핵심은, 사이드 이펙트가 없는 직렬화를 감지했을 때, Fast Path를 사용할 수 있도록 개선했다는 내용입니다. 여기에 문자열 이스케이프 경로 개선(플랫폼에 따라 SIMD 활용)과 number 처리 최적화가 얹어져 2+a배의 성능 개선이 이루어 졌다고 합니다.
반대로 getter, proxy, 순환참조, toJSON 커스터마이징, pretty print 등 직렬화 과정에서 사이드 이펙트는 Fast Path가 아닌 일반 경로로 폴백합니다. V8의 직렬화 퍼포먼스 개선의 이점을 얻기 위해서는, 개발자가 직렬화 과정에서 사이드 이펙트가 언제 발생하는지 인지하는 게 중요할 것 같습니다.
const N = 200_000;
const safe = Array.from({ length: N }, (_, i) => ({ id: i, ok: true, n: i|0, s: "x" }));
// 1) Fast path 기대 (무부작용)
console.time("safe");
JSON.stringify(safe);
console.timeEnd("safe");
// 2) replacer 사용 → 일반 경로
console.time("replacer");
JSON.stringify(safe, (k, v) => v);
console.timeEnd("replacer");
// 3) space 사용(pretty print) → 일반 경로
console.time("space");
JSON.stringify(safe, null, 2);
console.timeEnd("space");
// 4) toJSON 개입 → 일반 경로
const withToJSON = { ...safe[0], toJSON(){ return "x"; } };
console.time("toJSON");
JSON.stringify(withToJSON);
console.timeEnd("toJSON");
2. Uint8Array 내장 인코딩 지원
ECMAScript에서 최근 Uint8Array에서 직접 Base64, Hex 인코딩/디코딩을 다루는 표준 API가 구현되었습니다. Unit8Array는 바이너리를 다루는 바이트 배열(Typed Array)로 이미지, 파일, 압축, 암호화, 스트리밍 등에 사용되는 바이너리를 다룰 때 기본 자료 구조로 활용되는 것들 중 하나입니다.
25년 9월 기준의 최신 브라우저나 JS 엔진에서 사용 가능하며 자세한 내용은 MDN을 확인해보시면 좋을 것 같습니다.
이번 업데이트로 Node와 브라우저가 동일한 코드를 사용할 수 있게 되었고, 특히 setFromBase64/Hex가 직접 버퍼를 채우는 방식이기 때문에 중간 문자열, 메모리 복사를 줄이고 큰 페이로드에서 GC Pressure을 낮추고, 메모리 사용을 절감할 수 있습니다. 또한 옵션으로 유니온 리터럴 타입을 사용하여 옵션들을 표준화했습니다. 코드 일관성과 퍼포먼스 둘 다 개선했다고 볼 수 있겠습니다.
3. JIT 파이프라인 변경
V8의 JavaScript 실행 파이프라인은 여러 단계로 구성되어있습니다.
Ignition: 인터프리터
SparkPlug: 베이스라인 컴파일러
Maglev: 중간 계층 최적화 컴파일러
TurboFan: 최적화 컴파일러
Maglev는 Chrome M117에 도입된 새로운 최적화 컴파일러로, 기존 SparkPlug와 TurboFan 사이에 위치합니다. 컴파일 속도 측면에서 Maglev는 SparkPlug보다 약 10배 느리고, TurboFan보다 약 10배 빠르다고 합니다. Maglev는 기존 두 컴파일러 사이의 간격을 좁혀 빠른 최적화와 균형 잡힌 성능, 그리고 점진적 워밍업을 제공합니다. 보다 더 자세한 내용은 공식 블로그 내용을 참조하시면 좋습니다.
WASM은 기본적으로 동기적인 실행 모델을 가정합니다. 하지만 웹 환경의 많은 API들은 비동기적입니다. 기존에는 이 문제를 해결하기 위해 Binaryen의 ASYNCIFY 같은 복잡한 변환 도구를 사용해야 했습니다. 이로 인해 코드 크기가 증가하고, 런타임 오버 헤드가 자연스레 증가하며 빌드 프로세스 또한 복잡해지는 문제가 있습니다.
Node 25부터는 JSPI를 통해 WASM 애플리케이션이 동기적으로 작성되어 있더라도, JavaScript의 비동기 API를 자연스럽게 사용할 수 있게 해줍니다.
여기까지가, V8 업데이트로 인한 Node v25의 변경사항입니다. 아래부터는 Node의 별개 커밋들로 변경된 사항들에 대해 알아보겠습니다.
Permission Model: --allow-net 추가
Node는 기본적으로 모든 시스템 리소스에 대한 접근 권한을 갖고 있었습니다. 이는 편리하지만 보안상의 문제가 생길 수 있습니다. 이를 개선하기 위해 Node v20에 Permission Model이 도입되었고, v25에서는 네트워크 권한 제어가 추가되었습니다.
Permission Model을 활성화하면, 명시적으로 허용하지 않은 모든 작업이 차단됩니다.
# Permission Model 없이 (기존 방식)
node index.js # 모든 권한 허용
# Permission Model 활성화 (네트워크 차단됨)
node --permission index.js
# Error: connect ERR_ACCESS_DENIED Access to this API has been restricted.
# 네트워크 권한 허용
node --permission --allow-net index.js # 정상 작동
런타임에서도 권한을 확인할 수 있습니다.
if (process.permission) {
console.log(process.permission.has('net')); // true or false
}
async function fetchData(url) {
if (!process.permission || !process.permission.has('net')) {
throw new Error('Network access not permitted');
}
return fetch(url);
}
ErrorEvent의 글로벌 객체화
브라우저에서는 ErrorEvent 인터페이스가 스크립트나 파일의 에러와 관련된 정보를 제공하는 표준 WEB API입니다. 하지만 Node에서 이를 사용하려면 별도의 polyfill을 설치하고, 브라우저와 Node환경을 분기 처리하며, 플랫폼(OS)별 에러 핸들링 코드를 별도로 작성해야했습니다.
// 기존 방식: 플랫폼 분기
if (typeof ErrorEvent !== 'undefined') {
// 브라우저 환경
window.addEventListener('error', (event) => {
console.log(event.message, event.filename, event.lineno);
});
} else {
// Node.js 환경: 다른 방식 사용
process.on('uncaughtException', (error) => {
console.log(error.message, error.stack);
});
}
Node v25부터 ErrorEvent가 글로벌 객체로 사용 가능합니다. 자세한 구현사항은 아래 커밋을 확인해보시면 좋습니다.
Node v22 이전까지는 localStorage, sessionStorage 같은 WebStorage API를 사용하려면 --experimental-webstorage 플래그가 필요했는데, 이 부분을 Node v25부터는 기본적으로 활성화 상태로 애플리케이션이 실행됩니다. 자세한 변경 내용은 아래 커밋을 확인해보시면 좋습니다.
이를 통해 CI/CD 환경이나 컨테이너, 혹은 협업 과정 등 실제 컴파일이 필요한 테스트, 배포 단계에서 불필요하게 중복 컴파일을 하는 일이 사라지게 될 것으로 기대합니다.
# 1. 로컬 개발
node --compile-cache --compile-cache-portable dev-server.js
# 2. CI/CD 파이프라인 (e.g. Git Actions)
- name: Build and Test
run: |
node --compile-cache --compile-cache-portable build.js
- name: Deploy # 캐시를 아티팩트로 저장
run: |
node --compile-cache app.js # 캐시 재사용으로 빠른 배포
# 3. Docker
FROM node:25
WORKDIR /app
COPY . .
# 빌드 시 캐시 생성
RUN node --compile-cache --compile-cache-portable build.js
# 런타임에서 캐시 활용
CMD ["node", "--compile-cache", "app.js"]
마치며
Node v25의 주요 변경 사항들을, 신규 피쳐 위주로 알아봤습니다. 더 많은 변경사항이 있고, 특히 이 글에서 다루지 않은 Deprecated들을 포함하여 더 자세하게 알고 싶으신 분들은 릴리즈 노트를 활용해보시면 좋을 것 같습니다.
개인적으로 당장 하나씩 씹어먹어보고 싶지만, 11월까지 바쁜 개인 일정을 마무리하고, 나중에 깊게 공부할 수 있도록 주제별로 정리만 간단하게 했습니다. 특히 V8 관련된 공부를 가장 먼저 깊게 해 볼 생각입니다. 메인 스택을 JS, Node으로 계속 갖고 가기 위해 반드시 하나씩 깊게 독파하는 포스팅으로 찾아뵙겠습니다 하하..
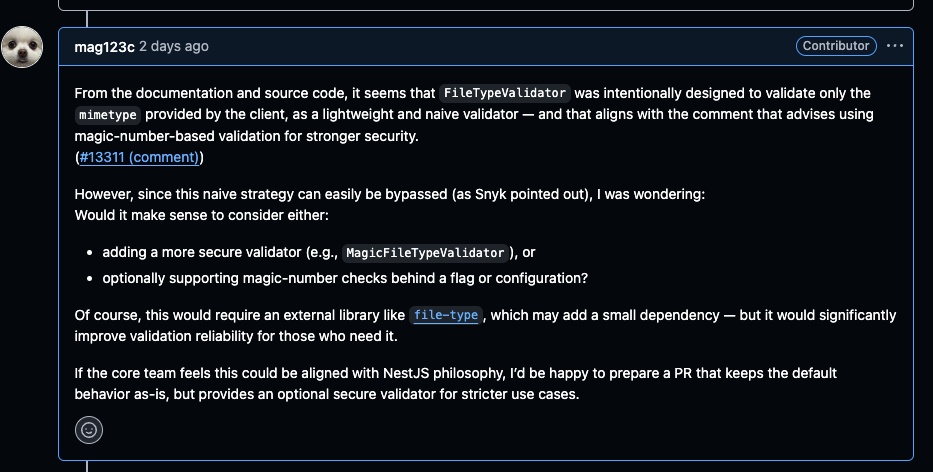
1. NestJS의 내장 FileValidator은 파일 내용을 확인하지 않고 MIME Type만 정규 표현식으로 확인한다. (주석에도 언급되어 있다.)
2. 프로젝트를 구성하는 많은 파이프라인들 중 일부 요소들에서 (Snyk, GitHub Dependabot 등) 보안 취약점이라고 알림이 발생한다. 심할 경우 파이프라인이 제대로 동작하지 않는다.
3. 만약 NestJS에서 수정해야할 경우를 가정하고 작성한 포스팅이다. (파이프라인의 보안 취약점 수정 요청 등을 가정하지 않는다.)
서론
Affected versions of this package are vulnerable to Arbitrary Code Injection via the FileTypeValidator function due to improper MIME Type Validation. An attacker can execute arbitrary code by sending a crafted payload in the Content-Type header of a request.
최근에, NestJS에 제기됐던 FileTypeValidation의 보안 취약점 이슈가 대두되었다. MIME Type을 임의로 주입했을 때 검증할 수 없다는 내용이다.
/**
* Defines the built-in FileType File Validator. It validates incoming files mime-type
* matching a string or a regular expression. Note that this validator uses a naive strategy
* to check the mime-type and could be fooled if the client provided a file with renamed extension.
* (for instance, renaming a 'malicious.bat' to 'malicious.jpeg'). To handle such security issues
* with more reliability, consider checking against the file's [magic-numbers](https://en.wikipedia.org/wiki/Magic_number_%28programming%29)
*
* @see [File Validators](https://docs.nestjs.com/techniques/file-upload#validators)
*/
export class FileTypeValidator extends FileValidator<
FileTypeValidatorOptions,
IFile
> {
buildErrorMessage(file?: IFile): string {
if (file?.mimetype) {
return `Validation failed (current file type is ${file.mimetype}, expected type is ${this.validationOptions.fileType})`;
}
return `Validation failed (expected type is ${this.validationOptions.fileType})`;
}
isValid(file?: IFile): boolean {
if (!this.validationOptions) {
return true;
}
return (
!!file &&
'mimetype' in file &&
!!file.mimetype.match(this.validationOptions.fileType)
);
}
(예를 들어, 'malicious.bat'을 'malicious.jpeg'로 이름을 바꾸는 것입니다). 이러한 보안 문제를 해결하기 위해 더 신뢰성 있게 파일의 [magic-numbers] 을 확인해 보세요
import { FileTypeValidator, MaxFileSizeValidator, ParseFilePipe, UploadedFile } from '@nestjs/common';
export function CustomImageValidator(
maxSize: number = 1024 * 1024 * 15 + 1,
// application\/x-msdownload 추가
fileType: RegExp = /^(image\/jpg|image\/jpeg|image\/png|image\/gif|image\/bmp
|image\/svg\+xml|application\/x-msdownload)$/i,
) {
return UploadedFile(
new ParseFilePipe({
validators: [
new MaxFileSizeValidator({ maxSize }),
new FileTypeValidator({ fileType }),
],
}),
);
}
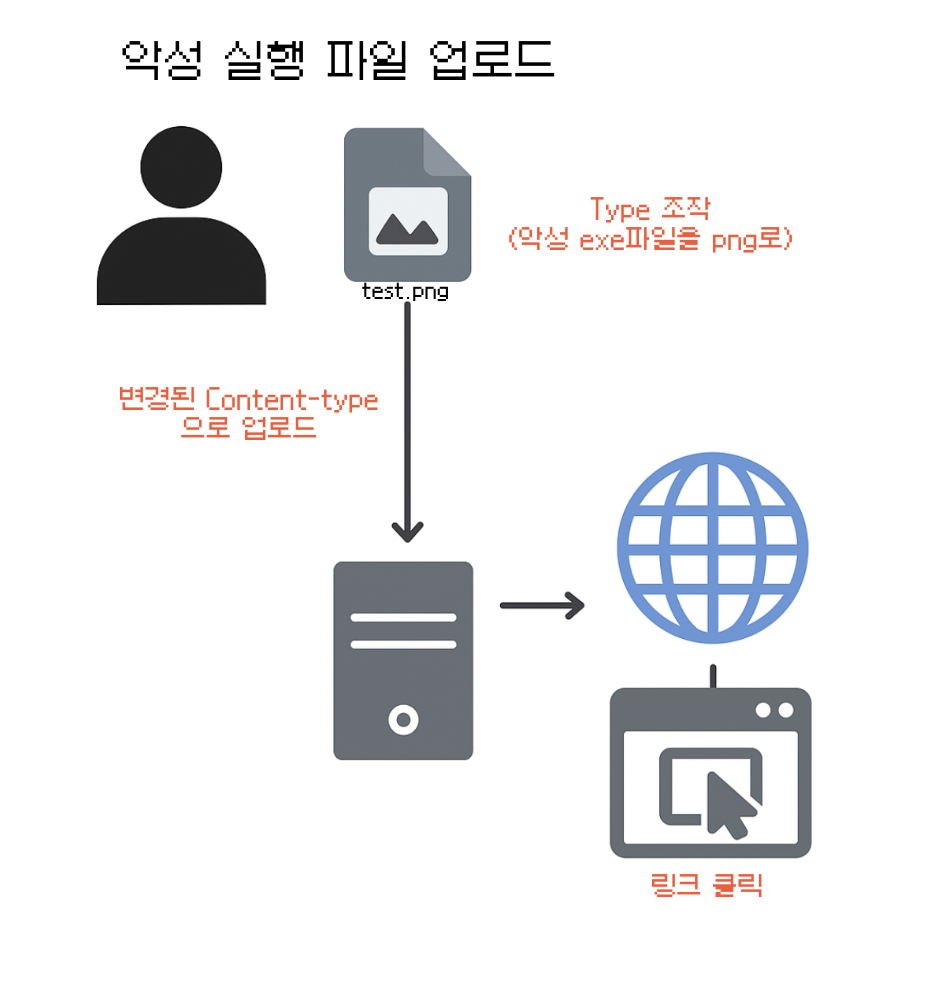
// 파일 업로드 시 Content-Type 조작
const fakeFile = new File([file], file.name, {
type: "application/x-msdownload", // .exe MIME
});
테스트를 위해 간단하게 프로필 이미지 업로드 코드를 만들고, 실제로 클라이언트에서 Content-Type을 조작한 뒤 파일을 업로드하게되면, 서버에 파일이 올바르게(?) 전달되게 되고 뒤 프로세스들이 그대로 실행되는 모습을 볼 수 있었다.
그래서 뭐가 문제임?
그렇다면 이게 왜, 어떤 문제가 되어 보안 취약점이라고 계속해서 말하는걸까?
실제로 업로드된 파일의 내용을 보면, 파일은 PNG 이미지이지만, MIME Type은 application/x-msdownload로 설정되어 있었다.
서버는 이 MIME Type을 믿고 x-msdownload 확장자로 저장했고, 앞의 벨리데이션을 통과했기 때문에 이후 로직에서도 별다른 제약 없이 이 파일을 처리하게 된다.
서버는 신뢰할 수 없는 Content-Type값을 기준으로 벨리데이션을 처리했다. NestJS의 FileTypeValidator은 정의한 정규표현식을 통해서 파일의 타입을 단순 문자열 비교만 수행한다. 이 문자열 타입은 클라이언트에서 조작이 가능하므로 기본적으로 취약한 구조가 된다.
가상의 시나리오를 하나 구성해보았다. 공격자가 악성 실행 파일을 png인 것으로 인식하게끔 Content-Type만 위변조하여 업로드하였다. 나는 올바르게 ImageValidation Type을 설정했지만 서버 내부의 FileTypeValidator은 PNG로 인식하기 때문에 올바르게 벨리데이션을 통과하게 되며 이는 곧 서버와의 상호작용을 통해 어딘가 저장됨을 의미한다.
저장된 이 파일이 사용자에 의해 다시 실행되게 되면?? XSS, RCE(Remote Code Execution)등의 취약점이 발생하게 된다.
이 문제의 본질은, 계속 강조했던 것 처럼 서버가 신뢰할 수 없는 Content-Type값을 기준으로 벨리데이션을 수행하기 때문에 발생하는 문제이다. 이 MIME Type은 클라이언트가 조작이 가능하기 때문에 신뢰할 수 없다. NestJS에서는 이러한 MIME Type에 대한 정규표현식 검증만 수행하기 때문에 취약한 구조일 수 밖에 없다.
어떻게 개선할까?
이 문제를 해결하기 위해서는, Content-Type에 의존하는 것이 아닌, 파일의 실제 내용을 기반으로 판단해야한다.
파일 바이너리의 시작 부분에는 파일 형식을 식별하는 시그니처(Magic Numbers)가 들어있다. 예를들어 JPEG 이미지는 0xFFD8로 시작하고, PNG는 항상 0x89504E47로 시작한다. 매직 넘버는 파일의 형식을 정확하게 식별하는데 이미 널리 사용되고 있다.
이 문제를 처음 접했을 때 NestJS에서 작성 해 놓은 주석을 기반으로 나도 Magic Number을 사용할 수 있도록 개선하고자 했다. FileValidator라는 공통 인터페이스가 있으니, FileMagicTypeValidator같은 것을 확장해서 구현하려고 방향성을 정한 뒤 PR을 작성하기 전 NestJS의 개발 방향과 일치하는지 이슈 코멘트에 방향성을 재확인받고자 코멘트를 작성했다.
하지만 다른 누군가가 바로 PR을 올려버렸기 때문에 아쉽지만 기여에는 실패한 것 같다.
NestJS의 기존 의존성들에는, 이러한 파일 벨리데이션을 해결해줄 수 있는 라이브러리가 존재하지 않기 때문에, Node 진영에서 가장 많이 쓰이는 라이브러리 중 하나인 file-type을 사용하여 해결하고자 했다.
이미지 파일의 경우 - 이미지 변환, 리사이징 등을 통해 정말 이미지 파일이 맞는지 검증해보기
등의 추가 개선을 자체 서버에서 구현할 수도 있지 않을까? 라는 생각을 해본다.
마무리하며
우선, 오픈소스 PR은 올린 사람이 임자(?) 라는 것을 다시금 깨닫는다. 간만에 기여할 거리가 생겼는데 엄청 아쉽다.
이번 이슈는 단순히 NestJS에 보안 취약점이 있다. 라는 수준을 넘어서, 서버 사이드에서 클라이언트 입력값을 얼마나 신중하게 다뤄야하는지를 조금이나마 일깨워줬다. MIME Type은 단순히 HTTP 요청에 포함된 단순한 문자열일 뿐이고, 이를 신뢰할 경우 우리는 의도치 않게 악성 파일을 통과시킬 수도 있다.
NestJS에서도 이를 사전에 인지했기 때문에 주석을 통해 명시적으로 사용자들에게 알렸다. 결국 중요한 건 사용자 개개인이 어느 수준까지 보안을 신경쓰고 코드를 작성할까? 라는 인지를 하고 코드를 써내려가는 것 아닐까?
이전 포스팅에서 NestJS 11의 릴리즈 노트 중 부트스트랩 최적화에 대해 다뤘다. 모듈을 식별하는 Opaque Key 생성 알고리즘의 개선으로 모듈을 읽어들이는 속도가 대폭 향상되었다고 나와 있었다.
하지만 최근 NestJS 11로 업데이트한 이후, AppModule 초기화 속도가 급격히 느려지는 이슈가 발생했다. 10버전에서 55ms였던 초기화 시간이 11버전에서는 50초 ~ 80초까지 증가하며 성능 저하 문제가 제기되었다.
저번 포스팅에서는 Opaque Key 최적화로 부트스트래핑 속도를 개선하는 방법을 살펴봤다면, 이번 포스팅에서는 AppModule의 의존성 초기화 과정에서 발생한 성능 이슈와 Nest에서 이를 어떻게 해결하였는지에 대해 분석해봤다
11.0.9
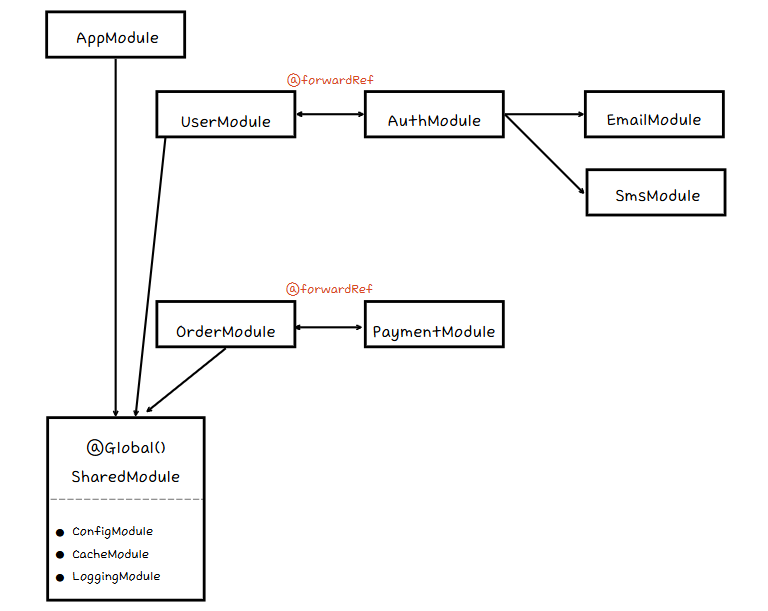
위에서 언급한 의존성 초기화 속도 개선을 위해 Nest에서는 topology tree를 사용하는 방식을 선택했다. 소스 코드 분석과 더불어 간단한 결제 모듈 구조를 통해 어떻게 개선되었는지 알아보고자 했다. 결제 모듈의 구조는 순환 의존과 더불어 글로벌 모듈을 사용했다. (개인적으로는 최대한 단방향 의존을 사용하려고하고 서비스가 확장됨에 따라 양방향 의존이 불가피할 경우 중간 레이어를 하나 더 두는 형태로 개발하고 있다.)
기존 - DFS
기존에는 DFS(깊이 우선 탐색) 기반 재귀 호출 방식을 사용하여 모듈 간의 거리를 계산했다. DFS의 특성상, 이미 방문한 모듈도 다시 탐색하는 경우가 많아지고, 불필요한 연산이 많아지는 문제가 발생했다. 또한, 모듈이 많아질수록 DFS의 호출 스택이 깊어져 스택 오버플로우 위험도 존재했다. 특히 순환 참조가 발생하는 경우, 무한 루프에 빠질 가능성이 높아, 안정적인 부트스트래핑이 어려워지는 문제가 있었다.
Nest의 DependenciesScanner는 의존성 관리를 위한 클래스이다. 모듈 초기화 순서를 결정하기 위해 모듈 간의 거리를 계산한다. 이 과정이 없다면 초기화 순서가 꼬이면서 앱이 실행되지 않을 것이다. 의존성이 있는 모듈을 먼저 초기화해야 이후 다른 모듈에서 정상적으로 주입이 가능한 것이다.
코드를 보면 알겠지만, 기존의 모듈의 거리를 계산할 때 calculateDistance라는 내부 함수의 재귀 호출을 통해 거리를 계산한다. 위 코드의 주석처럼, 1 ~ 5의 과정을 모든 모듈을 하나씩 방문하면서 DFS를 돌리는 것이다. 글로벌 모듈에 대한 동작을 수행하지 않는 등의 성능에 신경 쓴 부분도 보이지만, 근본적으로 서비스가 커짐에 따라 DFS 자체가 부담이 된다. 이슈에서처럼 AppModule의 초기화 시간이 80초나 걸린 것만 봐도 알 수 있다.
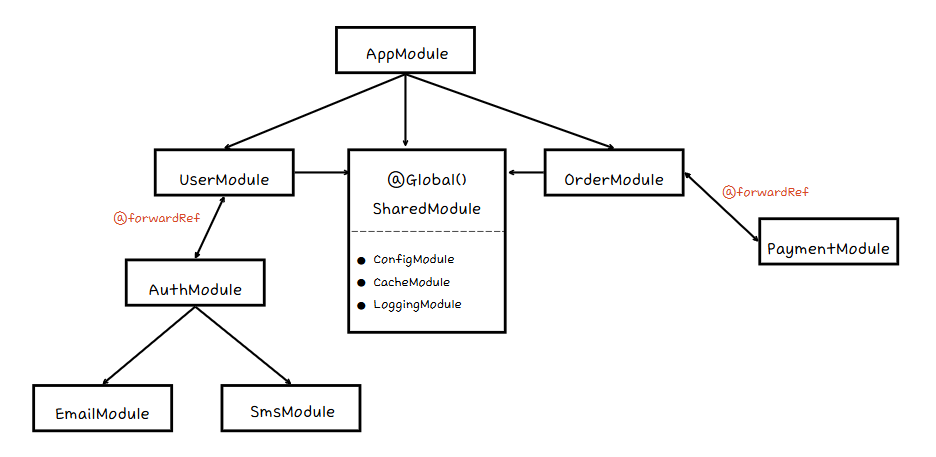
SharedModule의 위치가 이상하지만 AppModule의 하위 모듈로 이해해주세요.
정리하자면, 기존의 모듈 거리 계산 방식은 DFS를 통한 그래프 형태로 모듈 간의 거리가 계산된다. 중복 방문이 필연적이며 모듈에서 의존하는 것이 많아지고, 서비스가 확장됨에 따라 앱 초기화에 필요한 시간은 훨씬 길어지게 된다. 이런 문제들로 55ms였던 AppModule의 의존성 초기화 시간이 80000ms까지 대폭 상승했었던 것으로 보인다.
트리 구조로의 개선
새로운 방식에서는 TopologyTree를 도입하여 DFS 방식의 재귀 호출을 제거하고, 모듈 간 관계를 트리 구조로 변환하여 반복 탐색하는 방식으로 변경했다.
export class TopologyTree {
private root: TreeNode<Module>;
private links: Map<Module, TreeNode<Module>> = new Map(); // 1.빠른 탐색을 위한 해시 테이블
constructor(moduleRef: Module) {
this.root = new TreeNode<Module>({ value: moduleRef, parent: null });
this.links.set(moduleRef, this.root); // 2.해시 구조로 저장하여 중복 방지
this.traverseAndMapToTree(this.root);
}
public walk(callback: (value: Module, depth: number) => void) {
function walkNode(node: TreeNode<Module>, depth = 1) {
callback(node.value, depth); // 3. 거리(distance) 계산
node.children.forEach(child => walkNode(child, depth + 1));
}
walkNode(this.root);
}
private traverseAndMapToTree(node: TreeNode<Module>, depth = 1) {
if (!node.value.imports) return;
node.value.imports.forEach(child => {
if (!child) return;
if (this.links.has(child)) { // 4.이미 존재하는 모듈인지 확인
const existingSubtree = this.links.get(child)!;
if (node.hasCycleWith(child)) return; // 5.순환 참조 감지 (사이클 방지)
const existingDepth = existingSubtree.getDepth();
if (existingDepth < depth) {
existingSubtree.relink(node); // 6.기존 트리 노드 재연결
}
return;
}
const childNode = new TreeNode<Module>({ value: child, parent: node });
node.addChild(childNode);
this.links.set(child, childNode);
this.traverseAndMapToTree(childNode, depth + 1);
});
}
}
export class TreeNode<T> {
public readonly value: T;
public readonly children = new Set<TreeNode<T>>();
private parent: TreeNode<T> | null;
constructor({ value, parent }: { value: T; parent: TreeNode<T> | null }) {
this.value = value;
this.parent = parent;
}
addChild(child: TreeNode<T>) {
this.children.add(child);
}
removeChild(child: TreeNode<T>) {
this.children.delete(child);
}
relink(parent: TreeNode<T>) {
this.parent?.removeChild(this);
this.parent = parent;
this.parent.addChild(this);
}
getDepth() {
let depth = 0;
let current: TreeNode<T> | null = this;
const visited = new Set<TreeNode<T>>();
while (current) {
depth++;
current = current.parent;
if (visited.has(current!)) return -1; // 1.순환 참조 감지
visited.add(current!);
}
return depth;
}
hasCycleWith(target: T) {
let current: TreeNode<T> | null = this;
const visited = new Set<TreeNode<T>>();
while (current) {
if (current.value === target) return true;
current = current.parent;
if (visited.has(current!)) return false;
visited.add(current!);
}
return false;
}
}
public calculateModulesDistance() {
const modulesGenerator = this.container.getModules().values();
// Skip "InternalCoreModule"
// The second element is the actual root module
modulesGenerator.next();
const rootModule = modulesGenerator.next().value!;
if (!rootModule) {
return;
}
// Convert modules to an acyclic connected graph
const tree = new TopologyTree(rootModule);
tree.walk((moduleRef, depth) => {
if (moduleRef.isGlobal) {
return;
}
moduleRef.distance = depth;
});
}
TreeNode 클래스를 사용하여 각 모듈을 트리 노드로 변환
walk()를 활용하여 BFS처럼 반복 탐색
hasCycleWith() 메서드를 사용하여 순환 참조를 사전에 방지
결과적으로 O(n²)에서 O(n)으로 최적화되었으며, 중복 방문 없이 일정한 성능을 유지할 수 있게 되었다.
정리
이번 업데이트를 통해 대규모 애플리케이션에서도 모듈 간 의존성을 더욱 효율적으로 관리할 수 있게 되었다. 기존 DFS 기반 탐색 방식에서 발생하던 불필요한 중복 방문으로 인한 성능 이슈를 TopologyTree 기반 반복 탐색 방식으로 성능이 대폭 향상된 것으로 보인다.
(실제로 이슈의 코멘트 중 업데이트를 적용하고 35초에서 145ms로 단축되었다.)
기존 방식(DFS)
새로운 방식 (Topology Tree)
탐색 방식
DFS (깊이 우선 탐색, 재귀 호출)
트리 기반 반복 탐색 (walk())
중복 방문 문제
여러 번 방문 가능
한 번만 방문
순환 참조 감지
제한적 (modulesStack 사용)
hasCycleWith() 사용
스택 오버플로우 위험
있음 (재귀 호출)
없음 (반복 탐색)
성능
O(n²) (중복 탐색 발생)
O(n) (최적화된 탐색)
거리 계산 방식
재귀 호출로 계산
BFS처럼 walk()로 계산
언제나 issue가 있으면 기여해보고자 하는 생각에 레포를 꾸준히 방문하다보니 재밌는 이슈거리가 있어 자연스레 들여다봤던 시간이었다. 오픈 소스의 코드 컨벤션부터 시작해서 개발 방향, 의도 등이 코드에 드러나기 때문에 기여를 할 때도 보다 더 수월하게 할 수 있지 않을까? 다양한 사람들의 여러 관점에서의 이슈 분석을 보고 같이 토론하면서 하드 스킬 뿐 아니라 소프트 스킬도 키우고 겸사겸사 고수들의 코드도 공짜로 볼 수 있고 말이다 ㅋㅋ..
Nest v11의 릴리즈노트를 보며, Express v5의 도입과 더불어 Node 20버전 미만은 지원을 중단하는 등의 패치 내용을 죽 읽어보다가, imporove bootstrap perfomance라고 적힌 Features가 눈에 띄었다. 앱을 실행하는, 가장 핵심적인 코어의 기능이 개선되었다고 하는데, 어떤 변화가 있었길래 전반적인 앱 실행 속도가 향상되었는가에 대한 궁금증에 적당히 파헤쳐보고자 한다.
불투명 키 알고리즘의 추가로 앱 실행속도 향상
Nest v11에서는 모듈 간의 고유성을 보장하기 위한 기존의 불투명 키(Opaque key)생성 방식이 개선되어 동적 모듈과 대규모 애플리케이션에서 직렬화 비용이 대폭 줄어 부트스트래핑 성능이 향상되었다고 한다.
NestJS는 IOC 컨테이너에서 모듈을 고유하게 식별하기 위해 불투명 키를 사용한다. 이 키는 모듈의 메타데이터를 기반으로 생성되며 각 모듈을 정확히 구분하는 역할을 한다.
Nest v10: 직렬화 기반 키 생성
Nest v10에서는 모듈의 불투명 키(Opaque Key - 고유 식별자)를 생성하기 위해 전체 모듈 메타데이터를 해싱하는 방식이 사용되었다. 이 방식의 문제점은 해싱 알고리즘이 모듈 메타데이터의 전체를 읽어 이를 바탕으로 고유 해시를 생성했는데, 이로 인해 동적 모듈의 규모가 클 수록 해시 생성 속도가 느려지는 오버헤드가 발생했다. 또한 모든 메타데이터를 직렬화한 뒤 해싱하는 방식이 불필요하게 복잡해 규모가 클수록 오버헤드는 더욱 심해졌다.
TypeORM 모듈에 여러 엔터티를 포함시킨 동적 모듈의 경우, 이를 여러 모듈에서 동시에 사용할 수 있다. 예를 들어, 유저 모듈에서 UserEntity를 사용하지만, 다른 모듈에서 유저 모듈을 임포트할 경우, Entity만 사용할 경우, 최악으로 UserModule 자체를 @Global으로 두어 사용하는 경우 모두 해당된다. 이 때 Nest는 각 모듈의 동적 메타데이터를 해싱하여 불투명 키를 생성한 뒤, 이를 기준으로 중복을 제거하고 단일 노드로 처리했다. 하지만 위의 예시처럼 UserModule 내의 엔터티들이 많아질 수록, 직렬화와 해싱 작업이 가중되어 오버헤드가 점점 심해지게 된다.
v11에서는 ByReferenceModuleOpaqueKeyFactory를 도입하여 더 간단한 방식으로 모듈의 불투명 키를 생성한다. 객체 참조를 통해 불투명 키를 생성하는데, 이는 메타데이터를 직렬화하거나 해시를 계산하지 않고 모듈 객체의 참조값을 직접 식별자로 사용한다. 객체 참조를 통해 이미 고유성을 가지기 때문에 복잡한 해싱 로직이 없어도 정확히 모듈을 구별할 수 있고, 이로 인해 모든 메타데이터를 직렬화하고 해싱하지 않아 실행 성능이 많이 개선되었다고 한다.
v10에서 언급한 TypeORM의 예시에서, v11에서는 모듈의 객체 참조 변수에 할당하고, 이를 여러 모듈에서 재사용하면서 자연스럽게 중복이 제거되게 된다.
추가된 코드들을 간단히 살펴보자. 우선 새롭게 추가된 모듈 식별자를 생성하는 방식을 정의하는 알고리즘 옵션이 추가되었다.
export class NestApplicationContextOptions {
/**
* Determines what algorithm use to generate module ids.
* When set to `deep-hash`, the module id is generated based on the serialized module definition.
* When set to `reference`, each module obtains a unique id based on its reference.
*
* @default 'reference'
*/
moduleIdGeneratorAlgorithm?: 'deep-hash' | 'reference';
}
default가 reference로 설정되어있기 때문에, 위에서 설명한 객체 참조를 기반으로 식별자를 생성하게 되었다. 변경된 버전에서는, 객체 참조만을 사용해 기존의 키를 가져오거나, 생성하기만 하면된다.
// Class ByReferenceModuleOpaqueKeyFactory
public createForStatic(
moduleCls: Type,
originalRef: Type | ForwardReference = moduleCls,
): string {
return this.getOrCreateModuleId(moduleCls, undefined, originalRef);
}
// 동적 모듈의 경우 실제 모듈은 제외하고
// providers, imports등의 메타데이터만 포함하여 키를 생성한다.
public createForDynamic(
moduleCls: Type<unknown>,
dynamicMetadata: Omit<DynamicModule, 'module'>,
originalRef: DynamicModule | ForwardReference,
): string {
return this.getOrCreateModuleId(moduleCls, dynamicMetadata, originalRef);
}
참조 키를 생성할 때, 랜덤 문자열을 기본적으로 사용하여 직렬화를 가능한 회피하려고 했고, 동적 메타데이터가 없는 경우에는 직렬화를 완전히 배제하려고 한 것 같다.
[Nest] Localstack으로 AWS S3 파일 업로드, 삭제, 다운로드 및 테스트 코드 작성하기
Tech/NodeJS2025. 1. 24. 00:16
728x90
728x90
서론
최근에 사이드 프로젝트에서 S3 버킷에 파일을 업로드해야 하는 일이 생겼고, 자연스럽게 통합 테스트를 작성해야 할 상황이 됐다. 하지만 실제 AWS S3 환경에서 테스트를 작성하는 데는 몇 가지 현실적인 문제들이 예상됐다.
1. 비용 문제 S3는 사용량 기반으로 요금이 부과되기 때문에, 테스트가 자주 실행되는 환경에서는 비용이 계속 쌓일 가능성이 있다. 특히, 개발하면서 테스트를 반복적으로 실행하다 보면 생각 이상으로 비용이 발생할 수밖에 없다. 현재 사이드프로젝트의 테스트코드 실행 주기가 pre-commit에만 달려있어도, 하루에 십 수번은 넘게 실행되고 있다.
2. 보안 문제 테스트 환경에서 IAM의 Access Key와 Secret Key를 사용하는 건 보안상 굉장히 위험할 수 있다. 키가 노출되면 프로젝트뿐만 아니라 AWS 계정 전체에도 영향을 줄 수 있다.
3. 정합성 문제 프로덕션과 테스트 환경이 같은 S3 버킷을 공유한다면, 테스트 중 파일 업로드나 삭제가 프로덕션 데이터에 영향을 미쳐 정합성을 깨트릴 가능성이 있다. 이건 최악의 상황을 초래할 수도 있다.
그래서 이러한 문제를 해결하기 위해 LocalStack을 사용했다. LocalStack은 로컬 환경에서 AWS 서비스를 에뮬레이션할 수 있는 도구로, S3뿐만 아니라 DynamoDB, Lambda 같은 다양한 AWS 리소스를 로컬에서 테스트할 수 있게 해준다. LocalStack을 활용해서 S3 업로드 기능에 대한 통합 테스트를 작성했는데, 공식 문서가 너무 잘 되어있어 쉽게 적용해볼 수 있었다.
Localstack 실행
docker-compose를 통해 테스트 실행 전 활성화를 시켜놓았다. 테스트 시작 구문에서 LocalStack 컨테이너를 세팅해보았으나 한 번에 5초 이상 걸렸다. 초기화 시 매번 세팅해주기에는 테스트 파일이 많아질수록 실행 속도가 느려질 것 같다.
LocalStack 덕분에 실제 AWS를 사용하지 않고도 비슷한 인프라로 S3 버킷의 테스트를 작성할 수 있었다. 무엇보다도 테스트를 반복 실행하더라도 비용이 발생하지 않는다는게 현재 사이드프로젝트에서는 큰 장점인 것 같다.
사실 오늘 처음 LocalStack을 알았는데, 바로 적용이 가능한 데에는 공식문서가 잘 되어있다는 점이 가장 컸다. 다른 AWS의 리소스들도 무료로 지원해주는 게 생각보다 많기 때문에 AWS를 사용할 때 테스트코드 작성에 대한 부담을 느껴 모킹해버리는 경우가 많이 줄어들 것 같다.
최근 신입 개발자분이 입사하셨다. TypeORM을 사용해서 특정 기능을 구현하던 도중, 계속해서 하위 테이블에서 상위 테이블의 FK가 NULL로 들어가는 문제가 있었다. 구현하신 로직을 따라가면서 문제점을 발견할 수 있었는데, 기존에 하위 모델에서 가지고 있는 상위 모델 객체의 정보를 저장 직전에 ORM의 create 인터페이스로 새로 생성하여 저장했기 때문이다.
현재 내가 개발중인 도메인의 테이블들은 대부분 비정규화가 심한 테이블들이여서 ORM에서 관계를 매핑해주지 않고 ORM의 인터페이스 혹은 raw query로 JOIN을 수행하고 있다. 이렇다보니 한 번에 무엇이 문제인지 찾을 수 없었다. 사용하고 있는 특정 기술들 중 핵심적인 ORM이기 때문에, 이번 일을 계기로 하나하나 직접 사용하며 정리해보면서 나에게, 또 누군가에게 레퍼런스가 되었으면 한다.
@Entity('user')
export class User {
@PrimaryGeneratedColumn('increment', { unsigned: true })
id!: number;
@Column({ type: 'varchar' })
name!: string;
@Column({ type: 'varchar' })
email!: string;
//soft delete를 위한 컬럼이 아닌, update cascade를 위한 필드
@Column({ type: 'boolean', default: false })
deleted!: boolean | null;
@DeleteDateColumn({ type: 'datetime', precision: 0, nullable: true, default: null })
deletedAt!: Date | null;
@OneToMany(() => Post, (post) => post.user)
posts?: Post[];
}
보통 위와 같이, 관계를 설정해주면 런타임 시에 ORM에서 데코레이터를 기반으로 각 엔터티들을 읽고 데이터베이스에 직접 테이블을 생성/수정하게 된다. Post에 굳이 userId 컬럼을 직접 명시해주지 않아도 user의 PK값이 자동으로 FK로 설정되며, 디폴트로 모델명_PK명이 생성된다.
user에서, user아님으로 필드명을 변경해주자 아래처럼 FK 변경을 위해 작업을 추가로 수행한다.
cascade는 연관된 엔터티가 삽입, 수정, 삭제될 때 자동으로 전파되도록 설정하는 옵션이다. TypeORM에서 엔터티를 처리하는 방식을 제어하기 위해 사용된다. 쉽게 말해 코드레벨에서의 자식 엔터티로의 추가 작업을 전파하는 방법이며, 실제 데이터베이스의 제약 조건에는 영향을 끼치지 않는다. 또한 반드시 명시적으로 상태를 정의하거나, 변경해주어야 동작한다.
양방향에 cascade 제약 조건을 사용할 경우 순환 에러가 발생한다. 재귀적으로 상위가 하위에 전파된 동작을 하위에서 다시 상위로 전파하기 때문이다.
insert
@Entity('user')
export class User {
@OneToMany(() => Post, (post) => post.user, { cascade: 'insert' })
posts?: Post[];
}
it('CASCADE INSERT:: 유저 엔터티 내부에서 포스트 엔터티를 같이 생성할 수 있다.', async () => {
// given
const post = postRepo.create({
title: 'test',
content: 'test',
});
const user = userRepo.create({
name: 'test',
email: 'test@test.com',
posts: [post],
});
// when
await userRepo.save(user);
const userResult = await userRepo.find({ relations: ['posts'] });
expect(userResult).toHaveLength(1);
expect(userResult[0].posts).toHaveLength(1);
});
user 객체에 정의된 posts를 정의하고user를 save할 경우, post도 같이 저장된다.
update
@Entity('user')
export class User {
@OneToMany(() => Post, (post) => post.user, { cascade: 'update' })
posts?: Post[];
}
@Entity('user')
export class User {
@OneToMany(() => Post, (post) => post.user, { cascade: 'update' })
posts?: Post[];
}
it('CASCADE UPDATE:: 유저의 isActive 상태 변경이 포스트에 전파된다.', async () => {
// given
const post = postRepo.create({
title: 'test',
content: 'test',
});
const user = userRepo.create({
name: 'test',
email: 'test@test.com',
posts: [post],
});
// when
await userRepo.save(user);
// when
const userResult = await userRepo.findOneOrFail({ where: { id: user.id }, relations: ['posts'] });
userResult.deleted = true; // 유저 상태 변경
if (userResult.posts) {
userResult.posts[0].deleted = true; // 포스트 상태 변경
}
await userRepo.save(userResult);
// then
const postResult = await postRepo.findOneOrFail({ where: { id: post.id } });
expect(postResult).toBeDefined();
expect(postResult?.deleted).toBe(true);
});
강제로 업데이트 상황을 만들어보기위해 어거지로 deleted를 업데이트 시켜주었다.
user가 update될 때, posts를 감지하여, 업데이트 된 변경사항이 있으면 자동으로 반영해준다.
remove
다들 짐작하겠지만 데이터베이스 레벨에서의 제약 조건을 설정하지 않았기 때문에, TypeORM이 정의하는 기본 옵션으로 정의된다. 하위 테이블에서 FK를 참조할 때,ON DELETE, ON UPDATE가 NO ACTION으로 정의된다.
위에서도 얘기했듯이, cascade는 단순 ORM에서 코드 동작을 정의하는 것이다. 그렇기 때문에 DB에서 DELETE에 대해 부모 레코드를 삭제할 수 없다는 에러를 반환하게 된다.
@Entity('user')
export class User {
@OneToMany(() => Post, (post) => post.user, { cascade: 'delete' })
posts?: Post[];
}
it('CASCADE REMOVE:: 유저 엔터티를 삭제하면 포스트 엔터티도 같이 삭제된다.', async () => {
// given
const post = postRepo.create({
title: 'test',
content: 'test',
});
const user = userRepo.create({
name: 'test',
email: 'test@test.com',
posts: [post],
});
await userRepo.save(user);
// when
await userRepo.remove(user);
const userResult = await userRepo.find();
const postResult = await postRepo.find();
expect(userResult).toHaveLength(0);
expect(postResult).toHaveLength(0);
});
그렇기 때문에, 반드시 하위 테이블에 onDelete를 설정하여 DB에 제약조건을 걸어주도록 하자.
@Entity('post')
export class Post {
@ManyToOne(() => User, (user) => user.posts, { onDelete: 'CASCADE' })
user!: User;
}
soft-remove
/**
* Records the delete date of a given entity.
*/
softRemove<T extends DeepPartial<Entity>>(entity: T, options?: SaveOptions): Promise<T & Entity>;
TypeORM에는 soft delete를 위해 softRemove 인터페이스를 제공한다.
이 softRemove는 @DeleteDateColumn 데코레이터가 달린 날짜 형태의 필드를 제어하여 soft delete를 구현하도록 되어있다. 조회 관련 인터페이스에서는, 이를 기본적으로 조회하지 않도록 되어있으며, soft delete된 레코드 까지 조회하기 위해서는 withDeleted를 true로 지정해서 조회해야한다.
/**
* Indicates if soft-deleted rows should be included in entity result.
*/
withDeleted?: boolean;
이제 cascade를 사용해서, soft-remove를 하위 테이블까지 전파해보려고 한다.
@Entity('user')
export class User {
@DeleteDateColumn({ type: 'timestamp', default: () => 'CURRENT_TIMESTAMP' })
deletedAt!: Date;
@OneToMany(() => Post, (post) => post.user, { cascade: ['soft-remove'] })
posts?: Post[];
}
단순 컬럼값을 제어하는 것이지 실제 삭제하는 것이 아니기 때문에, 하위 테이블에 ON DELETE 제약 조건을 걸 필요는 없다. 하지만 반드시 cascade를 soft-remove만 사용해야 하는 상황이라면 반드시 soft-remove 전에 엔터티 객체에 관계 명시를 해준 후에 삭제를 해야한다.
다소 불편한 것 같아서, 이슈를 찾아봤는데 이미 4~5년 전에 발행된 이슈가 있었다. 아직 미해결인 것 같지만 해결책이 없는 것 같아 각자의 방법대로 사용중인 것 같았다. 보통은 cascade를 true로 사용하면서, soft-remove를 사용하며, 실제 TypeORM의 soft-remove 테스트 코드도 그렇게 적용되어 있다. 나도 이슈에 코멘트를 달아놓고, 실제로 삭제할법한 두 가지의 상황을 가정하여 위 테스트 코드의 when 절을 변경해보았다. 두 가지 모두 삭제하기 위해 PK를 받아와서 삭제하는 상황이다.
// when
// 가능한 방법, 실제로 관계 명시를 통해 엔터티 객체를 그대로 삭제하여 하위 엔터티까지 영향
const fetchedUser = await userRepo.findOneOrFail({ where: { id: user.id }, relations: ['posts'] });
await userRepo.softRemove(fetchedUser); // 소프트 삭제
// userId에 해당하는 테이블만 삭제하기 때문에, 하위 테이블에 영향 X
await userRepo.softDelete(user.id);
두 번째 방법이 동작하지 않는 이유는, 위에서 언급했듯 명시적으로 관계를 정의하지 않았기 때문인 것 같다.
recover
recover은 soft-remove로 인해 삭제되었던 레코드를 삭제되지 않은 상태로 복구하는 기능이다.
TypeORM의 recover 인터페이스를 사용하면되고, 거의 모든 상황에서 soft-remove와 같이 사용한다.
nullable
/**
* Indicates if relation column value can be nullable or not.
*/
nullable?: boolean;
부모 자식 관계에서 자식 엔터티가 부모 엔터티가 nullable할 수 있기 때문에 이를 설정해주는 값이다.
@Entity('post')
export class Post {
@ManyToOne(() => User, (user) => user.posts, { nullable: true })
user?: User;
}
이를 통해 Post 엔터티에서 user_id 필드가 NULLABLE할 수 있다.
onDelete, onUpdate
cascade는 TypeORM이 코드 레벨에서 제약조건에 따른 이후 행동들을 정의한 것이라면, 이 두 옵션은 실제 데이터베이스에서 부모 엔터티의 행동에 따라 자식 엔터티의 외래 키를 어떻게 처리할지 결정한다. 실제 데이터베이스의 외래 키 제약 조건을 지정하는 옵션으로 앞, 뒤의 설정들은 모두 코드 레벨에서 동작을 정의하지만 유일하게 데이터베이스에 적용되는 옵션이다.
onDelete
CASCADE: 부모 엔터티 삭제 시 자식 엔터티도 삭제
SET NULL: 부모 엔터티 삭제 시 자식 엔터티의 참조 키를 NULL로 설정
RESTRICT: 부모 엔터티가 자식 엔터티와의 관계를 유지하고 있을 경우 삭제 불가능
onUpdate
CASCADE: 부모 엔터티의 키가 변경될 때 자식 엔터티의 참조 키도 같이 변경됨
RESTRICT: 부모 엔터티의 키가 변경되면 에러 발생
deferrable
/**
* Indicate if foreign key constraints can be deferred.
* IMMEDIATE: 변경 사항 발생 시 즉시 확인한다.
* DEFFRRED: 트랜잭션 커밋 시점에 확인한다.
*/
export type DeferrableType = "INITIALLY IMMEDIATE" | "INITIALLY DEFERRED";
외래키 제약 조건의 지연 여부를 설정한다.
it('INITIALLY DEFERRED:: 외래 키 제약 조건이 트랜잭션 커밋 시점에서 확인된다.', async () => {
// given
const post = postRepo.create({
title: 'test',
content: 'test',
});
const user = userRepo.create({
name: 'test',
email: 'test@test.com',
});
post.user = user;
await userRepo.save(user);
await postRepo.save(post);
// when
const queryRunner = userRepo.manager.connection.createQueryRunner();
await queryRunner.startTransaction();
// 부모 엔터티 삭제
const fetchedUser = await userRepo.findOneOrFail({ where: { id: user.id }, relations: ['posts'] });
await queryRunner.manager.remove(fetchedUser);
// 트랜잭션 중간 상태에서 외래 키 무결성 위반 발생 여부 확인
const remainingPosts = await queryRunner.manager.find(Post);
expect(remainingPosts).toHaveLength(1); // 삭제되지 않은 상태 확인
try {
// 커밋 시도
await queryRunner.commitTransaction(); // 여기서 외래 키 제약 조건 위반 발생
} catch (error: unknown) {
console.error(error);
if (error instanceof Error) {
expect(error.message).toContain('foreign key constraint');
} else {
throw error;
}
} finally {
await queryRunner.rollbackTransaction();
await queryRunner.release();
}
});
위와 같은 테스트를 작성하여, 예상 동작을 기대했지만 실패했다. InnoDB에서는 모든 외래 키 제약 조건을 항상 IMMEDIATE로 설정하기 때문에 코드 레벨에서 동작하는 deffered 옵션은 동작하지 않았다. 공식 문서를 살펴보니 MySQL의 스토리지 엔진 중 NDB만 deferrable을 지원하며 NO ACTION레벨에서만 지원한다고 한다.
psql의 경우 아래처럼 DEFFERABLE을 설정하여 사용이 가능하다.
CREATE TABLE post (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
user_id INT,
CONSTRAINT fk_user FOREIGN KEY (user_id) REFERENCES user(id)
ON DELETE NO ACTION DEFERRABLE INITIALLY DEFERRED
);
createForeignKeyConstraints
/**
* Indicates whether foreign key constraints will be created for join columns.
* Can be used only for many-to-one and owner one-to-one relations.
* Defaults to true.
*/
createForeignKeyConstraints?: boolean;
데이터베이스에서 FK는 데이터 일관성을 유지한다는 장점을 가지고 있다. 하지만 각종 제약 조건으로 인해, 데이터 자체를 수동으로 변경해야하거나 서비스 규모가 큰 경우의 샤딩, 파티셔닝 등을 할 때 제약 조건에 따른 제약들이 발생한다. 우리 회사의 데이터베이스도 이러한 제약 조건에서 자유롭기 위해 FK를 제거하고, 논리적인 관계만 유지한 채로 사용하고 있다.
이러한 기능을 지원해주는 속성이 createForeignKeyConstraints이다. 이 속성을 활성화하면 FK 제약 조건을 걸지 않는다. 즉 데이터베이스에서 FK 상태가 아닌 것을 의미한다. 외래 키가 적용되지 않았더라도, 논리적인 관계는 유지할 수 있기 때문에 정상적으로 조회는 가능하며, 1:N 관계에서 하위 관계(N)에 적용하거나, 1:1관계에서만 적용이 가능하다.
기존의 Post 엔터티에서, createForeignKeyContstraints를 false로 설정하면, 아래처럼 Post 테이블에, User의 제약조건이 걸리지 않는다.
실제 FK가 아니더라도 TypeORM이 연관된 데이터를 올바르게 로드할 수 있는지 확인하기 위해 위해 lazy loding(지연 로딩)을 적용해주었다. 지연 로딩을 통해 SQL JOIN 없이도 내부적으로 관계를 매핑하고 데이터를 로드할 수 있음을 검증해보자.
it('createForeignKeyConstraints:: 외래 키 제약 조건을 생성하지 않는다.
논리적 관계는 유지되어 조회가 가능하다.', async () => {
// given
const user = userRepo.create({
name: 'test',
email: 'test@test.com',
});
await userRepo.save(user);
const post = postRepo.create({
title: 'test',
content: 'test',
user,
});
await postRepo.save(post);
// when
const fetchedPost = await postRepo.findOneOrFail({ where: { title: post.title } });
const fetchedUser = await fetchedPost.user;
// then
expect(fetchedPost.title).toBe(post.title);
expect(fetchedUser.name).toBe(user.name);
});
FK를 걸지 않는다는 의미는 곧 INDEX 생성도 하지 않는다는 의미이다.
연관 관계가 있는 조회에서 성능 이슈가 발생하지 않으려면, 반드시 createForeignKeyConstraints를 false로 설정해 둔 관계 엔터티에 인덱스를 설정해주어야한다. 엔터티 정의 시 아래의 a, b 위치 중에 작성해주면 된다. 필자는 복합 인덱스는 클래스 레벨에, 단일 인덱스는 필드 레벨에 작성하는 편이다.
/**
* Set this relation to be lazy. Note: lazy relations are promises. When you call them they return promise
* which resolve relation result then. If your property's type is Promise then this relation is set to lazy automatically.
*/
lazy?: boolean;
/**
* Set this relation to be eager.
* Eager relations are always loaded automatically when relation's owner entity is loaded using find* methods.
* Only using QueryBuilder prevents loading eager relations.
* Eager flag cannot be set from both sides of relation - you can eager load only one side of the relationship.
*/
eager?: boolean;
lazy와 eager은 엔터티 간 관계를 로드하는 방식과 관련된 속성이다. 엔터티 간의 관계를 사용할 때 연관된 데이터를 언제, 어떻게 로드할지 제어한다. 편리하다고 생각되지만 개인적으로 잘 사용하지 않는 속성이다. 관련해서 포스팅도 작성했지만, 실제 Join을 명시하는 것을 좋아하는 내 습관 때문이다. 포스팅에서도 언급됐듯 TypeORM의 기본 로딩은 Lazy도 Eager도 아니다.
lazy
지연 로딩으로도 불리는 lazy loding은 실제로 접근하려고 할 때 추가적인 조회를 통해 로드된다. 관계가 정의된 필드를 호출할 때 추가적인 쿼리 실행으로 데이터가 생성된다.
lazy loding을 사용한 조회 시 지정한 엔터티는 Promise shell 상태로 조회된다. 이 Promise 내부에는 DB 접근 트리거 역할을 하는 LazyLoding Handler을 포함하고 있어 후에 await를 사용하여 해당 객체에 접근할 때 추가적인 DB I/O 를 통해 데이터를 가져올 수 있게 된다.
이러한 Lazy Loding의 특성은 초기 데이터 로딩 시 불필요한 데이터를 가져오지 않고, 필요할 때만 데이터를 가져오기 때문에 메모리 절약이 가능하다. 하지만 Promise 객체를 생성하는 과정에서 일반 조회 방식 대비 메모리 사용량은 많다. 특히 위 테스트 상황처럼 N + 1 문제가 발생하게 된다. N + 1 문제를 방지하기 위해, 적절하게 eager혹은 default를 사용하고, default 사용 시 쿼리 빌더 등으로 join을 명시해서 사용해주자.
eager
eager loding은 연관된 데이터를 엔터티를 로드하는 시점에 즉시 가져온다. find 인터페이스로 엔터티를 조회할 때 자동으로 연관된 데이터도 가져오게 된다.
it('Eager Loding', async () => {
// given
const user = userRepo.create({
name: 'test',
email: 'test@test.com',
});
await userRepo.save(user);
const post = postRepo.create({
title: 'test',
content: 'test',
user,
});
await postRepo.save(post);
// when
const fetchedPost = await postRepo.findOneOrFail({ where: { title: post.title } });
// then
expect(fetchedPost.title).toBe(post.title);
expect(fetchedPost.user.name).toBe(user.name);
});
항상 연관된 데이터를 포함해 로드하기 때문에 쿼리가 한 번만 실행되며, 자동으로 조인하여 로드되기 때문에 추가적인 쿼리 호출이 필요없다. 하지만 항상 데이터를 로드하기 때문에 성능 최적화를 위해서 반드시 관계 데이터가 항상 필요할 경우에만 사용하도록 하는것이 좋다.
persistence
/**
* Indicates if persistence is enabled for the relation.
* By default its enabled, but if you want to avoid any changes in the relation to be reflected in the database you can disable it.
* If its disabled you can only change a relation from inverse side of a relation or using relation query builder functionality.
* This is useful for performance optimization since its disabling avoid multiple extra queries during entity save.
*/
persistence?: boolean;
주석을 해석해보고, 위 이슈에서의 열띤 토론을 이해해보려고 했는데 테스트 작성에 실패했다. 도저히 어떤 테스트를 짜야할 지 모르겠다. 속성을 false로 지정하면 역방향에서만 관계를 변경할 수 있다고 하고, 혹은 쿼리 빌더를 이용해 관계 변경을 수행할 수 있다고 한다. 일단 차근차근 풀어보자.
우리의 User와 Post관계에서 관계의 소유자는 Post이다. Post에서 FK를 가지고 있기 때문이다.
반대로 역방향(Inverse Side)은 User쪽에서 Posts의 상태를 변경하는 상황이다.
// when: 역방향에서 관계 변경 시도
user.posts = [];
await userRepo.save(user);
// then: 역방향에서 관계 변경
const savedUser = await userRepo.findOneOrFail({ where: { id: user.id }, relations: ['posts'] });
expect(savedUser.posts).toHaveLength(0);
// when: 정방향에서 관계 변경 시도
const newUser = userRepo.create({
name: 'new user',
email: 'new@new.com',
});
await userRepo.save(newUser);
post.user = newUser;
expect(post.user).toBe(newUser);
await postRepo.save(post);
// then: 정방향에서 관계 변경
const savedPost = await postRepo.findOneOrFail({ where: { id: post.id }, relations: ['user'] });
expect(savedPost.user).toBe(user);
하지만, 지금 정방향에서도 역방향에서도 관계 변경 시 반영이 잘 되는 모습이라 제대로 구현이 되지 않았다. 만약 구현이 되더라도 어떠한 상황에서 적절히 사용해야 하는건지 잘 모르겠다. 이건 찾는 대로 해당 포스팅에 수정해두도록 하겠다.
orphanedRowAction
/**
* When a parent is saved (with cascading but) without a child row
* that still exists in database, this will control what shall happen to them.
* delete will remove these rows from database.
* nullify will remove the relation key.
* disable will keep the relation intact. Removal of related item is only possible through its own repo.
*/
orphanedRowAction?: "nullify" | "delete" | "soft-delete" | "disable";
부모-자식 관계에서 부모 엔터티 저장 시, 기존에 자식 엔터티가 데이터베이스에 존재하지만 부모와의 관계가 끊어진 경우 해당 자식 엔터티의 처리를 정의하는 옵션이다. 코드 레벨에서 동작하는 옵션이기 때문에 상위 레벨인 FK 제약 조건이 걸려있다면 같은 설정이 아니라면 올바르게 동작하지 않는다. 같은 설정을 두더라도, 이는 DB 레벨에서 제약조건에 따른 결과이지, 코드 레벨에서 무언가 수행하기 위해 추가로 입력하는 것이 아니다.
예를 들어, ON DELETE CASCADE를 사용하고, orphanedRowAction을 nullify로 사용한다면, 제약 조건에 따라 삭제될 것이다. 따라서 기본적으로 createForeignKeyConstraints설정을 false로 두고 필요 시 코드레벨에서 정의해서 사용하는 설정이라고 생각된다.
각각의 테스트에서 createForeignKeyConstraints를 false로 두고, orphanedRowAction을 제어하면서 테스트를 진행했다. 이 설정은 FK를 실제 DB에 사용하지 않으면서 무언가 코드 레벨에서의 제약 컨벤션(?)을 걸어 사용할 때 유용할 것 같다.
정리
이렇게 정리해놓고 보니, 현재 사용중인 엔터티들도 단순 leftJoinAndMap 으로 조인해서 사용할 것이 아니라, FK 제약조건을 없애고, 논리적으로만 매핑해서 사용하는 방법이 훨씬 나을 것 같다는 생각이 들었다. 생각보다 현재 로직들에서도 활용하면 좋을 것들이 눈에 보여 잘 정리했다는 생각이 든다.
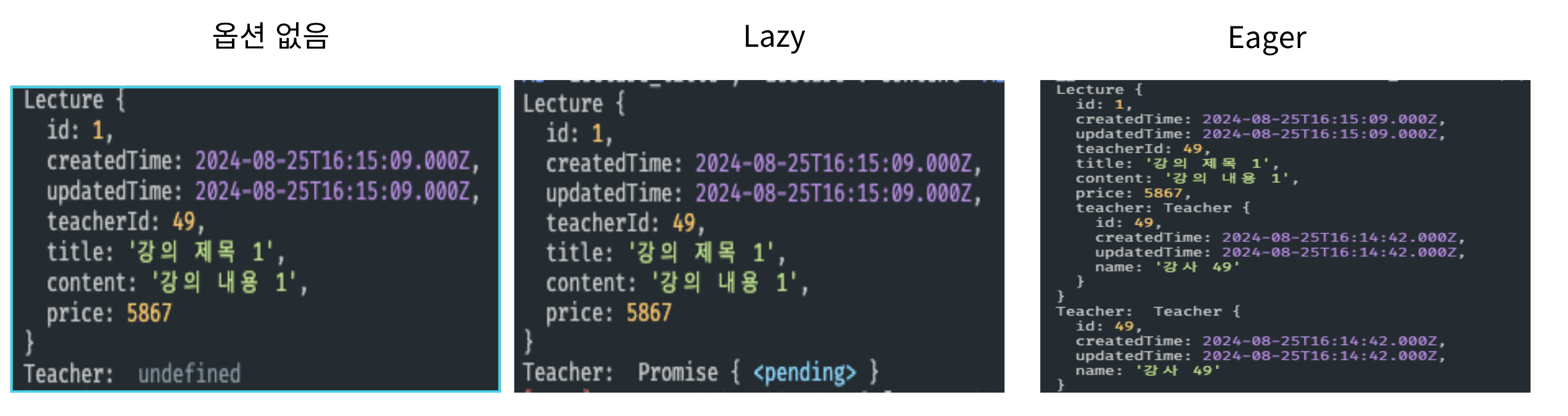
옵션이 없을 때는 1개의 쿼리를 실행했고 Lazy Loding이 적용되었을 때는 Teacher을 찾기 위한 N + 1 쿼리가 발생했다. 마지막으로 Eager Loding에서는 Lecture를 조회할 때 이미 Teacher가 같이 등장한다.
정리
1. typeORM에서 Lazy Loding은 프로미스 객체로 반환된다.
Note: if you came from other languages (Java, PHP, etc.) and are used to use lazy relations everywhere - be careful. Those languages aren't asynchronous and lazy loading is achieved different way, that's why you don't work with promises there. In JavaScript and Node.JS you have to use promises if you want to have lazy-loaded relations. This is non-standard technique and considered experimental in TypeORM.
현재의 코드 습관들이 자연스레 OverFetching과 N + 1 문제를 피하고 있었다. 사내에서는 혼자 백엔드 개발을 하다보니 코드 레벨에서의 관점을 나눌 사람이 없었다. 외부로 눈을 돌려 typeORM을 사용하는 다른 분들과 커피챗을 통해 관련된 코드 습관들이 올바른 방향인지 점검할 필요는 있을 것 같다.
반면 DataLoader은 각 요청이 배치처리되어 필요할 때 한번에 데이터를 요청하기 때문에 쿼리 수가 대폭 줄어들게 된다.
post 10개를 가져오는 쿼리
post 각각의 author을 한 번에 가져오는 쿼리
comments를 한 번에 가져오는 쿼리
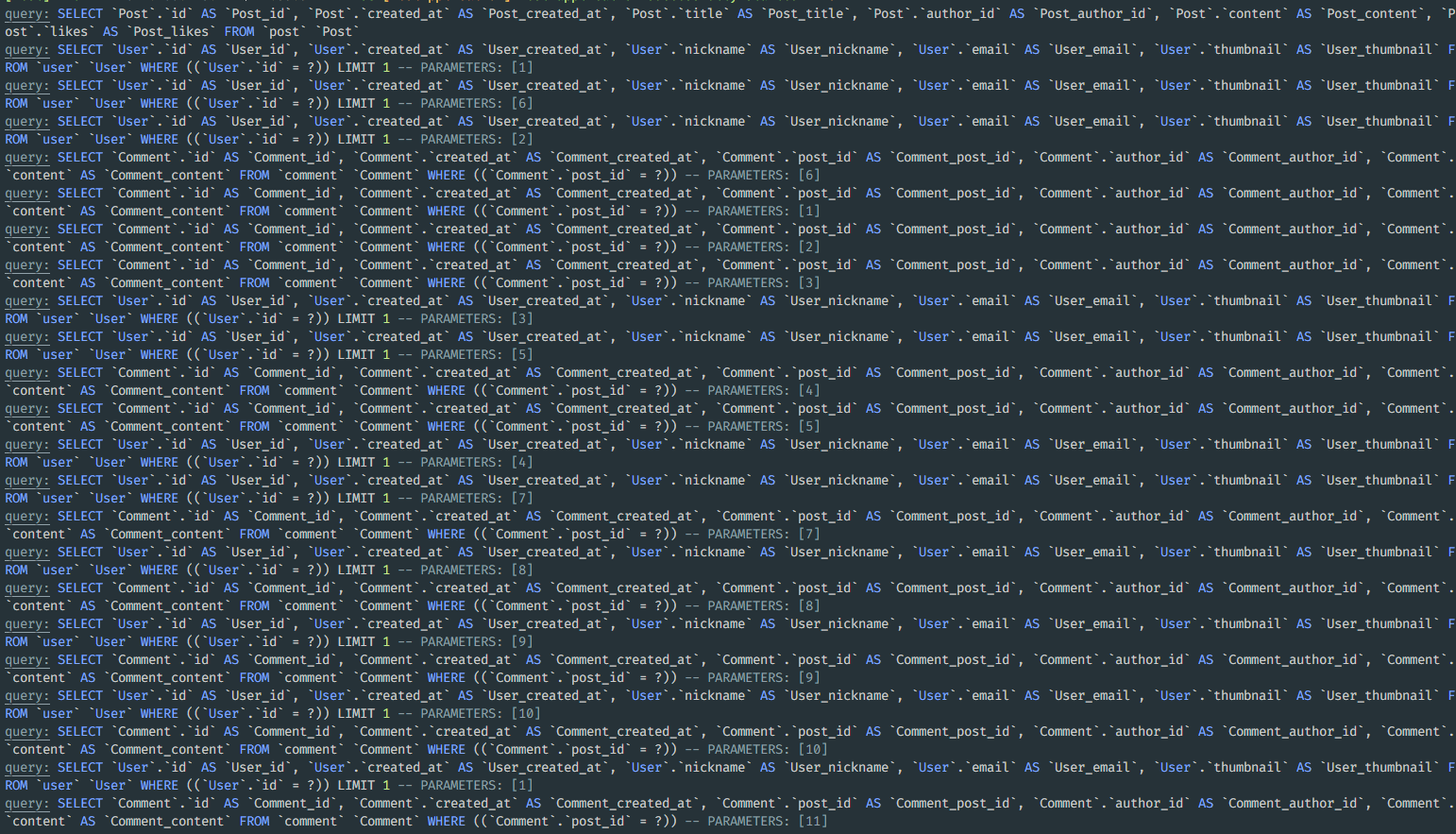
DataLoader 인스턴스가 생성되고 내부적으로 요청을 수집한다. 아래의 로그는 posts에 대한 각 author들의 정보를 받아오는 DataLoader의 인스턴스 로그이다. load(1), load(2)와 같은 함수 호출에서 DataLoader의 배치된 요청들은 tick에서 한 번에 처리하여 데이터베이스에 fetch요청을 보낸다.
아래는 DataLoader의 load 함수다. 요청을 배치로 묶어 처리하고, 캐싱을 통해 중복을 방지하는 역할 또한 수행한다. 코드를 간략히 살펴보면, 배치를 가져와 캐시 키를 생성하고 캐시의 활성 여부에 따라 promise를 재활용할지 생성할지를 결정해 캐시를 업데이트 후 promise를 반환한다. 그래서 위 예제에서, 1부터 10번까지의 key에 대해 배치를 쌓아나갈 수 있던 것이다.
_proto.load = function load(key) {
if (key === null || key === undefined) {
throw new TypeError('The loader.load() function must be called with a value, ' + ("but got: " + String(key) + "."));
}
var batch = getCurrentBatch(this);
var cacheMap = this._cacheMap;
var cacheKey = this._cacheKeyFn(key); // If caching and there is a cache-hit, return cached Promise.
if (cacheMap) {
var cachedPromise = cacheMap.get(cacheKey);
if (cachedPromise) {
var cacheHits = batch.cacheHits || (batch.cacheHits = []);
return new Promise(function (resolve) {
cacheHits.push(function () {
resolve(cachedPromise);
});
});
}
} // Otherwise, produce a new Promise for this key, and enqueue it to be
// dispatched along with the current batch.
batch.keys.push(key);
var promise = new Promise(function (resolve, reject) {
batch.callbacks.push({
resolve: resolve,
reject: reject
});
}); // If caching, cache this promise.
if (cacheMap) {
cacheMap.set(cacheKey, promise);
}
return promise;
}
이벤트 루프와 태스크 큐에서의 DataLoader 처리 DataLoader은 Node의 이벤트 루프와 태스크 큐를 활용하여 요청을 배치로 처리한다. Promise는 다음 tick에서 실행되므로 배치 처리는 여러 요청을 수집한 후 다음 tick에서 한 번에 처리할 수 있게 된다.
graphQL은 기존 데이터로 쿼리를 실행하기 위한 API를 위한 쿼리 언어이자 런타임이다. 클라이언트가 필요한 것만 정확히 요청할 수 있게 해준다.
공식 문서의 설명을 읽어보면 자세한 특징을 서술해두었고, 읽어보면 공통적으로 나오는 키워드들은 빠르다, 단일 요청, 쿼리와 타입 정도가 있다.
또한 공식 문서 내의 포스팅 중 REST와 비교한 글이 있었는데, "graphQL은 REST와 크게 다르지 않지만, API를 구축하고 소비하는 개발자 경험에 큰 차이를 만드는 작은 몇가지의 변화를 가지고 있다"고 한다.
REST API의 문제점
OverFetching
아래의 페이지는, 현재 근무하는 회사의 서비스인 아이웨딩의 페이지 일부이다.
이 페이지를 구성하기 위해 적어도 해당 카테고리에 맞는 상단 배너와 베스트 상품, 리스트 API로 데이터를 받아와서 화면을 구성해야 할 것이다.
GET api/v1/banner?category=${category}
GET api/v1/products/best?category=${category}
GET api/v1/products?category=${category}
상품의 리스트 부분에서, 클라이언트에게 필요한 것은 브랜드명, 상품명, 가격 정보다. 하지만 product 내에 해당 정보를 포함한 다른 정보들도 들어 있는 경우도 많다. 수 년 동안 같은 리스트의 정보에 대한 요구사항이 변했을 수도 있고, 그런 이유가 아니더라도 API의 규격에서 확장하거나 축소해서 커스텀하는 경우도 있을 것이다. (이런걸 REST라고 해야하나..?)
우리의 Product List API 또한 그런 형태가 되어있었다.
굳이 클라이언트에게 필요 없는 데이터들이 REST 에서는 같이 나가게 되는 경우가 빈번하고 이럴 경우 네트워크의 대역폭이 낭비되게 된다. 데이터가 필요 이상으로 커지기 때문이다. 이런 현상을 OverFetching이라고 한다
UnderFetching
이번엔 외부로 시선을 돌려보았다.
출처: MrBeast Youtube
영상의 댓글을 가져오기 위해 나는 GETvideos/1/comments API를 호출했다. 하지만 comments API의 응답에는 댓글을 쓴 사람의 nickname, thumbnail 정보가 포함되어 있지 않다.
따라서 댓글 작성자의 정보를 얻기 위해 추가적으로 GET user/{userId}API를 호출해서 유저 정보를 받아와야 한다. (만약 클라이언트 사이드의 모든 상황에서 comments에 유저 정보를 필요로 한다면 comments API 자체를 커스터마이징하면 된다.)
이 때 두가지 문제가 발생하는데, 첫 번째는 해당 API에서 원하는 정보를 모두 가져오지 못해 추가적인 API 호출이 이루어졌다는 점이고, 두 번째는 user API 역시 nickname, thumbnail을 포함한 유저 정보가 들어있기 때문에 OverFetching이 일어났다는 점이다.
이렇게 하나의 API에서 모든 데이터를 처리하지 못해 추가로 요청하여 처리해야하는 현상을 UnderFetching이라 하며, UnderFetching은 추가 데이터 요청 과정에서 OverFetching까지 초래할 수 있다.
graphQL로 전환
다시 위 사진에서 graphQL API인 POST /graphql 로 요청을 보낸다면 아래처럼 응답을 받을 수 있다.
딱 원하는 데이터에 대한 응답만 받을 수 있는 것이다.
graphQL의 단점
캐싱
개발을 하면서, 304(Not Modified)라는 상태코드를 본 적이 있을 것이다. 요약하자면 클라이언트가 요청한 리소스가 변경되지 않았음을 나타내는 이 상태 코드는 클라이언트가 캐시된 데이터를 사용할 수 있게 한다. 이는 서버의 응답을 줄이고 네트워크 트래픽을 절약하는 데 유용하다.
HTTP에서 제공하는 캐싱 정책은 단순히 헤더에 명시하는 것만으로 쉽게 적용할 수 있다. 또한 HTTP 캐싱 전략은 각 URL에 고유한 정책을 설정하는 형태로 이루어진다. REST API는 각 엔드포인트마다 다른 캐싱 정책을 설정할 수 있어 HTTP의 캐싱 전략을 그대로 사용할 수 있다. 그러나 graphQL은 단일 엔드포인트인 /graphql로 들어오기 때문에 기존의 HTTP 캐싱 전략을 적용하기 어렵다.
이로 인해 서버와 클라이언트 측 모두 적절한 캐싱 처리를 구현해야 하며, 캐싱 전략도 별도로 사용해야 한다.
기타
이 외에도, 파일 업로드를 위한 추가처리, REST와 달리 버전 관리의 어려움의 단점이 있으며 graphQL 스키마 설계와 리졸버, 쿼리 최적화 등의 높은 러닝커브 또한 단점으로 꼽힌다.
Nest + TypeORM + graphQL
apollo, mercurius을 기본적으로 지원하고, 커스텀 드라이버도 사용할 수 있다고 한다. 나는 apollo를 사용했고, 접근성이 좋은 블로그나 SNS 등의 일반적인 포맷인 게시물 + 유저 형태로 코드를 작성해가며 학습했다.
리졸버의 사용에 익숙해지고, graphQL의 데코레이터들에만 익숙해진다면 금방 따라갈 수 있다.
내가 학습하면서 기록하고 싶은 부분들을 서술해보고자 한다.
독립적으로 구현 가능
posts API에서 우리는 정책상 comments, author을 모두 들고오기로 했다고 해보자.
@ResolvedField는 특정 엔터티의 필드가 다른 엔터티와 연관이 되어 있을 때, 해당 연관된 데이터를 가져오는 로직을 정의하는 데 사용된다. 위처럼 각 로직들을 개별 메서드로 분리하여 코드의 가독성과 유지보수를 높일 수 있다.
이런 요청을 보내면, 순차적으로 posts를 찾고 posts에 대한 author, posts에 대한 comments를 찾은 뒤 각 코멘트의 author을 찾는 순서로 이루어진다. ResolvedField로 관계 매핑을 확인하여 해당 로직으로 데이터를 가져와 넣어주게 된다.
(글을 2개써서 2번의 글 작성자를 가져왔다)
InputType, ObjectType, ArgsType
이 데커레이터들은 데이터를 주고 받는 구조를 명확히 정의할 수 있는 데커레이터들로, 데이터 교환이 일관되고 예측 가능하게 한다. nest에서는 이 위에 Validation, Trasnforming등을 할 수 있어 강력한 검증이 가능하다. 기존의 Dto를 graphQL을 사용하기 위해 데커레이터를 덧씌워준다고 생각하면 되겠다. gql 타입 정의를 통해 자동 문서화도 된다.
@InuptType()은 주로 뮤테이션의 인자로 사용되는 입력 객체를 정의할 때 사용한다. @ObjectType()은 객체 타입을 정의할 때 사용하고, 데이터를 반환할 때 사용되는 타입을 정의한다.
기술 블로그들에 잘 설명 되어있는 정보 전달성 versus를 제외하고, 실무에서 써본적이 없는 주니어 개발자인 내가, 현재 업무와의 연관성을 지어보면서 단순 학습만으로 어떻게든 둘의 차이를 느껴보려고 했다.
OverFetching + UnderFetching
실제 프로덕션을 보면서 생각보다 이런 문제가 심각할 수도 있는 경우가 아마 클라이언트 측 사양이 낮은 경우가 있지 않을까 싶다. 항상 최신식에 가까운 사양의 장비들로 개발을 하다보니 이런 부분을 놓칠 수 있다. 이런 측면에서 봤을때 graphQL은 괜찮은 대안이 될 수 있을 것 같다.
문서화(Swagger는 어려워요)
Swagger은 API 문서화를 위한 강력한 도구지만, 아무리 서술을 잘 해두어도 프론트 개발자 분들이 Swagger만 보고 완벽하게 개발을 할 수는 없다. API를 개발한 당사자의 의도도 100% 파악하기 어렵다. graphQL은 보다 직관적이게 쿼리나 뮤테이트의 타입들만 보고 확인할 수 있으니 데이터의 구조와 관계를 더 명확히 이해할 수 있을 것이고 협업 시에 더 이점을 제공할 것 같다.