 작업의 안전성을 보장하지 못했다고 생각한다.
비동기 처리를 위해
스토리지 엔진의 한계 외에도 단순 하나의 로직에 이리저리 얽혀있는 여러 비즈니스 로직들을 살펴보고, 메시지 전송 과정에서 반드시 수행되어야 할 로직과 아닌 로직들을 분리 했다. 메시지 전송이 성공했다. 라는 의미는 메시지를 저장하는 chat_message 테이블에만 입력을 보장하면 된다고 판단했고, 나머지 로직들을 전부 분리했다.

이 분리한 로직들을 다시 네 개의 구간들로 나눴고, 원자성을 보장해야하는 구간을 추가 DB 입력 구간인 추가 I/O와 업무 알림으로, 실패해도 괜찮다고 판단되는 부분들을 푸시알림과 SMS전송으로 구분했다.
메시지 전송 로직과 분리하여 비동기 처리를 수행하기 위해 BullMQ라는 메시지 큐를 사용했다. Kafka나 RabbitMQ 등도 Nest의 공식 문서에 UseCase등을 문서화해뒀는데 사용하지 않았다. 이들을 사용하기에는 발톱의 때 만큼의(?) TPS였다. 또 Nest에서 기본적인 Queue 사용문서 에 친절하게 언급되어있는 BullMQ의 실패 시 재시도와 스케줄링과의 연동, 이벤트 기반 처리와 이벤트 리스너를 통한 통합 로깅 등을 구현하기에 용이했기 때문에 BullMQ를 사용했다.
@Processor('chat-message-side-effect')
export class ChatMessageSideEffectWorker extends WorkerHost {
constructor(
private readonly chatService: ChatService,
private readonly notificationService: NotificationService,
private readonly crmService: CrmService,
private readonly fcmService: FcmService,
) {
super();
}
async process(
job: Job<{ jobId: string; payload: { userId: number; message: string } }>,
): Promise<void> {
// 메시지 전송 추가작업
await this.chatService.processAfterMessage(job.data.payload);
// 업무 알림
await this.notificationService.sendNotification(job.data.payload.userId);
// 고객 알림 (SMS, FCM)
await Promise.all([
this.crmService.sendCRM(job.data.payload.userId),
this.fcmService.sendFCM(job.data.payload.userId),
]);
}
}
처리량보다 작업량이 많아지는 상황을 고려했다면..?
TPS를 산정했을 때, 최대 TPS는 1.55였다. 단일 워커에서 DB I/O와 외부 API의 연동 작업들의 평균 latency가 1초대라고 가정하더라도 큐에는 작업이 계속 쌓이게된다. 위에서 언급한 것 처럼, 이러한 상황들을 먼저 가정하고 접근했더라면 워커의 concurrency를 늘리는 등의 동시 처리 방법까지 자연스레 고려할 수 있었을 것 같다.
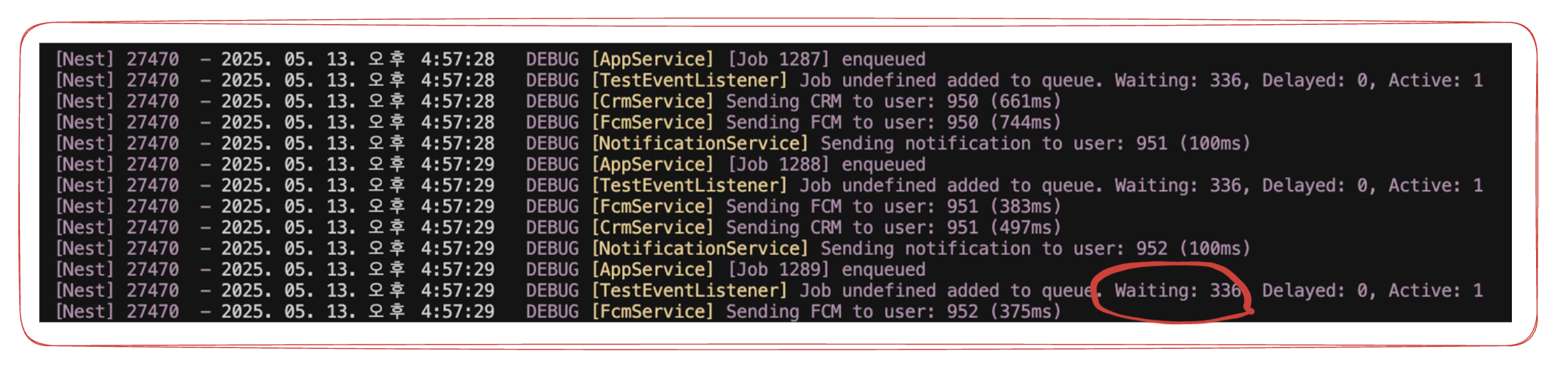
원자성 보장을 위해
메시지의 추가 I/O는 단일 테이블의 insert라고 하더라도, 업무 알림은 여러개의 테이블을 insert/update하는 연속적인 과정이다.
MyISAM은 항상 auto-commit한 쓰기 작업을 보장한다. 롤백을 무시하며 트랜잭션을 지원하는 엔진이 아니기 때문에, 이런 연속적인 과정에서 트랜잭션을 보장하기 위해서는 소위 transaction-like한 무언가를 직접 구현해야했다.
type InsertRecord = {
table: string;
id: number;
deleteFn: (id: number) => Promise<void>;
};
class JobTransactionContext {
private inserts: InsertRecord[] = [];
recordInsert(record: InsertRecord) {
this.inserts.push(record);
}
async rollback() {
for (const record of this.inserts.reverse()) {
await record.deleteFn(record.id);
}
}
}
이를 해결하기 위해 위처럼 트랜잭션 컨텍스트 객체를 사용해서, 트랜잭션을 보장해야하는 로직에 활용하게 되었다.
실패 후속 처리
워커에서 작업을 실패할 경우 원자성을 보장해야하는 경우는 실패로 간주되지만, 위에서 말했던 것 처럼 실패했을 경우에도 운영 상에 지장이 없다고 판단했던 SMS 발송과 푸시 알림은 실패로 간주되지 않는다.
위 정책에 따라 분리하여 트랜잭션이 롤백되는 상황에서만 실패로 간주하여 작업을 종료시키고, 실패 시 재시도 전략을 수립했다.
재시도는 BullMQ에서 기본으로 구현되어있는 지수 백오프(Exponential Backoff)를 사용했다.
모든 재시도에 지수 백오프만 사용할 경우 모든 실패한 작업들이 동시에 백오프 될 경우도 고려해야한다.
실패한 작업에 대해 재시도를 분산하기 위해 사용하는 전략임에도 재시도 과정에서 다시 요청이 몰리는 것은 똑같다.
이를 해결하기 위해 AWS에서는 지연 변이(Jitter)라는 개념의 추가 전략을 통해 일정의 랜덤 시간을 추가로 부여하여 재시도의 동시성을 분산했다고 한다.
(자세한 내용은 AWS의 공식 포스팅1 / 포스팅2 를 참조)
추가 개선
최근에 이 내용들을 복기하면서 추가로 고려하지 못했던 사항들이 무엇이었는지, 내가 1년 반 전과 비교해서 어디까지 고려하는 개발자가 되어있었는지 확인해보고 싶었다. 위에 잠깐 언급했던 트러블 슈팅을 위한 TPS 산정을 포함해서 정리한 피드백 내용은 다음과 같다.
- 위에서 언급한 TPS를 조기에 산정했더라면
- 큐에 메시지가 계속 쌓인다면? (처리량보다 유입량이 많은 경우)
- BullMQ의 심장(?)인 Redis에 장애가 발생한다면?
위 세 가지 상황이 모두 연관이 있는 것 같다. 1번을 조기에 고려하지 못해서 자연스레 2번 문제를 캐치하지 못했고, 2번 문제를 계속 방치하다보면 결국 최종에는 Redis에도 문제가 생기지 않을까? 추가 개선을 위해, BullMQ는 어떻게 Redis를 활용해서 Job을 입력하는지 알아보는 게 좋겠다.
BullMQ는 어떻게 메시지를 넣는가
import { Queue } from 'bullmq';
const queue = new Queue('queueName');
async addJob() {
await queue.add('jobName', { payload: ... });
}
await addJob();
BullMQ에서 구현한 Queue의 인스턴스를 활용하여 큐의 이름을 설정하고, (기본적으로) HSET을 활용해서 job의 이름과 데이터들을 넣는다. 아래 코드는 Nest의 공식문서를 따라 큐에 적재하기 위한 코드의 예시이다.
@Injectable()
export class ChatProducer {
constructor(
@InjectQueue('chat-message-side-effect') private readonly queue: Queue,
) {}
async sendMessage(userId: string, message: string) {
const jobId = `${Date.now()}-${Math.floor(Math.random() * 1000)}`;
const payload = {
userId,
message,
};
await this.queue.add(
'chat-message-side-effect',
{ payload },
{
jobId,
},
);
}
}
여기서 생각해보아야할 부분은, Redis의 SET은 중복된 키값이 있다면 내부 데이터를 덮어 쓰는 방식으로 동작 한다는 점이다. 이해를 돕기 위해, 실제 Job 등록에 사용되는 여러 자료구조 중 Hashes를 직접 CLI를 통해 입력해본 결과를 아래에 서술해두었다. 결과를 보면 중복 방지를 디폴트로 수행하지 않는다는 것을 알 수 있다.
127.0.0.1:6379> HSET user-1 name test
(integer) 0
127.0.0.1:6379> HGETALL user-1
1) "name"
2) "test"
127.0.0.1:6379> HSET user-1 name test2
(integer) 0
127.0.0.1:6379> HGETALL user-1
1) "name"
2) "test2"
그렇다면 BullMQ를 사용하는 우리 개발자들은 중복 처리를 사전에 확인하는 모듈을 따로 구성해야할까? 그렇지 않다. BullMQ에서는 편의를 위해 중복된 Job은 등록이 되지 않도록 처리해두었다. 우선 BullMQ의 소스 코드를 실제로 분석해 본 후 동작 과정에 대한 간략한 플로우를 그려봤다.

Redis에 데이터를 등록하기 위해 실행되는 add....Job-*.lua 스크립트에서 입력 전 중복 확인에 대한 로직이 같이 수행된다.
else
jobId = args[2]
jobIdKey = args[1] .. jobId
if rcall("EXISTS", jobIdKey) == 1 then
return handleDuplicatedJob(jobIdKey, jobId, parentKey, parent,
parentData, parentDependenciesKey, KEYS[5], eventsKey,
maxEvents, timestamp)
end
end
추가적으로 priority나 delayed 작업을 위한 ZSET 활용, 작업 로그를 위한 Streams등에 추가로 입력하지만, 이 부분은 현재 주안점에 벗어나니 생략하겠다. 관심 있으신 분들은 BullMQ 소스코드를 참고하면 될 것 같다.
이제 이러한 이해들을 바탕으로, 추가 개선을 어떻게 해야하는지 한 번 생각해보았다.
처리량 < 유입량
우선 처리량보다 유입량이 많은 경우부터 따져보자.
워커의 처리 속도가 생산 속도를 따라가지 못할 경우 큐에는 자연스레 Job이 쌓이게 된다.
이 상황이 지속되면 메모리 부담은 물론이고(Redis) 뒤에 들어온 Job의 처리 시간은 기하급수적으로 증가하게 된다.
위의 비즈니스 흐름을 예시로 절망적인 상황을 들어보자면 고객님이 어제 채팅을 보냈는데, 담당자는 오늘 업무 알림을 받아볼 수도 있다.
@Processor('chat-message-side-effect', { concurrency: 3 })
큐에 작업이 원활하게 처리되지 못하는 상황을 해결하기 위해 워커에서 동시 처리량을 제어할 수 있다. TPS가 최대 1.55였기 때문에 645ms당 1개의 요청이 발생한다고 가정하고, 워커의 처리 속도는 외부 API에 의해 최대 2초가 걸린다고 가정한다면 concurrency는 3~4정도가 적당할 것이다. 이처럼 적절한 동시 처리나 워커 자체를 늘리는 방향도 고려해볼 수 있다.
하지만 동시성을 제어할 경우에는 현재 사용중인 리소스, 여기서는 데이터베이스의 총 Connection과 평균 활성 Connection, 현재 서버의 Connection Pool과 할당된 메모리 자원 등을 고려하는 것이 필수이다. 이 모든 리소스간의 밸런스를 고려하는 엔지니어링이 개발자의 필수 덕목인 것 같다.
유입량이 많은 경우 중 또 고려해야할 부분은, 처리해야할 메시지가 중복해서 들어오는 경우이다.
하지만 위의 BullMQ의 기본 Job 적재 방식에 대한 이해를 바탕으로 중복 방지에 선 조회 후 early-return하는 코드는 오히려 추가 I/O가 발생할 것이라는 것을 짐작할 수 있다.
Redis 장애 대응을 위해
근본적으로 Redis 장애 발생 시 당연히 BullMQ는 더이상 메시지를 받을 수 없다. 또한 이미 enqueued된 작업조차 Redis의 휘발성이라는 특성 때문에 손실될 수 있다.
개발자로서 이런 현상을 미리 대응할 수 있도록 설계하여 이미 enqueued된 작업을 복구할 수 있도록 구성할 수 있어야한다.
아직까지 서비스에서 사용중인 Redis에 장애가 발생한 적은 없지만, 혹시 모를 Fail Over에 대비한 전략이 하나도 구성되어있지 않다는 것을 인지했다. 서비스 도메인 특성상 트래픽이 엄청나게 성장할 일은 없다고 판단해서 Sentinel로 FailOver 시 노드 승격 전략과 장애 발생 알림 처리를 구성했다. 서비스 레벨에서 Redis 연결 재시도를 허용하여 마스터 노드 전환 시에도 워커가 자동으로 재연결되도록 처리했다.
이와 더불어 꾸준히 큐들의 작업 개수를 주기적으로 수집하여 모니터링하고 대기열이 일정 수치를 초과하면 알림을 받아볼 수 있도록 구성하여 장애 징후를 빠르게 감지할 수 있도록 했다.
마무리
당시의 개선 방향과 현재 시점에서 생각나는 추가 개선 사항들을 정리하여 쭉 정리해보았다.
점진적으로 이런저런 시도를 해보면서 현재 트래픽을 감당하기 여유로운 상황이다보니 엣지 케이스들을 또 고려하지 못했나 싶기도 하다.
조금씩 알면 알수록 더 어려운 빌어먹을 엔지니어링의 세계 ㅡㅡ.. 외부 레퍼런스들을 많이 찾아보면서 실제 개선 사례들을 대입해보면서 무엇을 놓쳤는지, 지금 방식이 최적이었는지 계속 생각해보고있다. 언젠가 이 글을 다시 꺼내먹는 날 예전의 내가 한심해질지도..?
