돌아보면 정신없었다. 이전 환경과 달리, 스택도 도메인도 업무 방식도 전부 다른 환경에 던져졌다. 이전 회사에서는 IDC 환경에서 NodeJS를 사용했다. 현재 조직에서는 Django와 AWS를 사용한다. 모든 게 낯설고 적응하기에 바빴던 것 같다.
혼란스러웠고, 지금도 완전히 정리되진 않았다. IDC에서 콘솔을 들여다보는 게 문제여서 PLG로 모니터링 인프라를 구축했던 것처럼, 이번에도 무언가 시도하려고 파닥거렸던 것 같다.
수습 회고
기획이 버무려진 디자인을 받으면 스스로 판단해서 구현하는 환경에서 2년가량 근무했다. 소통의 필요가 적었고, 혼자 깊게 고민하는 게 습관이 되었다. 문제는 성장이 정체된 느낌이었다. 주어진 업무를 수행하고, 안정적으로 다니는 분위기였던 것 같다.
물론 극복하기 위해 주도적으로 사내에 여러 레퍼런스를 공유하고, 오픈소스 기여도 활발하게 하는 등 열심히 했다. 하지만 조직 내에서의 성장이 가져다주는 것에 대한 목마름은 여전했다. 나는 성장 욕구가 있는 사람들 사이에서 서로 기여하고 기여받는 선순환 구조를 원했다.
그래서 이직했다. 완전히 새로운 도메인의 스타트업. 5년 이하 주니어 개발자들로 구성되어 있지만, 다들 성장하고자 하는 욕구가 강하고 서로 공유하는 문화. 제품에 깊게 관여하고, 개발 외에도 제품적 사고를 하는 조직. 여기라면 내가 원하는 환경이 될 수 있겠다고 생각했다.
스택이 바뀐 건 예상했지만, 업무 방식의 변화는 예상 밖이었다.
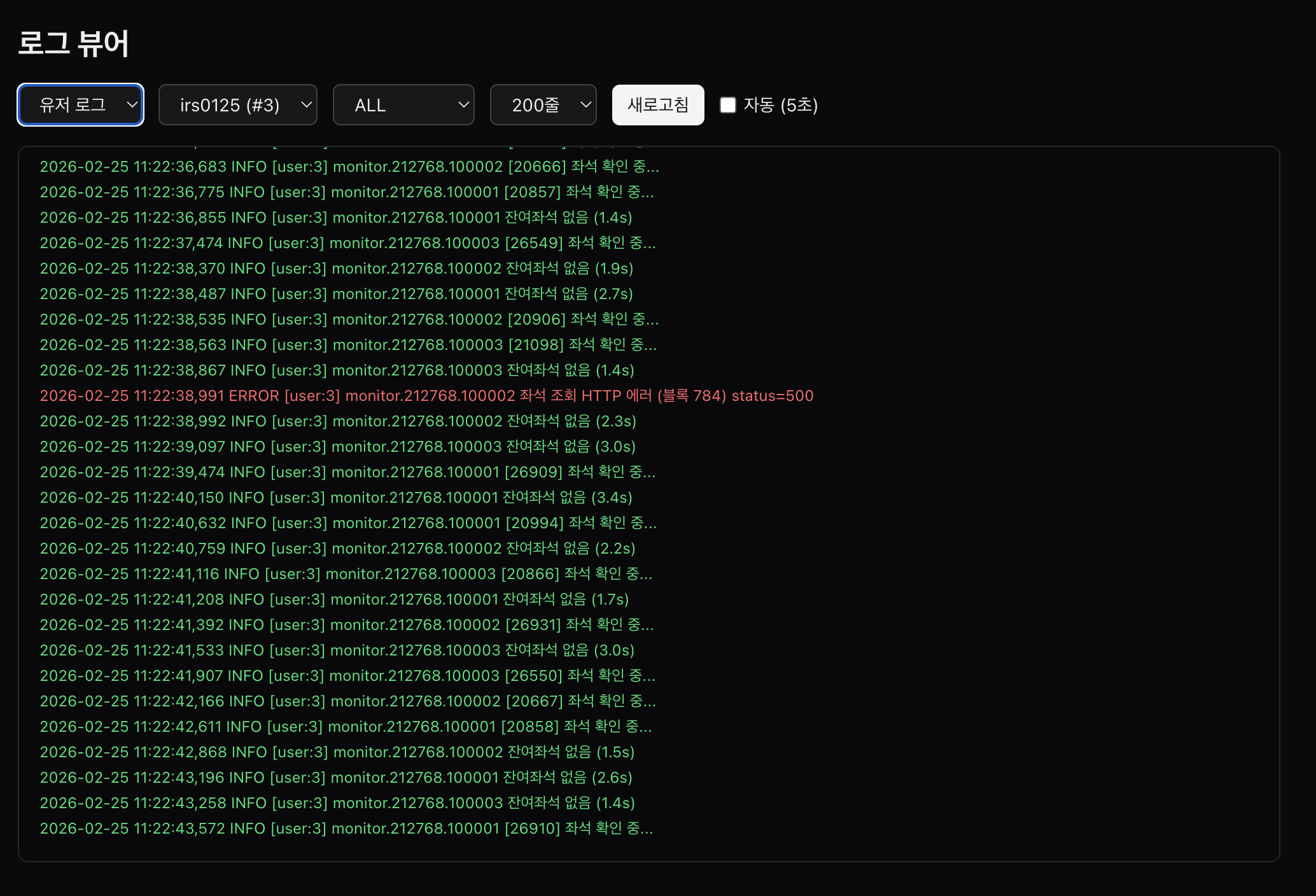
전 직장에서는 대부분 하나의 프로젝트씩 순차적으로 수행했다. 현재 조직은 스프린트 단위의 잦은 회의, 노션이나 슬랙 등 여러 업무 도구들에 분산된 정보들이 쏟아졌다. 단순히 일이 많은 게 아니라, 정보가 파편화되어 있었다. 어제 회의에서 뭐라고 했는지, 그 결정이 노션 어디에 있는지, 슬랙 어느 채널에서 논의가 이어졌는지 이걸 따라가는 것 자체가 일이었다. 나는 잘 잊어먹는 스타일이라 이게 치명적이었다.
개인의 문제를 해결해서 빠르게 적응을 해야했다. 그래서 MCH라 불리우는 업무를 위한 보조 도구를 만들게 되었다.
회의 중 발생하는 컨텍스트(텍스트/음성)를 입력하면 AI가 자동으로 분류하고, 프로젝트별로 체이닝해서 관리하는 TUI 도구를 만들었다. 마이크 녹음 → 자동 청크 분할 → STT → 임베딩을 통한 분류까지 추가했다. 나와 더불어 성장하고 제품에 대한 이해도를 같이 높일 수 있도록, 컴파운드 엔지니어링과 유사한 TIL도 추가했다. 점진적인 교정을 위한 도메인 용어 교정 사전도 넣었다.
이 데이터를 재활용해서 워크로그 대시보드를 만들었다. 오늘의 미팅, 코드 활동, AI 세션, GitHub 활동을 한 화면에서 볼 수 있는 도구. 하루 만에 MVP를 완성했다. 이 도구를 통해 조직에서의 나의 컨텍스트 관리를 정말 편하게 할 수 있게 되었다.
MCH를 만들 때는 조직의 문제를 해결하겠다는 거창한 생각이 없었다. 그냥 내가 혼란스러워서, 내 문제를 해결하려고 만들었다.
이번엔, 현재 조직에서 ROI가 높은게 무엇이 있을까? 고민해보았다. 하지만 마땅히 보이지는 않았다.
그러던 와중 조직의 슬랙 오류 제보 채널을 보면서 이거 매번 사람이 봐야 하나?라는 의문을 가졌다. 대부분 간단한 수정이기도 하고 이미 Agentic Workflow는 자리잡았기 때문이었다.
n8n 워크플로우 엔진 위에 Claude Code를 커스텀 노드로 올리고, Slack에서 앱 멘션으로 트리거하는 핫픽스봇을 만들었다. CS 문의가 들어오면 AI가 코드베이스를 분석하고, 원인과 수정 방안을 Slack으로 보고하고, 버튼 하나로 PR까지 생성하는 시스템이다. 전사적으로 사용할 수 있도록, 비개발자도 사용할 수 있도록 깎아나가는 중이다.
그런데 돌아보면, 이것들이 결국 AX의 출발점인가? 라는 생각이 들었다. 정보가 파편화되어있다 는 나의 문제, 반복적인 오류 분석에 시간을 쓴다 라는 기존 워크플로우의 문제도 모두 조직의 문제이기 때문이다.
AI로 기존 문제들을 해결하기 위한 시도들을 했던 덕분일까? 테크 조직 내에서도 2026년 목표에 대한 얘기들을 했을 때, 자연스레 AX로 역할을 정하게 되었다.
그런데 AX를 어떻게 접근해야할까?
자동화에 너무 초점이 맞춰져 있다는 생각이 들던 와중 일론 머스크의 어떤 인터뷰 내용을 전해 들었다.
회사에 있는 모든 사람은 벡터다. 진전은 그 모든 벡터의 합으로 결정된다. 대기업에선 벡터들이 서로 다른 방향을 가리키기 쉬워 합이 0이 된다. xAI는 엔지니어 팀은 작지만 모든 벡터가 같은 방향을 향한다. 그래서 합이 크게 나온다.
크기가 아무리 커도 방향이 다르면 의미가 없다. AX도 마찬가지라고 생각했다. 단순 자동화가 목적이 아니라, 조직의 실제 문제를 해결하는 게 목적이어야 한다고 생각했다. AX를 AI 도입이 아니라 MCH를 만들 때처럼 문제 해결로 접근하자. 솔루션이 아니라 문제에서 출발하자. 이 생각을 조직 대표님과의 커피챗에서 나눴다.
AX를 위해 조직원 한 명 한 명 일정을 조율하고 커피챗을 시작했다. 업무의 문제점과 불편함을 묻고, AI를 어디 사용하고 계시는지 등에 대한 인터뷰를 진행하고있다.
3개월동안 스프린트를 통해 제품 중심의 사고와 소통하는 방향에 대해 가닥을 잡고, 조직의 문제를 AI와 연계해서 해결하고자 하는 시도들을 하고 있다. 조금 더 문제를 잘게 쪼개고, 소통도 작게 작게 하는 방향으로 점진적으로 변해가고 있다. 아직도 여전히 혼란스럽지만 더 많고 다양한 시도들을 통해 조직에 다채롭게 기여하고 싶은 바람이다.
AI 시대에 어떻게 살아남아야할지 모르겠다.
나름 여러 시도들을 하면서도 계속 드는 생각이 있다. AI 시대에 어떻게 살아남아야 할지 모르겠다.
수습 기간동안 작업물들을 보면 백엔드 모노레포에 커밋이 835개, 기타 작업물들을 합치면 1500개 가량의 커밋을 올렸다. Claude의 JSONL 세션 파일이 960개가 넘고, 최근 Codex를 병행해서 사용하니 5GB가량, 1000개 가량의 세션 파일이 있다.
숫자가 많은지 적은지는 모르겠고, 이 모든것이 AI로 작성되었다는게 주제의 핵심이다.
문제를 해결하기 위해 A to Z 코딩을 했던 과거에서, 트렌드에 맞게 나 또한 의사 결정만 수행하고, AI 에게 코딩을 시키고 오케스트레이션만 수행하고 있다. 예전에는 내가 직접 코드를 쓰면서 이 로직은 왜 이렇게 돼야 하지? 를 코드 레벨에서 사고했다. 지금은 단순 코드보다는 구조에 대한 생각을 더 많이한다.관점이 코드에서 시스템으로, 구현에서 설계로 이동했다.
이게 성장인지, 아니면 하드스킬의 도태인지 아직 모르겠다. 그래서 아직까지는 이게 불안하다고 느낀다. 어느 정도 개발력이 되는 개발자분들과 달리, 저연차의 주니어 개발자이기 때문에 여러모로 지식이 많이 달린다고 생각했다.
2026년 1월 회고 - 이직 후 적응하기, 러너스하이 2기, Claude Code Max 200$ 등..
회고2026. 2. 2. 22:15
728x90
728x90
항상 회고글은 러프하게 남기는 것 같은데, 이번에도 역시..
혼란스럽다.
굉장히 혼란스럽다. 여태까지는 항상 요구사항이 담긴 기획서를 보고, 개발자가 정할 것들을 스스로 정해서 판단하고 개발하는 환경에 있었다. 생각해보면 개발자 이전, 내 삶의 전반에 항상 결정 후 통보가 일상이었던 것 같다. 그래도 어느 조직의 개발자이기 때문에, 어느정도 개발 스펙도 검토를 해야한다. 그래서 이전보다는 조금 나아졌다고 생각했다.
여러모로 혼란스러운데, 정리하자면
1. 소통이 생각보다 어렵다.
2. 목적조직과 파트의 업무. 그리고 개인 업무 사이에서 너무 많은 컨텍스트가 오간다.
소통이 어렵다.
항상 혼자 의사결정을 했기 때문에 내면에서 많이 고민을 했다. 그래서 정말 크리티컬한 이슈가 아니면 혼자 생각을 많이 하는 것 같다.
더 많이 소통하고, 더 많이 물어보면서 조금씩 개선하고 있다. 하지만 부족하다. 더 많이, 귀찮을정도로 물어봐야된다고 생각한다.
단순 개발적인 부분을 넘어 제품을 함께 만드는 한 사람으로서 얼라인이 확실하게 되어야 할 것 같다.
너무 많은 컨텍스트.
다양한 언어들에서 동시성도 높이면서 병렬 처리를 할 수 있는 다양한 방법들이 많이 나왔었고, 더 좋은 퍼포먼스를 갈수록 보이고 있다.
AI도 마찬가지다. 동시에 여러 작업들을 멀티로 돌리면서, 다양한 일을 동시에 수행할 수 있게 됐다.
한 번에 하나의 업무만 하던 환경에서, 동시에 다양한 업무들을 처리하다보니 기록하는 습관으로는 부족하다 생각이 들었다.
노션, 슬랙과 더불어 킥오프, 핸드오프, 타운홀 등 수도 없는 구두 논의 등에서 적느라고 이해하지 못하고 넘어가고, 듣느라고 적지 못해서 기억하지 못하고 있다.
혼란을 해결해보자.
그러던 도중 링크드인에 좋은 AX 관련 글을 봤다. (분명 링크를 저장해뒀는데 어디갔는지 없다.)
기억하자면 미팅 내용을 PRD로 자동화해서 만들고, 1차 검토 후 Claude Code로 PR까지 생성한다는 내용이었다.
이 레퍼런스에서 아이디어를 얻어, 여러 컨텍스트들을 녹음하거나 텍스트로 붙여넣기하고 Claude Code로 연관성 있는 것들끼리 그룹핑해서 바로 확인할 수 있게 구성해보면 어떨까? 생각했고 바로 실행했다. 녹음은 회의가 길어질 수 있기 때문에, FFMPEG + 청크 단위로 Whisper API를 통해 텍스트로 변환하여 Claude Code에게 던지는 간단한 형태이다.
최종적으로는 옵시디언, 노션 등의 텍스트 에디터로 export하거나 GUI로 구성하는 것을 목표로 하고 있다.
꽤나 유용하게 사용하고 있는 개인 툴이다. (TUI에서 위 ASCII Text가 왜 깨지는지는 모르겠다)
추가로 노션, 슬랙 등에 파편화 되어있는 여러 PRD들, 제품에 대한 여러 내용들을 복사 붙여넣기를 통해 한 번에 관리할 수 있게 되어 매우 편해졌다.
별거아닌 링크 저장소용 Chorme Extension.
링크 형태의 레퍼런스들을 많이 가지고있는데, 기존에는 카카오톡 나와의 채팅에 보관하다가 Linko라는 개인 앱을 만들었다.
휴대폰으로는 개발 레퍼런스를 유튜브 밖에 보지 않다보니 텍스트 형태의 링크 레퍼런스는 보지 않았다.
언제 내가 기술 블로그같은 레퍼런스를 많이 보나 생각해보니 데스크탑 앞에 앉아있을 때였다. 그래서 이번엔 Chrome Extension으로 만들었다.
언제까지 쓸 지는 모르겠지만, 아직까지 유용하게 잘 쓰고 있다.
난 어디에 시간을 할애하고 있는가?
개인적으로, 조직원으로서 어디에 개인적으로 시간을 할애하고 있는지 갑자기 오늘 고민이 됐다.
현재 같은 스쿼드의 개발자 두 분과 오늘 점심을 먹었는데, 나에게 날아온 질문이었다. 현재 어떤 것들을 하고 계시고 어디에 각 얼마만큼의 시간을 할애하고 계시냐고.
그냥 궁금해서 하셨던 질문일지, 나와 같은 2~3년차를 지나오신 개발자분들이 나를 위해 해주신 질문인지는 모르겠다.
나는 개인적으로는 DX 향상이 느껴질 때 가장 보람을 느낀다. 그래서 개인적으로는 AX나 사용하고 있는 기술들 자체에 더 개선할 수 있는 부분, 혹은 우리가 잘못 사용하고 있어서 충분히 개선 가능한 부분들(성능적인 부분, 레거시 청산 등)에 기여하는 것을 좋아한다.
하지만, 특정 조직에 속해있는 일원으로서 조직의 제품이 성장할 때 가장 큰 보람을 느낄 것 같다. 프리랜서 생활을 할 때 내가 맡은 팀이 하위권에서 1등을 했던 경험을 잊지 못한다. 그 도파민을 실제 제품이 J커브를 그리면서 성장할 때 똑같이 느낄 수 있지 않을까?
그렇다면 정답은 나와있는 것 같기도 하다. 제품 성장을 위한 AX와, 제품을 개발하는 개발자로서 제품을 보는 눈도 성장시켜야 한다는 것을 점차 알아가고 있는 것 같다.
부록 [1] - 러너스하이 2기 회고
러너스하이 2기를 신청했었다.
단언컨데 이직의 의사는 아니었고, 나는 어떤 환경에서도 빠르게 적응하고 성과를 낼 수 있다는 자만이었던 것 같다.
ROI는 무슨 현재의 환경에서 나은 퍼포먼스를 내기 위해 적응하고 적응하느라 2달을 통째로 썻다.
러너스하이 마감일에 제출은 무슨ㅋㅋ.. 마감일까지 한 술도 못 떳다.
부록 [2] - 오픈소스 기여모임 10기 운영진
오픈소스 기여모임 10기 운영진 활동을 참여했다.
이 또한 부끄럽게도 선택의 실패인 것 같다. 나의 활동이 도움이 되신 분들이 한 분이라도 계신다면 정말 다행이지만, 이직 후 적응을 핑계로 오프라인 행사에도 참여하지 못했고, 내 스택이 아닌 부분들도 오픈소스 기여를 처음 접한 분들에게 도움이 될 수 있는 부분들을 충분히 도움을 드리지 못한 것 같다.
다음 기수에도 운영진으로 참여할 수 있다면, 더 나은 오픈소스 기여 경험과, 오픈소스 기여 문화를 위해 조금은 더 활동에 박차를 가해야겠다.
부록 [3] - Claude Code Max
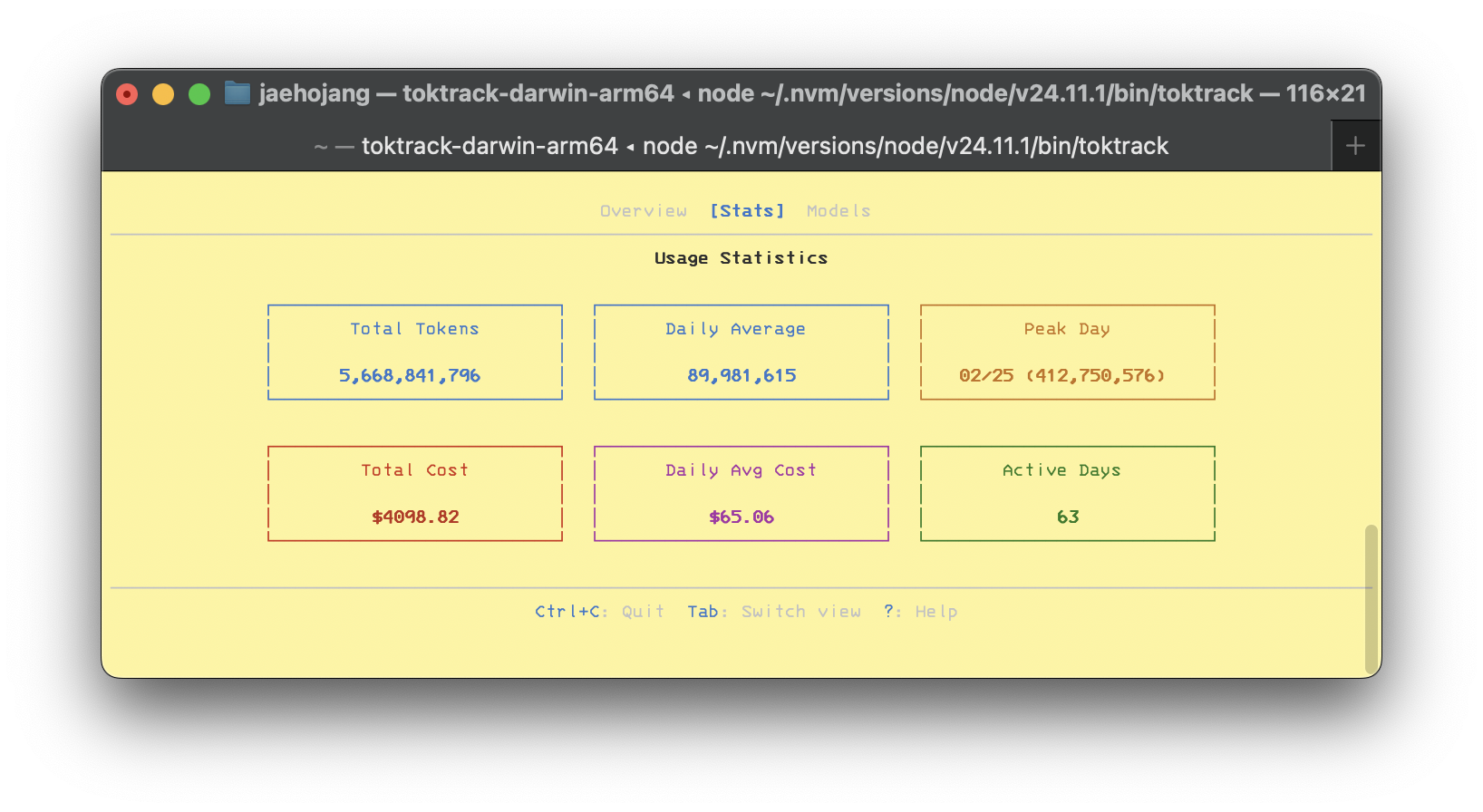
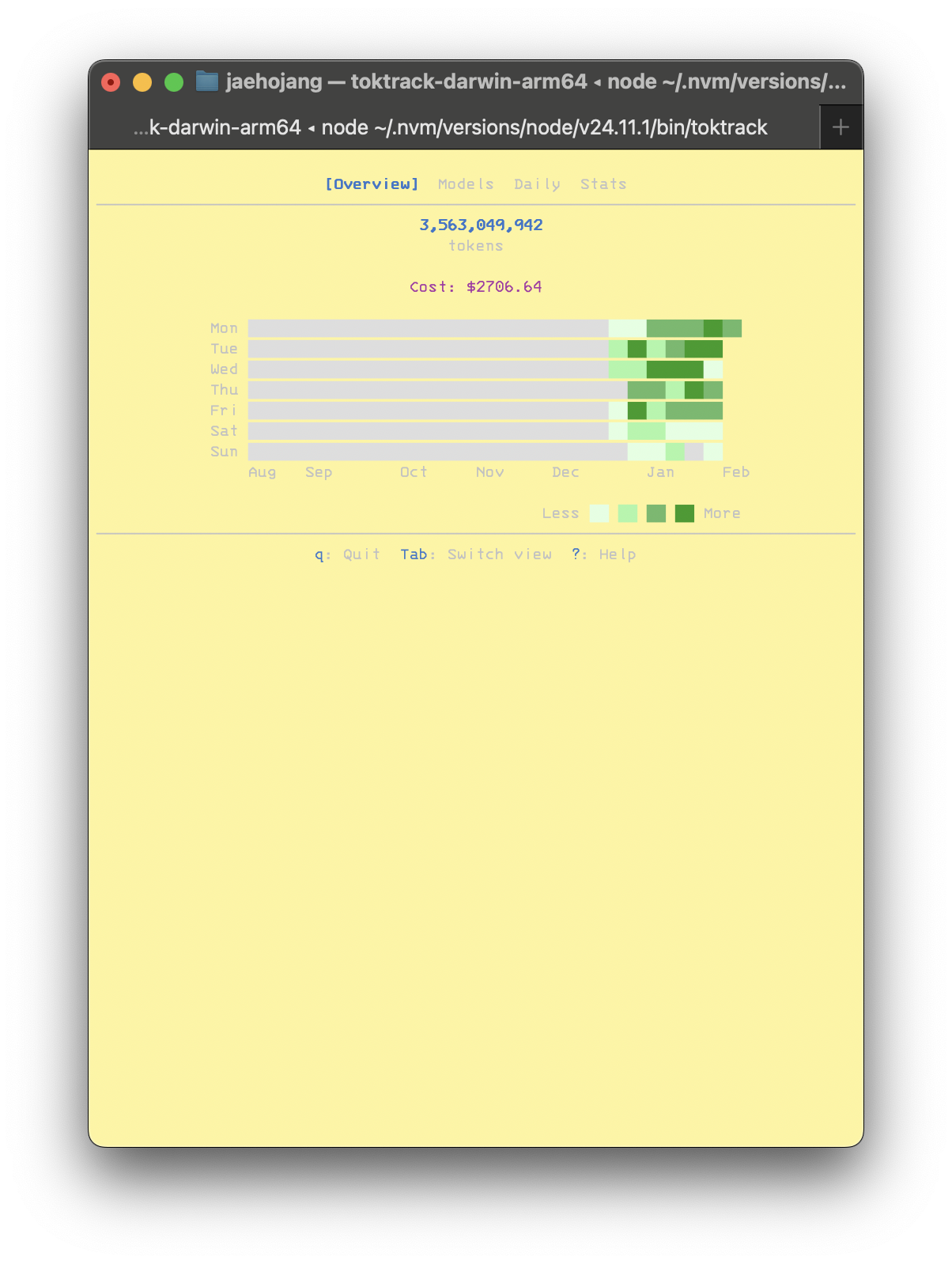
역대 최대로 Claude Code 사용량이 많은 것 같다.
주말에는 사용량이 많이 줄어서, 평일만 기준으로 보면 평균 150$씩 사용하고 있는 것 같다. 한 달 정도 사용했는데 2700$를 돌파했다.
굳이 따지고보면 한 달은 아닌데, Claude Code 세션이 자동으로 30일 뒤에 삭제된다. 이걸 최근에 알았다.
1. 이것저것 다양하게 시도해보고, 외부 AX 사례들을 시도해본다.
2. AI를 곁들인 무언가를 만들어낸다. 개인적으로도, 조직의 제품 내에 녹여내기도..
3. 코드 자체를 쓰는건 앞으로 더욱 더 안하겠구나.
마치며
내 삶의 전반에서 맡은 역할에 최선을 다했고, 개발자로서 처음 속했던 조직에서도 맡은 바 최선을 다했고 최선의 결과를 보여왔다고 생각한다. 하지만 직급과 역할이 정해진 뚜렷한 환경에서, 개발자는 개발만 맡았다 라는 전제가 깔려있다.
스타트업으로 이직하면서 현재의 그릇에 많은 생각이 든다.
생각하건데 그릇을 키우기 위해 노력하는 것이 아니라 그릇 자체를 꺠부실 필요가 있다.
앞으로의 회고에서는, 이런 부분들에 대한 시도와 실패. 경험들을 주로 회고할 수 있도록 현재의 조직에서 최선의 결과를 만들어봐야겠다.
ccusage를 출시 이래로 정말 잘 사용하고 있던 사용자 중 한 명이었습니다. 그런데 최근 체감될 정도로 느려졌어요. Claude Code의 JSONL 파일들을 확인해봤습니다.
# 용량
du -sh ~/.claude/projects
3.4G
# 파일 수
find ~/.claude/projects -name "*.jsonl" | wc -l
2772
Claude Code는 기본적으로 30일 지난 세션 파일을 자동 삭제합니다. 그럼에도 불구하고 최근에 역대급으로 많이 사용해서 그런지, 세션 파일이 생각보다 많이 남아있더라구요. 아마 사용량이 엄청나게 증가해서, ccusage가 수집하는 데 많은 시간을 소요하는 것이라고 생각했습니다. 43초가 걸렸으니까요.
해결되지 않는 이슈
국내/해외 할 것 없이 저보다 많은 사용량을 가진 사람이 더 많을 것으로 생각되는데요. 역시나 ccusage의 깃헙에는 여러 관련 이슈들이 이미 발행되어있는 상태였습니다. (#821, #804, #718)
성능 관련 이슈들이 열려있고, PR들도 머지되지 않은 채 방치되어 있었습니다.
이참에 직접 만들어보기로 했습니다. 성능 좋기로 소문난 Rust로 만들면서, 관심 있던 Rust 학습도 겸할 수 있으니까요.
언어는 Rust로, JSON처리는 Rust의 simd-json을 사용했습니다.
NodeJS의 한계
ccusage는 제 주력 스택인 TS로 작성되어 있습니다.
// ccusage의 파일 처리 방식
import { readFile } from 'node:fs/promises';
import { glob } from 'tinyglobby';
const files = await glob(['**/*.jsonl']);
for (const file of files) {
const content = await readFile(file, 'utf-8');
for (const line of content.split('\n')) {
const parsed = JSON.parse(line);
// 처리...
}
}
glob으로 파일을 탐색하고, fs로 파일을 읽고 JSON.parse로 파싱하게 되어있어요.
JSON.parse
V8은 JSON의 처리 성능을 꾸준히 개선해왔던 것으로 알고 있습니다.
v7.6에서는 JSON.parse의 메모리 최적화를, 최근 v13.8에서는 JSON.stringify의 SIMD 최적화가 대표적이죠.
하지만 이와 관계없이 JSON.parse는 여전히 순차 처리입니다.
JavaScript의 JSON.parse는 바이트 단위로 순차 처리합니다.
반면 simdjson은 CPU의 SIMD 명령어를 활용해 한 번에 32~64바이트를 병렬 처리하죠. simdjson은 초당 기가바이트 단위의 JSON을 처리할 수 있습니다. 문자 하나씩이 아니라 64문자를 한 번의 CPU 명령으로 처리하기 때문입니다.
물론 simdjson은 Node.js 바인딩도 존재하지만 유지 보수가 5년째 되지 않고 있어요.
그리고 JSON 파싱만 빨라져도 아래에서 다룰 싱글스레드, GC 오버헤드 문제는 여전히 남아있습니다.
V8은 Orinoco GC를 통해 Incremental Marking, Concurrent Sweeping 등으로 pause를 줄이고 있지만, 대용량 데이터를 처리할 때는 여전히 무시할 수 없는 오버헤드입니다. 50초 실행 중 504번의 GC가 발생했다는 것은, 평균 100ms마다 한 번씩 GC가 개입한다는 뜻이니까요.
Rust 선택의 이유
외부 레퍼런스들을 보면 항상 성능 좋다고 언급되는 Rust를 이 기회에 한 번 사용해보고 싶었습니다. 겸사겸사 공부도 하면 좋으니까요.
그 외에 사실 크게 특별한 이유는 없었습니다. (다른 오픈소스 홍보 글에는 사실 적어두었지만, 솔직하게 입장을 밝힙니다 ㅋㅋ)
JSON.parse에는 simd-json을, 파일 탐색에는 glob을, 병렬 처리는 rayon을 사용했습니다.
누군가에게 내 지식과 경험을 전달하려면, 단순히 알고 있는 수준을 넘어 더 깊이 이해하고, 불필요한 것을 덜어내며, 핵심만 남기는 과정이 필요하다는 걸 체감했기 때문이다. 발표를 준비하며 느낀 건 잘 전달한다는 건 말솜씨의 문제가 아니라 이해의 깊이와 사고의 구조가 드러나는 결과라는 점이었다.
이런 생각을 하던 시기에 조직의 CPO 님 추천으로 GoP(Garden of Practice) 오프라인 모임에 참여하게 되었다.
신기하다.
처음 든 감정이었다.
각기 다른 조직에 속한 많은 시니어 레벨의 구성원들이 주니어의 성장에 대해 진지하게 고민하고, 그 경험을 나누기 위해 모여 있다는 점이 인상 깊었다. 평소 비슷한 레벨의 주니어들과만 교류해왔던 나에게 이 풍경은 꽤 낯설고 새로운 자극이었다.
실제 모임에는 약 20명 정도가 모였는데, 체감상 시니어 비중이 훨씬 높았다. 또한 국내 애자일 코치 커뮤니티인 AC2에서 활동했던 분들도 많았는데, 그만큼 논의의 깊이와 밀도가 높게 느껴졌다.
삼삼오오 대화를 나누는 방식의 모임에서, 두 그룹에서 대화를 했다. 대화의 주제는 크게 두 가지로 모였다.
어떻게 하면 조직 구성원들의 성장을 구조적으로 도울 수 있을지, AI를 개인 차원이 아니라 조직 차원에서 어떻게 더 효과적으로 활용할 수 있을지에 대한 고민이었다.
이야기를 들으며 한 가지 생각이 계속 머릿속을 맴돌았다. 나는 이런 생각들을, 이렇게 정리해서 말할 수 있을까?
여전히 나는 내 생각을 정리해서, 듣는 사람이 이해하기 쉽게 전달하는 데 부족함을 느낀다.
특히 모임 중간중간 너드랩 대표이신 재완님이 복잡하게 흩어진 이야기를 짧고 명확한 문장으로 정리해 줄 때마다 그 전달력에 감탄하게 되었다. 같은 내용을 듣고 있었지만, 누군가는 이야기로 남기고 누군가는 구조로 정리해 전달한다는 차이가 분명히 느껴졌다. 효과적으로 전달하는 능력 역시 의도적으로 훈련해야 하는 하나의 역량이라는 생각이 들었다.
나는 내향적인 편이고, 사람들 앞에서 말을 조리 있게 잘하는 스타일은 아니다. 그래서인지 이런 시니어 중심의 커뮤니티는 편한 공간이라기보다는 나의 한계를 더 선명하게 보여주는 공간처럼 느껴졌다.
하지만 동시에 그래서 더 필요한 환경이라는 생각도 들었다. GoP가 지향하는 작은 실천, 정리된 기록, 반복 훈련이라는 같은 방향을 바라보다보면 천천히 생각하고, 구조를 쌓아가면서 점점 조리있게 전달하는 능력도 향상될 것 같다.
2026년에는 GoP와 더불어 여러 커뮤니티에 보다 적극적으로 참여하며 기술 스킬뿐 아니라 생각을 정리하고 전달하는 소프트 스킬을 의도적으로 훈련해보고 싶다. 편하지 않은 환경이지만, 지금의 나에게는 바로 그런 환경이 다음 단계로 가기 위한 조건이라는 생각이 든다.
2023년 2024년 회고를 되돌아보니 현실의 벽을 넘기 위한 노력, 의지들이 많이 보였습니다. 하지만 그 벽이 얼마나 높은지 가늠조차 되지 않았었던 것 같아요. 하지만 2025년 한 해는 어느 정도 노력이 헛되지 않았구나 생각이 들었습니다.
요약하자면, 성격의 한계를 극복했고 첫 이직을 했습니다. 그 과정에서 매번 서류 탈락하던 국내 빅테크들의 면접까지 경험할 수 있었습니다.
이전과 크게 달라진건 제가 사용하는 기술들에서 다양한 개발자들과 소통하며 기여했고, 과정에서 기술적인 깊이를 기르고자 노력했습니다.
AI 때문에 급변했고, 앞으로도 급변할 이 시장에서 어떤 개발자가 되고 싶은지 끊임없이 고민했던 2025년을 되돌아보려고 합니다.
러너스하이 1기
올 초에, 토스에서 진행하는 멘토링 세션인 러너스하이 1기에 참여하게 되었습니다.
신청할 때 기대했던 것과는 달리 멘토링보다는 토스의 인재상에 대한 소개와, 과제를 내려주는 채용 연계형 세션이었어요.
러너스하이는 짧은 기간 동안 스스로 문제를 정의하고, 해결하고, 결과를 돌아보는 집중 성장 프로그램 처럼 느껴졌습니다.
토스 Next가 코테 > 과제를 통해 문제 해결 능력을 본다면 러너스하이는 폭발적인 성장 가능성을 보는 것 같았어요.
저는 이 세션을 통해 ROI가 높은 과제를 선정하기 위해 끊임없이 관심 갖고 고민하는 관점을 하나 얻게 되었습니다.
추가로, 처음으로 러너스하이 1기에 참여했던 일부 멤버들과 함께 개발자 커뮤니티를 작게나마 형성했습니다.
이 두 가지는 개발자로서 끊임 없이 성장하고, 제가 추구하는 공유의 가치를 위해 작은 씨앗이 될 것이라고 생각합니다.
오픈소스 기여와 발표
오픈소스와 함께 한 2025년이라고 해도 될 만큼 오픈소스 덕분에 얻은게 참 많습니다.
기여 과정에서 얻는 지식은 물론, 내향적인 성격의 한계를 극복하고 이직까지 할 수 있게 된 계기가 되었습니다.
기여 요약
작년에는 오픈소스 기여의 막막함에 대한 진입 장벽을 허물고 기여하는 방법에 대해 어느정도 익혔다면, 올해는 본격적으로 기여 활동을 늘려나갔습니다. 제 커리어에서 가장 오래 사용했던 Node, Nest 프레임워크와 TS 진영의 ORM들, 모니터링 인프라를 구축하면서 사용했던 Loki와 무료여서 더 끌렸던 Gemini-CLI 등 다양하게 기여를 시도했습니다.
Prisma와 Gemini-CLI 기여 경험을 바탕으로 발표를 진행했습니다. 단순히 기여 내용을 공유하는 것이 아니라, 이슈를 효율적으로 분석하는 방법과 그 과정에서 어떻게 성장했는지에 초점을 맞췄습니다. 청심환을 먹었음에도 너무 떨려서 제대로 전달이 안되었을 수도 있지만요..
이직
기존 조직에서 많은 것을 배웠지만, BM의 한계를 많이 느꼈습니다.
더불어 제가 관심 있던 AI 활용이나 Agentic Workflow 구축을 시도하기엔 환경적 제약이 있었습니다.
더 자극을 느끼고 성장하며 다양한 경험을 쌓기 위해 이직을 해야겠다 라는 생각을 했고, 개발자로서 첫 이직을 할 수 있게 되었습니다.
그 유명한 당근 면접비 ㅋㅋ
작년에 이직 시도를 할 때와는 다르게 서류 합격률이 많이 높아졌습니다.
감사하게도 기술 면접을 열 곳 넘게 볼 수 있는 기회가 주어져서, 다양한 분야의 기업들에서 면접들을 볼 수 있었습니다.
특히 이번 이직 과정에서는 당근을 비롯한 네카라쿠배당토야 중 세 곳에서 과제와 면접 등의 질 좋은 경험들을 할 수 있었습니다.
이전까지는 서류 광탈에 빅테크는 제 길이 아니구나 생각했는데, 올 해는 어느 정도 제 노력들이 시장에서도 먹히고 있는 것 같아서 정말 기분이 좋았습니다.
저는 완전 새로운 도메인의 스타트업에서 커리어를 이어나가게 되었습니다. 제가 이직 시 고려했던 성장, 처우, 공유 라는 세 키워드가 모두 만족스러운 환경에서 더 많은 기여를 적극적으로 시도하는 중입니다.
개발자로서의 목표
올해 가장 많이 한 생각은 내가 어떤 개발자가 되고 싶을까? 입니다.
처음에는 시장에서 원하는 개발자가 되어야겠다고 생각했었는데요. 메타인지를 하는 과정에서, 저는 흥미를 잃으면 빠르게 이탈하는 성격이라는 것을 다시 한 번 인지하고 내가 왜 개발자가 되고 싶었었지? 앞으로 무엇을 하고 싶지? 를 중점으로 생각해봤던 것 같습니다.
오픈소스 기여를 통해 수 억명의 DX들을 개선하는 경험들을 접하고 기여 사이클에서 얻는 성장과 공유의 도파민이 가장 달콤했습니다.
그러다보니 Product Engineer 보다는 DX를 개선하는 영역 혹은 더 기술적인 깊이를 추구할 수 있는 사람이 되고자 방향을 잡았습니다.
최근 AI가 일상 생활에 너무 깊이 침투해있지만 아직은 할루시네이션 등의 이슈로 이런 깊이를 추구하는 방향이 나쁘지 않다고 생각했습니다. AI를 더 잘 활용하는 필수 역량 중 AI의 결과물을 빠르고 정확하게 검토할 수 있는 역량이 이런 깊이감이라고 생각해요. AI가 딸깍으로 모든 것을 해결해주는 세상이 온다면 목표가 달라져야하겠지만, 이떄는 목표를 수정하는 것이 아니라 직종 자체를 변경해야할 수도 있겠습니다.
CS 지식을 집중적으로 채워 넣기 보단 현업에서 마주한 문제에 관련된 지식들 위주로 습득했고, 운동은 습관화 시키지 못했어요.
저는 강한 동기부여가 있거나 진심으로 좋아하는 일을 할 때 몰입하는 사람이라는 것을 다시 깨달았습니다.
텍스트 형태의 장기 목표는 세우지 않고, 단기적으로 지금 무엇에 관심있는지를 브레인스토밍하고 거기에 집중하는 것이 좋겠다는 생각이 들어요.
마무리
2025년은 정말 감사한 한 해였습니다. 이전까지는 비전공 국비, 고졸이라는 자격지심이 있었던 것 같은데 이직 과정에서 이 부분이 100% 해소되었습니다. 앞으로 더 개발을 좋아하고 자연스레 성장해나간다면, 현재 조직에서 많은 임팩트를 주고 제 경험을 다양하게 공유하고 나눌 수 있으면 얼마나 행복할까? 라는 생각을 하고 있습니다.
2026년에는, 현재 조직에서 엄청 큰 임팩트를 하나 이상 만들어 보는 것을 최우선 과제로 두고, 현재 조직의 프로덕트 개선과 DX 개선 두 가지에 힘쓸 것 같아요. 개인적인 목표로는 300+ 스타 이상의 오픈소스 운영과, 개인 서비스의 사용자를 1k 이상 만들어보는 경험을 해보고 싶습니다.
2026년에는 보다 더 밀도 높은 성장을 통해 보다 더 인정받는 개발자가 위해 열심히 달려나가겠습니다!! 다들 2026년에도 화이팅입니다
// express/lib/application.js
app.listen = function listen() {
var server = http.createServer(this) // Node.js 내장 http 모듈 사용
return server.listen.apply(server, arguments)
}
그런데 Django는...
python manage.py runserver
# "WARNING: This is a development server. Do not use it in production."
# django 소스코드 일부
# django/core/management/commands/runserver.py
self.stdout.write(
self.style.WARNING(
"WARNING: This is a development server. Do not use it in a "
"production setting. Use a production WSGI or ASGI server "
"instead.\nFor more information on production servers see: "
f"https://docs.djangoproject.com/en/{docs_version}/howto/"
"deployment/"
)
)
소스코드를 확인해보니 무슨 SGI를 사용하라고하네요. 서울보증보험인가.. 별도의 서버가 필요하다는 것은 확실해 보였습니다.
Java기반의 Spring을 짧게 사용했을 때도 당연히 Tomcat을 별도로 사용했기 때문에 그런가보다 했습니다.
그런데 공부하다보니 2025년을 살아가는 저에게는 꽤나 독특한 녀석이라고 생각했습니다.
왜 Python 웹 생태계는 GIL 뿐 아니라 WSGI 같은 녀석도 표준이 되어 지금까지도 사용되고 있을까요?
애플리케이션과 서버의 분리
다시 말하지만 Node는 개발자가 웹 서버를 별도 구성할 필요가 없습니다.
런타임에 HTTP 서버가 내장되어 있어 별도 서버를 구성하지 않고도 바로 웹 서버를 띄울 수 있죠.
왜 이렇게 분리되었을까요?
2000년대 초반에는 Python 웹 생태계에는 Zope, Quixote, Webware 등의 다양한 프레임워크가 있었다고 합니다.
문제는 프레임워크 선택이 서버 선택이 되어, Zope를 쓰려면 Zope 서버를, Quixote를 쓰려면 또 다른 서버를 써야 했다고 해요.
Java에서는 Servlet API가 이 문제를 해결했어요.
어떤 서블릿 컨테이너(Tomcat, Jetty 등)에서든 서블릿 스펙을 따르는 웹 앱을 실행할 수 있습니다.
WSGI(Web Server Gateway Interface)는 웹 서버 게이트웨이의 표준 인터페이스입니다.
웹 서버와 Python Application 사이의 표준 인터페이스 인 셈이죠.
Python이 그러한 것 처럼, WSGI 또한 단순하고 간결한 것이 원칙이었다고 합니다.
Thus, simplicity of implementation on both the server and framework sides of the interface is absolutely critical to the utility of the WSGI interface, and is therefore the principal criterion for any design decisions.
the goal of WSGI is to facilitate easy interconnection of existing servers and applications or frameworks, not to create a new web framework
Phillip J. Eby (PEP 333 - https://peps.python.org/pep-0333)
callable은 말 그대로 호출할 수 있는 객체를 뜻해요. application() 처럼요.
참고로 응답이 리스트(iterable)인 이유가 있어요. 대용량 파일을 한 번에 메모리에 올리지 않고 chunk 단위로 스트리밍할 수 있게 하려는 설계입니다.
environ
이름만 봐도 감이 오죠? .env를 생각하면 될 것 같아요.
environ은 CGI 스타일의 환경 변수 딕셔너리에요. CGI(Common Gateway Interface)는 1990년대 웹 서버가 외부 프로그램을 실행하던 방식이에요. WSGI가 이 변수 컨벤션을 그대로 사용한 이유는, 당시 Python 프레임워크들이 이미 CGI 방식을 구현해뒀기 때문입니다.
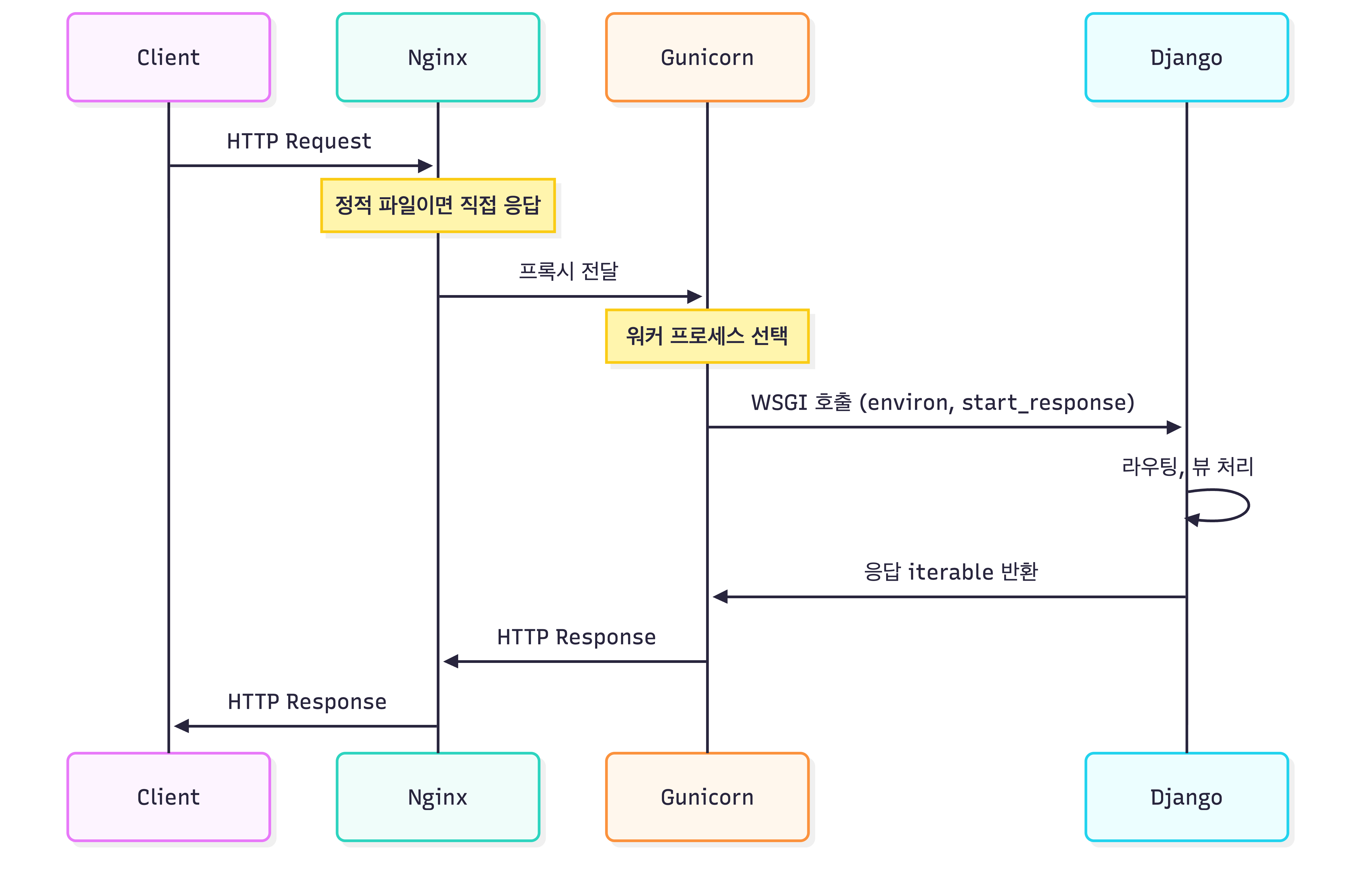
요청이 들어오면 워커 하나가 요청을 받고, 처리가 끝날 때까지 해당 워커는 점유되며 응답을 반환하고 나서야 다음 요청 처리가 가능해요. (sync worker 기준)
물론 Gunicorn도 gevent나 eventlet 같은 async worker를 사용하면 Green thread 기반으로 수백 개의 동시 연결을 처리할 수 있어요. 하지만 이건 WSGI 표준 위에서의 우회 방식이고, WebSocket 같은 양방향 통신은 여전히 구조적으로 불가능합니다.
물론 Django를 사용하더라도 멀티프로세싱이나 스케일 아웃으로 많은 워커를 구성하거나 적절한 캐싱과 인프라 구조의 최적화를 통해 개선할 수도 있겠죠...?
실제로 인스타그램은 2012년 Django + Gunicorn 스택으로 1400만 유저까지 스케일했고, 현재도 Django를 핵심 스택으로 사용하며 수십억 사용자를 처리하고 있어요. 대단하죠.. (인스타 기술 블로그)
ASGI
ASGI(Asynchronous Server Gateway Interface)는 비동기 기능을 갖춘 파이썬 웹 서버 인터페이스입니다.
(ASGI 스펙 문서에서는 WSGI의 정신적 후계자(spiritual successor)라고 소개되어 있어요)
async를 통해 비동기 처리를 지원하는 ASGI는 Django 기준 3.0부터 공식 지원한다고해요.
WSGI가 요청을 받아 응답을 반환하는 단방향이었다면, ASGI는 receive/send로 언제든 양방향 통신이 가능한 구조입니다.
# asgi.py
import os
from django.core.asgi import get_asgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'myproject.settings')
application = get_asgi_application()
Django에서는 ASGI를 지원한다고 해서 모든 코드가 비동기로 동작을 지원하지는 않습니다.
대표적으로 Django ORM은 기본적으로 동기 드라이버(psycopg2 등)를 사용하기 때문에, DB 쿼리 시 해당 스레드가 블로킹됩니다.
def my_view(request):
result = SomeModel.objects.all() # 동기 ORM
return HttpResponse(result)
하지만, Django 4.1 버전 이후부터는 async ORM을 점진적으로 지원하기 시작했고, ORM 뿐 아니라 Django와 Python에서 비동기를 점진적으로 지원하기 위한 노력은 지금도 꾸준히 진행되고 있는 것으로 보여요. (이전 글에서 다룬 GIL Free-threading도 그 일환이죠)
정리
Node에서는 런타임에 내장되어있었기 떄문에, 그리고 기본적으로 비동기를 지원했기 떄문에 다소 많은 차이가 느껴졌습니다.
이전 GIL 포스팅과는 다르게 마냥 부정적으로만 보이지는 않았는데요, 이는 GIL이라는 언어 자체의 레거시와는 느낌이 달랐기 떄문입니다.
GIL은 언어(CPython) 레벨의 문제이고, WSGI는 프레임워크와 웹 서버 생태계의 문제입니다. 흥미롭게도 생태계 전환이 오히려 더 빠르게 진행 중이에요. GIL 제거는 수십 년간 시도 끝에 Python 3.13에서야 실험적으로 도입된 반면, ASGI로의 전환은 FastAPI의 부상, Django 3.0+의 공식 지원 등 이미 활발히 이루어지고 있죠.
특히 Django는 ORM, Admin, Auth 등 많은 기능이 내장되어 있고, 이 모든 것들이 동기 기반으로 설계되어 있잖아요. 이걸 비동기로 전환하려면 프레임워크 전체가 바뀌어야 하는 거니까요. 그래도 Django 4.1부터 async ORM이 점진적으로 지원되고 있고, Python 생태계 전체가 비동기를 향해 나아가고 있으니 긍정적으로 보고 있어요.
그리고..... 개발자의 역량에 따라 동기적인 웹 서버로도 충분히 10M+의 트래픽이 제어 가능하고 인스타라는 선진 사례도 있기 떄문에, 이 모든게 저의 역량에 달린 일이 아닐까..(?????????) 하는 생각도 들었습니다.
다음 Python 관련 스터디는 딱히 정해지진 않았지만, 무언가 정리할 만한 주제를 찾아 돌아오도록 하겠습니다.