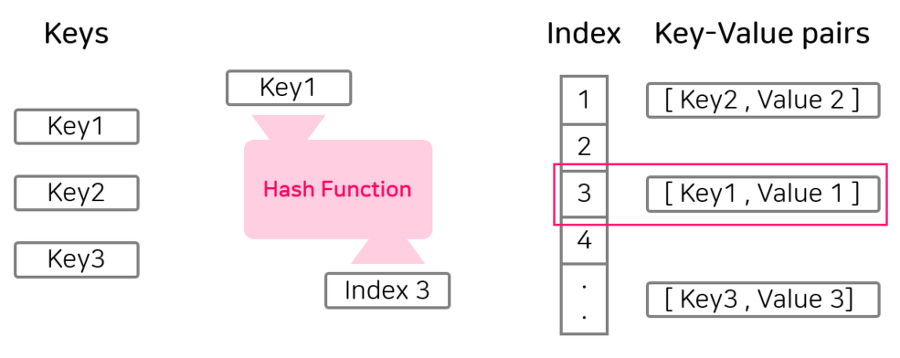
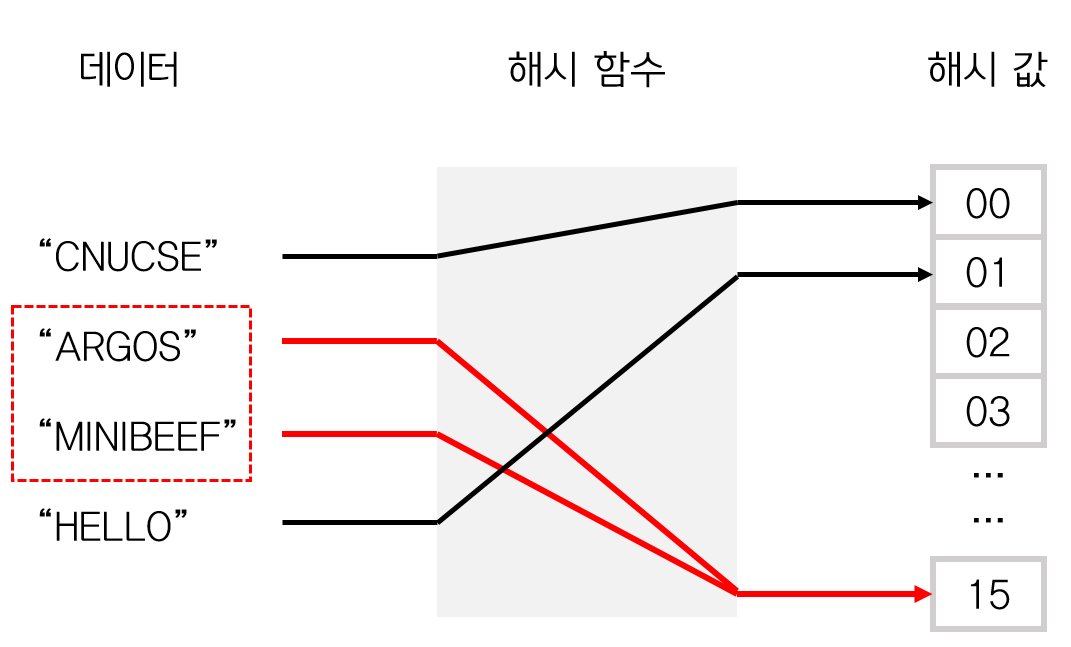
Map의 인터페이스의 구현체로는 HashMap, HashTable, ConcurrentHashMap등이 있는데
thread-safe와 hashtable관련 포스팅을 했기 때문에 어떤 경우에 어떤 자료구조를 사용해야 하는지 알아보려 한다.
[자료구조] 해시테이블 (hashtable)
해시테이블 (hashtable) Key, Value 로 데이터를 저장하는 자료구조 중 하나이며 데이터를 빠르게 검색할 수 있는 자료구조이다. 빠른 검색을 할 수 있는 이유는 내부적으로 버킷(배열)을 사용하여 데
mag1c.tistory.com
[Java] 자바에서의 스레드 안전(Thread Safe)과 모니터(monitor)
연관 게시물 https://mag1c.tistory.com/364 스레드 안전 - Thread Safe 연관 게시물 https://mag1c.tistory.com/365 [Java] 자바에서의 스레드 안전(Thread Safe)과 모니터(monitor) 자바에서의 Thread-Safe 1. Lock synchronized 아래
mag1c.tistory.com
스레드 안전 - Thread Safe
연관 게시물 https://mag1c.tistory.com/365 [Java] 자바에서의 스레드 안전(Thread Safe)과 모니터(monitor) 자바에서의 Thread-Safe 1. Lock synchronized 아래 코드는 Synchronized 키워드를 사용하여 스레드의 안전성을 보
mag1c.tistory.com
HashMap
Key Value에 null을 허용하지만, 동기화를 보장하지 않는다.
동기화 처리를 하지 않기 때문에 데이터 탐색 속도는 빠르지만, 신뢰성과 안정성이 떨어진다.
HashTable
Key Value에 null을 허용하지 않고, 동기화를 보장한다.
get() put() remove()등의 메서드에 synchronized 키워드가 붙어 있어, 멀티 쓰레드 환경에서 사용할 수 있다.
synchronized 키워드 때문에 동작이 느리다. (쓰레드 간 동기화 Lock 때문에...)
ConCurrentHashMap
Key Value에 null을 허용하지 않으며 동기화를 보장한다.
동기화 처리 시, 조작하는 버킷(index)에 대해서만 락을 걸기 때문에, 같은 멀티 쓰레드 환경에서 사용하더라도 HashTable 대비 속도가 빠르다.
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
public V get(Object key) {}
public boolean containsKey(Object key) { }
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
}
ConcurrentHashMap클래스의 일부 API이다. Hashtable과 달리 synchronized 키워드가 메서드 전체에 붙어있지 않다. get() 은 아예 존재하지도 않는다. put() 메서드에는 중간에 synchronized 키워드가 있다.
즉 ConcurrentHashMap은 읽기 작업에는 여러 쓰레드가 동시에 읽을 수 있지만, 쓰기 작업에서는 특정 버킷에 대한 Lock을 사용한다는 것을 의미한다.
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final int DEFAULT_CAPACITY = 16;
// 동시에 업데이트를 수행하는 쓰레드 수
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
}
DEFAULT_CAPACITY, DEFAULT_CONCURRENCY_LEVEL이 16으로 설정되어 있는 것을 볼 수 있다.
DEFAULT_CAPACITY는 버킷의 수이며, DEFAULT_CONCURRENCY_LEVEL는 동시에 작업 가능한 쓰레드 수라고 생각한다.
버킷의 수가 동시작업 가능한 쓰레드의 수인 이유는 버킷 단위로 lock을 사용하기 때문에 같은 버킷만 아니라면 Lock을 기다릴 필요가 없다. 동시에 데이터를 삽입, 참조하더라도 그 데이터가 다른 버킷에 위치하면 서로 락을 얻기위해 경쟁하지 않는다는 뜻이다.
위의 특징들을 바탕으로 정리해 볼 때, ConcurrentHashMap은 읽기보다는 쓰기 작업에서, 성능이 중요한 상황에서 쓰는 것이 적합하다. 같은 버킷이 아니라면 여러 쓰레드가 동시에 삽입하는 것이 가능하기 때문이다.
코드 테스트
위의 컬렉션들을 10개의 스레드에서 각각 1000번을 반복하여 랜덤 값을 입력할 때 엔트리의 사이즈를 비교하는 코드이다. (성능 테스트가 아님) (코드테스트 출처)
import java.util.Collections;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class MultiThreadsTest {
private static final int MAX_THREADS = 10;
private static Hashtable<String, Integer> ht = new Hashtable<>();
private static HashMap<String, Integer> hm = new HashMap<>();
private static HashMap<String, Integer> hmSyn = new HashMap<>();
private static Map<String, Integer> hmSyn2 = Collections.synchronizedMap(new HashMap<String, Integer>());
private static ConcurrentHashMap<String, Integer> chm = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(MAX_THREADS);
for( int j = 0 ; j < MAX_THREADS; j++ ){
es.execute(new Runnable() {
@Override
public void run() {
for( int i = 0; i < 1000; i++ ){
String key = String.valueOf(i);
ht.put(key, i);
hm.put(key, i);
chm.put(key, i);
hmSyn2.put(key, i);
synchronized (hmSyn) {
hmSyn.put(key, i);
}
}
}
});
}
es.shutdown();
try {
es.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Hashtable size is "+ ht.size());
System.out.println("HashMap size is "+ hm.size());
System.out.println("ConcurrentHashMap size is "+ chm.size());
System.out.println("HashMap(synchronized) size is "+ hmSyn.size());
System.out.println("synchronizedMap size is "+ hmSyn2.size());
/*
for( String s : hm.keySet() ){
System.out.println("["+s+"] " + hm.get(s));
}
*/
}
}Hashtable size is 1000
HashMap size is 1281
ConcurrentHashMap size is 1000
HashMap(synchronized) size is 1000
synchronizedMap size is 1000
HashMap은 동기화가 이루어지지 않아 엔트리 사이즈가 비정상적으로 나오지만 HashMap을 synchronized 키워드를 사용하면 정상적으로 동작한다.
동기화 이슈가 있다면 일반적인 HashMap을 사용하지 말고, 동기화를 보장하는 컬렉션 또는 synchronized 키워드를 사용해 반드시 동기화 처리를 해주어야 한다.
요약
| HashMap | HashTable | ConcurrentHashMap | |
| nullable | O | X | X |
| thread-safe | X | O | O |
| recommand | single-thread | multi-thread | multi-thread |
참조
https://jdm.kr/blog/197
https://tecoble.techcourse.co.kr/post/2021-11-26-hashmap-hashtable-concurrenthashmap/
https://baeldung.com/java-synchronizedmap-vs-concurrenthashmap
https://pplenty.tistory.com/17
https://devlog-wjdrbs96.tistory.com/269