[다음글] Branch와 HEAD로 보는 Git 히스토리 모델(DAG) 이해하기
[다음글] Git merge / rebase / cherry-pick으로 히스토리 다루기
서론
만 2년 넘게 개발을 해오면서 Git을 무수히 많이 사용했지만 정작 내부 원리에 대해서는 생각해 본 적이 없는 것 같아 이번 기회에 학습하면서 관련 내용들을 정리 해보려고 합니다.

공식 문서에서는 Git을 내용 기반 주소를 사용하는 Key-Value 저장소이자 파일 시스템 정도로 설명합니다.
이번 포스팅에서는, 이 저장 방식에 대한 이해를 토대로 Git의 데이터 저장 방식과 commit까지의 과정에서 어떤 일들이 발생하는지 등에 대해 알아보려고 합니다.
포스팅에 사용된 디렉토리 구조는 다음과 같습니다.
Git

git 레포지토리 내에는 항상 .git/objects 디렉토리가 있습니다. 이 디렉토리 안에 모든 버전의 파일/디렉토리/커밋 정보가 객체 형태로 저장됩니다. Git은 이 오브젝트들을 해시 → 압축된 오브젝트 형태의 Key-Value로 관리합니다.
- key: 오브젝트 해시 (기본은 40자 SHA-1, 최근 SHA-256 지원)
- value: 타입(blob/tree/commit/tag) + 내용(zlib 압축)
Git의 객체
Git이 저장하는 오브젝트 타입은 네 가지입니다.
Blob: 파일 내용을 저장하는 객체
blob은 파일의 내용만 저장하는 객체입니다.
우리가 디렉토리에 생성하는 코드 파일, 문서, 기타 텍스트/바이너리 파일들이 여기에 해당합니다.
파일 이름, 경로, 권한 등은 기록되지 않고 오직 내용만 Blob에 저장됩니다.
# src/app/main.ts를 추적
C:\Users\root\Desktop\dev\git-study> git cat-file -p 25b690689b298649c027af668c051282a96eed6c
test
Tree: 디렉토리 1개를 나타내는 객체
디렉토리를 나타내는 객체로, mode/type/name/object-hash가 저장됩니다.
# src/app 디렉토리를 추적
C:\Users\root\Desktop\dev\git-study> git cat-file -p 4401420390c38334914cdb88c0b1231d058605d2
# mode type hash name
100644 blob 25b690689b298649c027af668c051282a96eed6c main.ts- mode: POSIX 파일 모드를 나타내는 6자리 숫자로 파일/디렉토리/실행파일/심볼릭링크 등의 하위 해시값의 판별 정보
- type: 하위 해시값의 타입 (blob / tree / commit (submodule일 때)
- hash: 해당 객체의 해시
- name: 실제 원본 이름
위에 예시에서는 blob 타입의 일반 파일이며, 파일의 해시값과 이름의 k-v를 가지고 있다고 해석할 수 있겠습니다.
Commit: 실제 커밋 시점의 프로젝트 스냅샷을 가리키는 객체
우리가 git commit을 할 때 생성되는 오브젝트입니다. 커밋 자체가 코드 내용을 직접 들고 있는 건 아니고, 루트 트리(tree)의 해시와 메타데이터, 부모 커밋 해시를 함께 가지면서 이 시점의 스냅샷은 이 tree를 보면 된다 라고 가리키는 역할을 합니다.
Commit 객체에는 커밋 시 작성된 메시지를 포함한 각종 메타데이터들을 가지고 있습니다. git log 명령어를 통해 나온 해시값으로 추적해보면 다음과 같은 정보를 얻을 수 있습니다.
# first commit
git cat-file -p 7fc68d4fc2bca212fb60a2aa8dd55a5c3093c46c
tree 3354a0b3ad3cbd78d1ab5c596208b8fccd9e2cc9
author mag123c <diehreo@gmail.com> 1763531007 +0900
committer mag123c <diehreo@gmail.com> 1763531007 +0900
first
# second commit
git cat-file -p fc912aa419552b61e97fb086dae0cefdc20cd58a
tree be513172b3e4eec559c85d7215444197292d7e92
parent 7fc68d4fc2bca212fb60a2aa8dd55a5c3093c46c
author mag123c <diehreo@gmail.com> 1763531141 +0900
committer mag123c <diehreo@gmail.com> 1763531141 +0900
second- tree: 이 커밋이 가리키는 루트 tree의 해시 (루트 디렉토리)
- parent: (첫 번째 커밋이 아닐 경우) 부모의 commit 해시
- author / committer / 날짜 / 메시지등의 메타데이터
commit을 만들 때 필요한 재료는 위에서 본 것처럼 메타데이터, 프로젝트 루트 해시, 부모 커밋 해시로 이루어집니다. 이 세가지를 텍스트 형태로 이어 붙인 뒤, 그 전체에 헤더를 붙여 해시를 내면 커밋 오브젝트의 해시가 됩니다.
tag: 커밋의 이름을 붙이는 객체
보통 버전관리에 많이 쓰이는 tag 또한 객체로 관리되는데, 이번 포스팅 주제에서는 크게 다루지 않겠습니다.
Commit을 하면 어떤 일이 일어날까
Git에서 저장을 위해 사용되는 객체들을 살펴봤습니다. 이제 이 객체들을 조합해서 commit을 할 때 내부적으로 어떤 순서로 동작하는지 알아보겠습니다.
1. 파일 내용을 blob으로 저장
워킹 디렉토리의 스테이징 영역에서 추적된 파일을 읽습니다. 파일 내용을 읽고, 해싱해서 저장합니다. 이 때 같은 내용의 파일이면 해시가 같으므로 저장하지 않습니다. 이는 아래 예제에서 다루겠습니다.
2. 디렉토리를 tree로 저장
이제 디렉토리별 스냅샷을 만듭니다.
- 디렉토리의 내부 파일 / 디렉토리를 이름 순으로 정렬
- 각 엔트리에 대해 mode / type / hash / name을 나열
- 디렉토리 내의 엔트리들을 mode type hash name 형식으로 쭉 나열해서 하나의 바이트 시퀀스로 만들고, 이 전체에 대해 해시를 계산해 tree 오브젝트를 생성합니다.
이 과정을 하위 디렉토리부터 루트까지 재귀적으로 진행하여 루트 디렉토리를 나타내는 하나의 tree 해시를 구합니다.
3. commit 객체 생성
커밋 메시지 등의 메타데이터와 트리 해시, 부모 커밋 해시를 이어 붙인 commit 객체를 만들고, 이 내용 전체를 해싱한 값을 생성합니다.
당연하겠지만, 스테이징이 있으면 새로운 커밋을 생성하고 변경된 blob이 속한 tree들의 해시가 바뀌고 결론적으로 commit이 새로 생성됩니다. 하위 해시가 바뀌면 관련된 상위 해시도 전파되어서 바뀌게 된다는 뜻입니다.
예제로 살펴보기
위의 예제 디렉토리 구조를 처음 생성하고 두 개의 커밋을 생성해서 비교해보겠습니다.
- first: main.ts에 "test"라고 입력 후 커밋
- second: test.ts에 "TEST"라고 입력 후 커밋
git log
commit fc912aa419552b61e97fb086dae0cefdc20cd58a (HEAD -> master)
Author: mag123c <diehreo@gmail.com>
Date: Wed Nov 19 14:45:41 2025 +0900
second
commit 7fc68d4fc2bca212fb60a2aa8dd55a5c3093c46c
Author: mag123c <diehreo@gmail.com>
Date: Wed Nov 19 14:43:27 2025 +0900
first
git cat-file 명령어의 pretty print(-p)를 통해 첫 번째 커밋을 추적해보겠습니다.
# first commit
git cat-file -p 7fc68d4fc2bca212fb60a2aa8dd55a5c3093c46c
tree 3354a0b3ad3cbd78d1ab5c596208b8fccd9e2cc9
author mag123c <diehreo@gmail.com> 1763531007 +0900
committer mag123c <diehreo@gmail.com> 1763531007 +0900
first
git cat-file -p 3354a0b3ad3cbd78d1ab5c596208b8fccd9e2cc9
040000 tree bb43df4aafae55c85532fa9f8abc1012c5cbfd03 src
git cat-file -p bb43df4aafae55c85532fa9f8abc1012c5cbfd03
040000 tree 4401420390c38334914cdb88c0b1231d058605d2 app
040000 tree dd830e88013a96181c12f9a822313760968701e1 test
PS C:\Users\root\Desktop\dev\git-study> git cat-file -p 4401420390c38334914cdb88c0b1231d058605d2
100644 blob 25b690689b298649c027af668c051282a96eed6c main.ts
PS C:\Users\root\Desktop\dev\git-study> git cat-file -p 25b690689b298649c027af668c051282a96eed6c
test
PS C:\Users\root\Desktop\dev\git-study> git cat-file -p dd830e88013a96181c12f9a822313760968701e1
100644 blob 49cc8ef0e116cef009fe0bd72473a964bbd07f9b test.ts
C:\Users\root\Desktop\dev\git-study> git cat-file -p 49cc8ef0e116cef009fe0bd72473a964bbd07f9b
# 공백
똑같이 두 번째 커밋을 추적해보고, 결과를 플로우 차트로 정리해봤습니다.
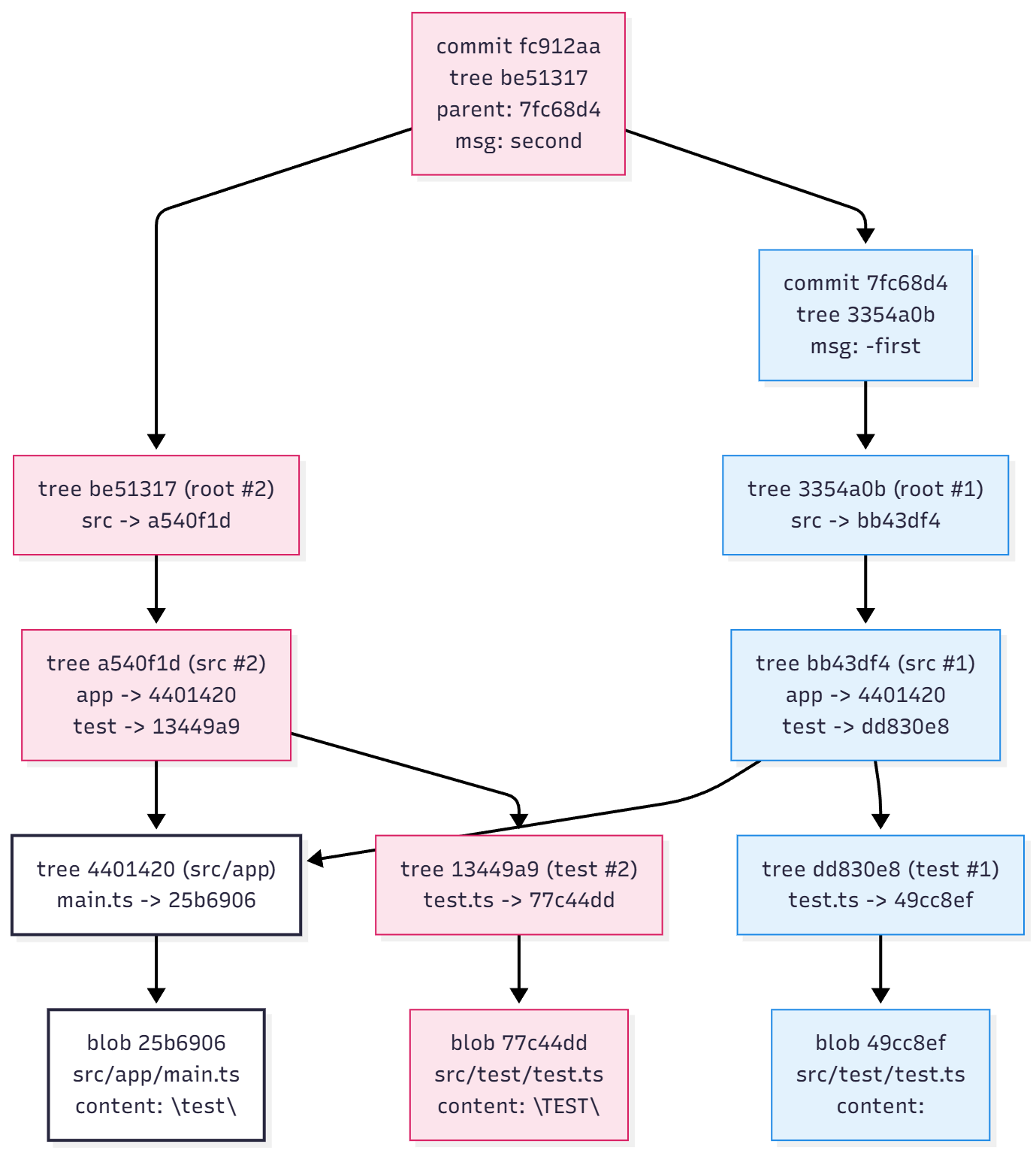
파란색이 첫 번째 커밋, 빨간색이 두 번째 커밋입니다.
여기서 눈여겨볼 점은 src/app과 main.ts, 즉 변하지 않은 tree, blob은 그대로 재사용된다는 점입니다.
test.ts 내용이 바뀌었기 때문에 test.ts blob이 새로 생성되고 이와 관련된 test tree, src tree, root tree만 새로 생성되어 새로운 commit객체로 새로 생성되게 됩니다.
안전성/불변성의 보장
이 구조를 보면, 특정 커밋을 읽어오는 과정에서 특정 해시가 사라진다면 전체 커밋에 손상이 생겨 해당 커밋이 날아갈 수도 있습니다. 특정 해시가 없어서 모든 데이터를 온전하게 읽어올 수 없으니까요.
Git은 이러한 문제를 사전에 방지하기 위해, 한 번 생성된 객체의 내용을 바꾸는 대신 항상 새 객체를 만들어 쌓는 방식으로 동작하도록 설계되어 있습니다. 위의 예제에서 test.ts의 내용이 바뀌었을 때 연관된 모든 객체들의 해시가 새로 생성되어 저장되었던 것 처럼 말입니다. 또한, 기존 객체를 수정하는 API도 없으며 일반 Git 사용 흐름에서 객체를 직접 지우지 않고 브랜치/태그에서 해당 해시에 참조가 끊기면 나중에 GC를 통해 쓸모없는 객체를 정리하도록 되어있습니다.
그래서 히스토리를 force-push로 지운 것처럼 보여도 어느 시점까지는 reflog나 GC 설정에 따라 객체는 꽤 오래 남아있게 됩니다.
이 불변성 덕분에 중간에 해시가 바뀌어서 깨지는 문제는 거의 없으며, 오픈소스에서 누가 뭘 하든 기존 커밋 자체는 남아있게 됩니다.
참고로 git commit --amend 명령도 기존 커밋 객체를 수정하는 게 아니라, 수정된 내용/메시지를 반영한 새로운 커밋 객체를 하나 더 만든 다음 branch ref를 그 새 커밋으로 옮기는 동작에 가깝습니다. 개발자 입장에서는 덮어쓰기처럼 보이지만, 내부적으로는 새 커밋이 하나 더 생기고 예전 커밋은 브랜치에서만 끊길 뿐 .git/objects 안에는 남아 있다가, 나중에 reflog나 GC 정책에 따라 정리됩니다.
이와 관련된 자세한 내용은 GitHub 블로그에 자세히 설명되어 있습니다.
Git Diff의 동작
그럼, 커밋들을 비교하는 git diff는 어떻게 동작하는걸까요?
git diff는 상황에 따라 내부적으로 git diff-tree, git diff-index, git diff-files 같은 로우 레벨 명령을 사용해서 실제 변경 내용을 계산합니다. 두 blob 쌍이 결정되면, 그 위에 Myers 같은 텍스트 diff 알고리즘을 적용해서 우리가 보는 +, - 기반의 diff 출력을 만듭니다.
git diff 7fc68d4fc2bca212fb60a2aa8dd55a5c3093c46c fc912aa419552b61e97fb086dae0cefdc20cd58a
diff --git a/src/test/test.ts b/src/test/test.ts
index 49cc8ef..77c44dd 100644
--- a/src/test/test.ts
+++ b/src/test/test.ts
@@ -1,2 +1,2 @@
-
+TEST
commit끼리 비교하는 git diff 기준으로 단순화해보면, 동작 방식은 다음과 같습니다.
- 두 commit에서 각 루트 tree 해시를 가져옴
- 두 tree를 동시에 비교하면서 같은 path를 가진 엔트리끼리 매칭. 엔트리들의 해시가 다르다면 하위로 내려가며 blob 쌍을 수집
- 수집된 blob 쌍에 대해 텍스트 diff 알고리즘을 적용해 최종 diff 출력을 만듬
중요한 건, Git이 diff 결과를 저장하지 않는다는 점입니다. Git은 각 커밋에서 전체 스냅샷을 tree/blob으로 보관하고, git diff 실행 시마다 두 스냅샷을 비교해서 그때그때 계산합니다. 그 대신 tree/hash 구조를 활용해 해시가 같은 subtree를 통째로 건너뛰는 식의 최적화를 수행하기 때문에, 큰 저장소에서도 diff가 빠르게 동작할 수 있습니다.
Git은 왜 이런 설계를 택했을까?
Git은 파일 내용을 Blob으로 저장하고, Blob들을 엮어서 Tree(디렉토리)를 만들고, 최상위 Tree와 메타데이터를 Commit으로 묶어서 시점을 고정한 뒤 계속 쌓아 올리는 방식으로 동작하는 것으로 보입니다. 지금까지 정리한 내용을 기준으로 왜 이런 설계를 택했을까? 에 대한 생각을 서술해보려합니다.
중복 제거와 무결성
blob/tree/commit을 모두 해시로 식별하는 구조 자체가 많은 것을 부수적으로 가져오고 있다고 생각합니다.
같은 내용의 파일은 디렉토리와 파일명이 달라도 같은 Blob 해시를 가집니다. 그렇기 때문에 하나의 blob만, tree만 저장하면 됩니다. 내용을 기준으로 주소를 정하는 구조 덕분에 dedup이 기본값이 됩니다.
또한, 내용 전체를 해싱한 값이 곧 ID, Key값 입니다. 내용이 1바이트라도 바뀌면 해시가 달라지기 때문에 해시만 맞으면 내용이 깨지지 않았다는 것을 어느정도 신뢰할 수 있습니다. 중간에 내용이 달라진다면 해시가 변경되기 때문에 바로 확인이 가능합니다.
스냅샷 + 구조적 공유 = 저장 효율
git checkout을 통해 특정 버전의 코드 전체가 구성되기 때문에, 겉으로 보면 커밋 = 프로젝트 전체 스냅샷 인 것처럼 동작합니다.
하지만, 이번 학습을 통해 내부 구조를 확인했습니다.
매 커밋마다 전체 파일을 통으로 새로 저장하지 않고, blob/tree 해시를 기준으로 구조적 공유를 하고 있습니다.
이런 구조 덕분에 사용자 입장에서는 스냅샷처럼 활용이 가능하고, 실제 저장소 입장에서는 변경된 부분만 새로 생성하고 해시로 공유하여 재사용이 가능한 구조입니다. 즉 외부 API는 스냅샷 모델이라 쓰기 편하고, 내부 구현은 구조적 공유를 통해 용량/성능을 최적화한 구조가 됩니다.
불변성과 히스토리 관리
또 하나 인상 깊었던 점은, Git이 한 번 만들어진 객체는 건드리지 않는다는 점입니다.
blob / tree / commit은 만들어질 때 내용 전체를 해싱해서 Key(해시)를 만들고, 그 이후에는 그 내용을 수정하지 않습니다. 내용이 바뀌면 항상 새로운 해시, 새로운 객체가 생깁니다.
이렇게 해두면 얻는 장점이 몇 가지 있는 것 같습니다.
우선, 중간에 히스토리가 모르게 바뀌는 일을 막을 수 있습니다.
기존 커밋의 내용을 바꾸는 API가 없기 때문에, 누군가 과거 커밋을 슬쩍 수정해버리는 식의 상황은 구조적으로 만들기 어려워집니다. git commit --amend 나 rebase 같은 것도 사실은 기존 커밋을 수정하는 게 아니라, 새로운 커밋을 만든 다음 브랜치(ref)를 거기로 옮기는 동작에 가깝습니다.
두 번째로, 히스토리를 안전하게 쌓아 올리는 쪽에 초점이 맞춰져 있다고 생각합니다. 브랜치/태그에서 참조가 끊긴 객체는 나중에 git gc 같은 과정에서 정리되지만, 그 전까지는 그대로 남아 있게 됩니다. 그래서 force-push로 히스토리를 지운 것처럼 보여도, 실제 객체들은 reflog나 GC 설정에 따라 꽤 오래 살아남습니다. 오픈소스에서 커밋 한 번 잘못 남기면 오래 박제되는(?) 이유도 결국 이런 구조 때문이라고 보면 될 것 같습니다.
요약하자면 Git은 빠르게 지우고 덮어쓰는 쪽보다, 계속 쌓아 올리면서 필요에 따라 가리키는 포인터(ref)만 바꾸는 방식으로 히스토리를 관리하는 느낌을 받았습니다.
정리하며
이번 글에서는 Git이 데이터를 어떻게 저장하는지에 집중해서 아래의 내용들을 정리해봤습니다.
- Blob / Tree / Commit 객체 구조
- git cat-file로 내부 객체 추적하기
- 두 커밋 사이에서 어떤 객체들이 재사용/새로 생성되는지
- git diff가 Tree/Blob을 기준으로 어떻게 변경 파일을 찾아내는지
논외로, 부모 커밋을 계속 체이닝하는 구조이기 때문에 자연스럽게 단방향 LinkedList인가? 라고 생각했는데, 조금 더 찾아보니, 보통 Git에서는 이 커밋 구조를 DAG(Directed Acyclic Graph) 라고 부르는 것 같습니다. 아마 한 방향으로만 이어지는 것이 아니라 merge 커밋이 부모를 두 개 이상 가질 수 있기 때문에 전체 구조로 보면 여러 갈래가 합쳐지는 그래프에 더 가까울 것 같다는 생각도 듭니다.
다음 포스팅에서는 merge, rebase와 더불어 이번에 살짝 언급했던 커밋 그래프와 브랜치 쪽을 조금 더 파볼 예정입니다.
References.
https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
https://git-scm.com/docs/git-diff-tree?utm_source=chatgpt.com
https://github.blog/open-source/git/gits-database-internals-i-packed-object-store
