서론
트랜잭션의 격리 수준 포스팅에서 다루지 않았던 이상현상 중 Lost Update와 Write Skew같은 일관되지 않은 쓰기 결과를 반환하는 데이터 부정합 문제가 있다. PostegraSQL에서는 격리 수준을 REPEATABLE READ로 설정하는 것만으로도 쓰기 결과를 올바르게 보장할 수 있다. 하지만 MySQL의 MVCC(Multi Version Concurrency Control)은 일관된 읽기(Consistence Read)를 지원하지만 위와 같은 데이터 업데이트의 부정합 문제를 REPEATABLE READ의 격리 수준 만으로는 해결할 수 없다.
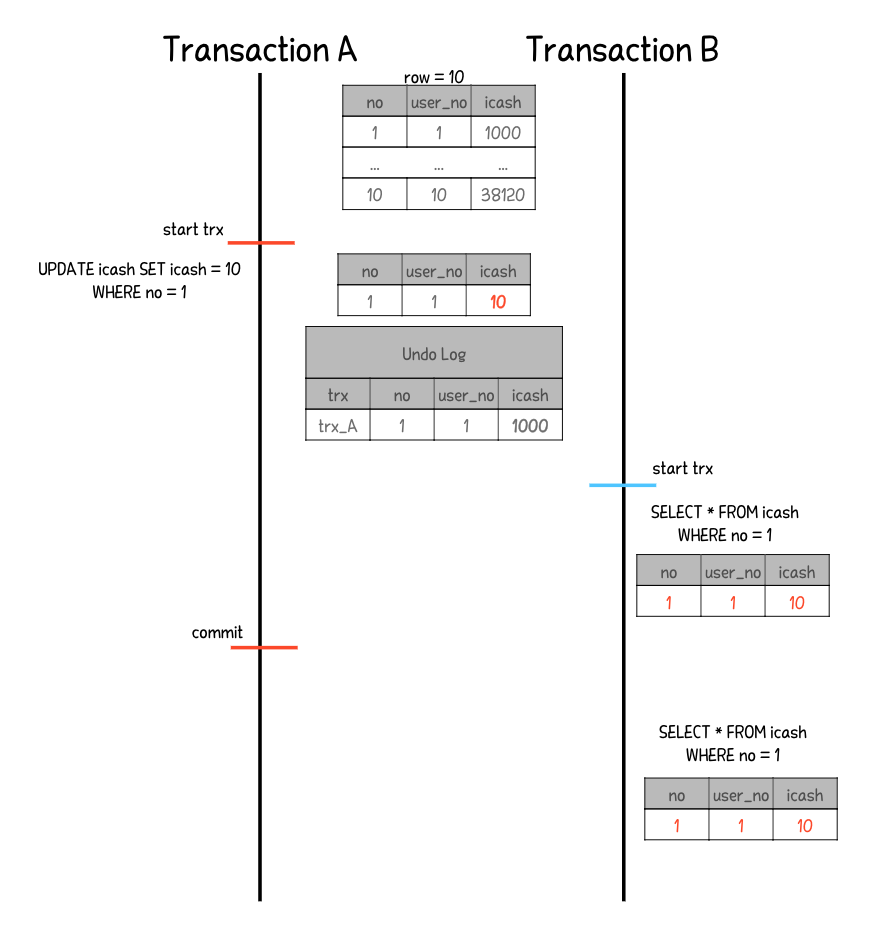
아래 그림은 MySQL에서 REPEATABLE READ 격리 수준을 사용했을 때 Lost Update가 발생하는 상황이다. 고객 A가 10,000원을 사용한 뒤 관리자가 곧바로 20,000원을 환불했지만 결과적으로 고객의 잔액은 30,000원 이 되어버렸다. 이는 두 트랜잭션이 같은 데이터를 읽고 각각의 연산 결과를 덮어버린 탓에 발생한 문제다.

격리 수준을 SERIALIZABLE로 설정하면 모든 데이터 부정합 문제를 해결할 수 있지만 그만큼 동시성이 보장되지 않는다. 결제, 재고, 선착순 이벤트 등과 같은 상황에서 특히 데이터 정합성이 필수적이다. 또한 그런 기능은 생각보다 보편화되어 널리 사용되고 있다.
위처럼, Lost Update와 Write Skew는 동시에 실행된 트랜잭션에서 같은 데이터를 조회하면서 데이터에 일관성이 깨져버린다. 그렇다면 MySQL에서 동시성을 보장하면서 Lost Update, Write Skew같은 부정합 문제도 해결하기 위해서 어떤 방법을 사용해야할까?
Lost Update
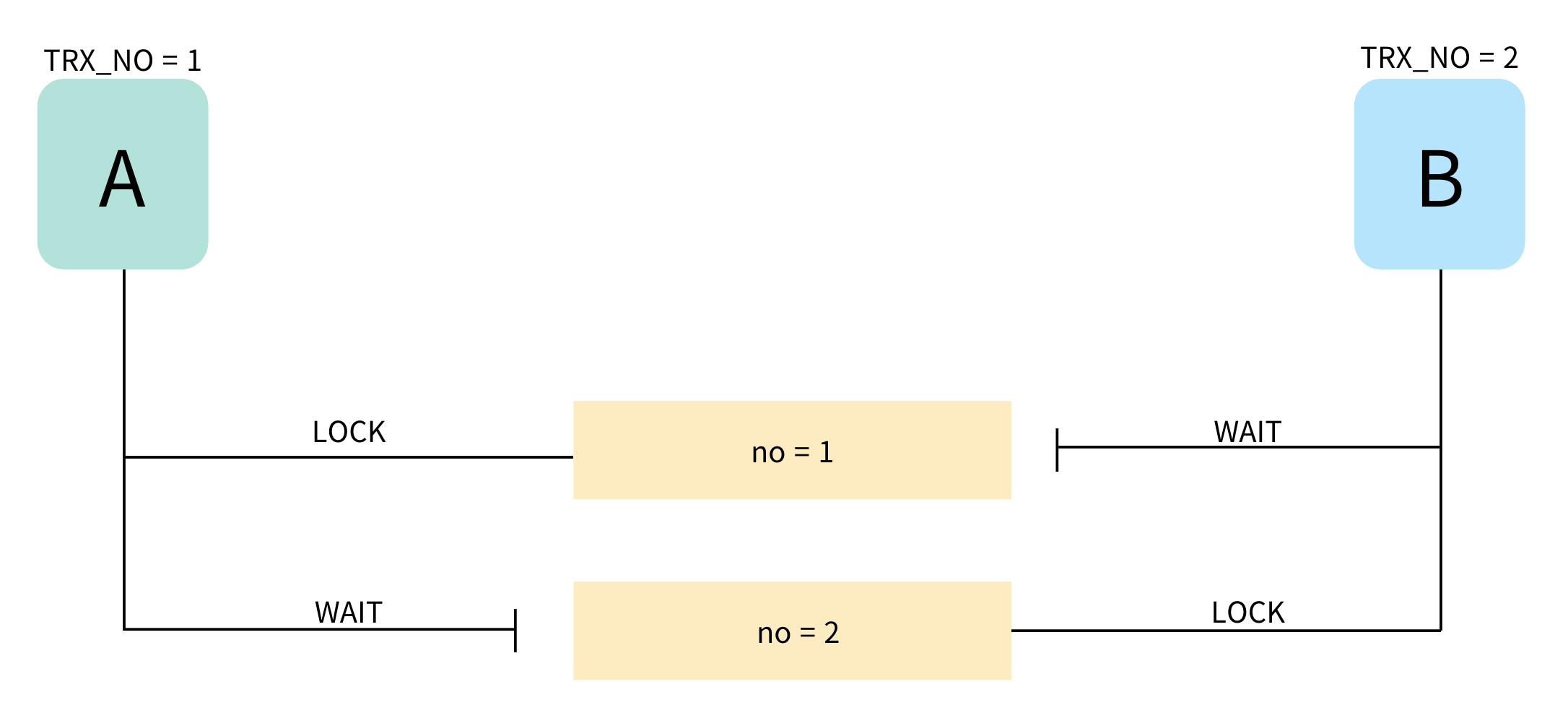
Lost Update란 위 예시처럼 두 트랜잭션이 동일한 레코드를 읽고 각각 수정한 결과를 커밋할 때 발생하는 문제이다. 첫 번째 트랜잭션의 업데이트가 두 번째 트랜잭션의 결과로 덮여버리며, 데이터의 정합성이 깨지게 된다.
it('REPEATABLE READ:: LOST UPDATED.', async () => {
runnerA = dataSource.createQueryRunner();
runnerB = dataSource.createQueryRunner();
// 트랜잭션 A 시작
await runnerA.startTransaction('REPEATABLE READ');
const repoA = runnerA.manager.getRepository(ICashEntity);
// 트랜잭션 B 시작
await runnerB.startTransaction('REPEATABLE READ');
const repoB = runnerB.manager.getRepository(ICashEntity);
// 업데이트를 위해 조회
const readA = await repoA.createQueryBuilder().where('no = :no', { no: 1 }).getOneOrFail();
const readB = await repoB.createQueryBuilder().where('no = :no', { no: 1 }).getOneOrFail();
//초기 값 테스트
expect(readA.icash).toBe(10000);
expect(readB.icash).toBe(10000);
// 캐시 사용
await repoA.update({ no: 1 }, { icash: readA.icash - 10000 });
await runnerA.commitTransaction();
// 캐시 적립
await repoB.update({ no: 1 }, { icash: readB.icash + 20000 });
await runnerB.commitTransaction();
const result = await repoA.findOneOrFail({ where: { no: 1 } });
expect(result.icash).toBe(20000);
});

위 그림을 테스트 코드로 작성했다. 거의 비슷한 시간에 고객이 캐시를 사용하면서 관리자가 캐시를 환불해주었다. 우리는 캐시 사용과 환불을 통해 2만원이라는 결과를 기대하지만, 고객의 캐시 사용에 대한 커밋은 이후의 트랜잭션에 의해 덮어졌다. 이를 개선해서 올바른 업데이트를 반영시켜보자.
Optimistic Lock(낙관적 잠금)
Optimisitic Lock은 데이터를 동시에 수정하지 않을 것이라고 가정하는 방식이다. 예를 들어, 회원 정보 수정처럼 동시에 수정될 가능성이 낮은 작업에서 효과적이다. 데이터에 Lock을 걸지 않기 때문에 동시 요청에 대해 처리 성능이 뛰어나다. 대신 충돌이 발생하면 이를 감지하고 롤백하거나 재시도해야한다.
it.only('REPEATABLE READ:: LOST UPDATED.', async () => {
runnerA = dataSource.createQueryRunner();
runnerB = dataSource.createQueryRunner();
// 트랜잭션 A 시작
await runnerA.startTransaction('REPEATABLE READ');
const repoA = runnerA.manager.getRepository(ICashEntity);
// 트랜잭션 B 시작
await runnerB.startTransaction('REPEATABLE READ');
const repoB = runnerB.manager.getRepository(ICashEntity);
const readA = await repoA.createQueryBuilder().where('no = :no', { no: 1 }).getOneOrFail();
const readB = await repoB.createQueryBuilder().where('no = :no', { no: 1 }).getOneOrFail();
expect(readA.icash).toBe(10000);
expect(readB.icash).toBe(10000);
const updateResultA = await repoA
.createQueryBuilder()
.update(ICashEntity)
.set({ icash: readA.icash - 10000, version: readA.version + 1 })
.where('no = :no', { no: 1 })
.andWhere('version = :version', { version: readA.version })
.execute();
if (updateResultA.affected === 0) {
throw new Error('Optimistic Lock Conflict: Transaction A failed to update');
}
await runnerA.commitTransaction();
const updateResultB = await repoB
.createQueryBuilder()
.update(ICashEntity)
.set({ icash: readB.icash + 20000, version: readB.version + 1 })
.where('no = :no', { no: 1 })
.andWhere('version = :version', { version: readB.version })
.execute();
await runnerB.commitTransaction();
const result = await repoA.findOneOrFail({ where: { no: 1 } });
// Optimistic Lock Conflict: Transaction B failed to update
expect(result.icash).toBe(0);
expect(updateResultB.affected).toBe(0);
});@Entity('icash')
export class ICashEntity {
@VersionColumn()
version!: number;
}
version 컬럼을 활용해 Optimistic Lock을 구현했다. Optimisitic Lock을 사용하면 version을 통해 데이터의 상태 변화를 감지하고, 트랜잭션 충돌을 방지할 수 있다. 트랜잭션 A가 업데이트하면서 version을 증가시키면, 트랜잭션 B는 자신의 version 조건이 충족되지 않아 업데이트에 실패한다.
하지만, 이 방식 테이블에 추가 컬럼이 필요하고, 충돌 시 롤백이나 재시도 로직이 필요하다.
위의 테스트 코드에서처럼, B에서 실패 후처리를 하지 않았기 때문에 캐시는 환불되지 않았다.
따라서 데이터 충돌 가능성이 높은 경우에는 배타적 잠금(Pessimistic Lock)을 활용하는 것이 더 적합할 수 있다.
Pessimistic Lock(비관적 잠금)
SERIALIZABLE은 쓰기 상황에서 동시 요청에 대해 데이터 정합성이 깨지지 않도록 보장한다. 이는 SERIALIZABLE 격리 수준의 특징으로 MySQL에서는 SERIALIZABLE 격리 수준에서 데이터를 읽을 때 항상 Shared Lock(읽기 잠금)을 건다.

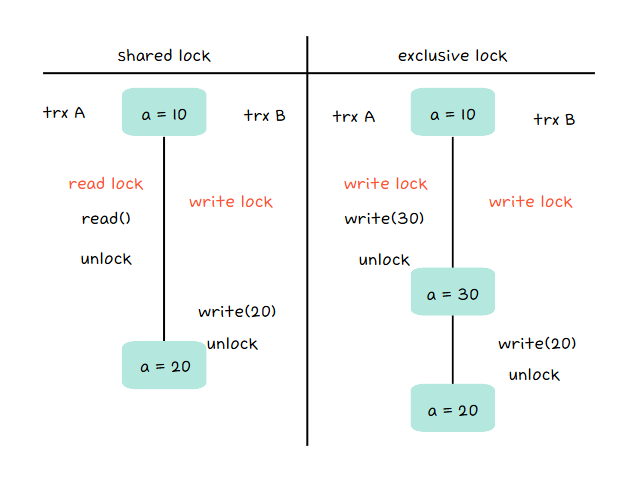
비관적 잠금은 데이터가 동시에 수정될 것이라고 가정하고, 데이터를 읽는 시점에 Lock을 걸어 트랜잭션이 완료되면 반납하는 방식이다. 이를 통해 동시성 이슈를 방지하면서도 데이터 무결성을 유지할 수 있다. 이러한 비관적 잠금에는 크게 공유 잠금과 배타 잠금이 있다.
- 공유 잠금(Shared Lock - S Lock / 읽기 잠금) - 다른 트랜잭션의 읽기는 허용
- 배타적 잠금(Exclusive Lock - X Lock / 쓰기 잠금) - 다른 트랜잭션의 읽기 쓰기 모두 차단
아래 코드는 REPEATABLE READ 격리 수준에서 비관적 잠금을 사용하는 실제 비즈니스 로직의 예시를 단위로 분리하고, 데이터를 읽으면서 잠금을 걸었다. 이를 통해 동시 업데이트 시에도 성공적으로 데이터를 보호할 수 있다.
@Injectable()
export class ICashService {
constructor(private readonly icashRepo: ICashRepository) {}
async getICash(userNo: number) {
return this.icashRepo.findICashByUserNo(userNo);
}
@Transactional({ isolationLevel: IsolationLevel.REPEATABLE_READ })
async useICash(userNo: number, amount: number) {
const icash = await this.icashRepo.findOneOrFail({ where: { userNo }, lock: { mode: 'pessimistic_write' } });
await this.icashRepo.update(icash.no, { icash: icash.icash - amount });
}
@Transactional({ isolationLevel: IsolationLevel.REPEATABLE_READ })
async refundICash(userNo: number, amount: number) {
const icash = await this.icashRepo.findOneOrFail({ where: { userNo }, lock: { mode: 'pessimistic_write' } });
await this.icashRepo.update(icash.no, { icash: icash.icash + amount });
}
}
//test code
it.only('REPEATABLE READ:: LOST UPDATED WITH BUSINESS LOGIC', async () => {
await Promise.all([iCashService.useICash(1, 10000), iCashService.refundICash(1, 20000)]);
const result = await iCashService.getICash(1);
expect(result!.icash).toBe(20000);
});
하지만 이런 방식에도 문제점이 없지는 않다. 데이터를 읽는 시점에 Lock을 획득했기 때문에 동시성을 떨어뜨릴 수 있다. 두 트랜잭션 모두 동시에 Lock을 획득했다고 가정해보자. 결국 쓰기 작업에서 타임아웃 등이 발생할 수도 있다. 그렇기 때문에 대기 시간을 관리하여야 한다. wait(nowait) 옵션을 활용하여 락 대기 시간을 조절하지 않으면, 락 대기 시간이 길어질 경우 시스템 성능에 영향을 미칠 수 있다.
Write Skew
Write Skew은 두 트랜잭션이 동일한 데이터를 읽지만 커밋된 데이터가 일관적이지 않은 것을 말한다.
it('REPEATABLE READ:: Write Skew - Event Registration', async () => {
// 초기 데이터: 현재 99명 등록
await eventRepo.save({
eventId: 1,
maxParticipants: 100,
currentParticipants: 99
});
runnerA = dataSource.createQueryRunner();
runnerB = dataSource.createQueryRunner();
await runnerA.startTransaction('REPEATABLE READ');
await runnerB.startTransaction('REPEATABLE READ');
// 두 트랜잭션이 동시에 현재 참가자 수를 확인
const eventA = await runnerA.manager.findOne(EventEntity, {
where: { eventId: 1 }
}); // 99명 읽음
const eventB = await runnerB.manager.findOne(EventEntity, {
where: { eventId: 1 }
}); // 99명 읽음
// 각 트랜잭션이 독립적으로 참가 가능 여부 확인
if (eventA.currentParticipants < eventA.maxParticipants) {
// 참가자 A 등록
await runnerA.manager.insert(ParticipantEntity, {
eventId: 1,
userId: 'userA'
});
await runnerA.manager.update(EventEntity,
{ eventId: 1 },
{ currentParticipants: eventA.currentParticipants + 1 }
);
}
if (eventB.currentParticipants < eventB.maxParticipants) {
// 참가자 B 등록
await runnerB.manager.insert(ParticipantEntity, {
eventId: 1,
userId: 'userB'
});
await runnerB.manager.update(EventEntity,
{ eventId: 1 },
{ currentParticipants: eventB.currentParticipants + 1 }
);
}
await runnerA.commitTransaction();
await runnerB.commitTransaction();
const result = await eventRepo.findOne({
where: { eventId: 1 }
});
// Write Skew: 101명이 등록됨 (제한 100명 초과)
expect(result.currentParticipants).toBe(101);
});
위와 같은 선착순 이벤트 시나리오에서, 100명의 정원이 있다. 두 트랜잭션에서 99라는 같은 데이터를 읽었고, 두 트랜잭션은 아직 신청이 가능하다고 판단했다. 그래서 각자 다른 레코드를 추가하여 100명 제한이 초과되어버렸다. 이는 비즈니스 규칙을 위반하는 심각한 문제가 되었다.
Write Skew의 경우에도, 여러 해결책이 있겠지만 데이터베이스 관점에서는 SERIALIZABLE 격리 수준을 사용하거나, 비관적 잠금과 같은 Locking Reads를 사용하는 방법으로 해결할 수 있다. 위의 비관적 잠금 예시와 동일하니 예제는 생략하도록 하자.
정리
Lost Update는 Write Skew의 부분집합이겠구나, 라는 생각을 하면서 차이점들을 정리해보았다.
- Lost Update: 단일 레코드에서 발생하며 단순한 데이터 덮어쓰기 현상
- Write Skew: 여러 레코드 또는 관련 데이터에 발생할 수 있으며 비즈니스 규칙이나 데이터 정합성을 위반한다.
동시성을 향상시키면서 데이터에도 문제가 생기지 않도록 비즈니스 로직을 구현할 때 생각을 많이 해야할 것 같다. 성능을 버리고 안정성에 몰빵하는 SERIALIZABLE부터 DB 레벨에서의 락을 활용하거나 Redis 등으로 동시성을 제어하는 등 구현하고자 하는 상황에 맞는 기술을 선택하는 것이 중요해 보인다.
참조
https://stackoverflow.com/questions/27826714/lost-update-vs-write-skew
https://www.cockroachlabs.com/blog/what-write-skew-looks-like/
https://dev.mysql.com/doc/refman/8.4/en/innodb-locking-reads.html
https://www.geeksforgeeks.org/transaction-isolation-levels-dbms/