서론
Node를 처음 접할 때, 가장 먼저 이해해야하는 것들 중에는 아래와 같은 개념들이 있습니다.
JS 실행은 기본적으로 싱글 스레드다.
대신 이벤트 루프와 비동기 I/O로 동시성을 만든다.
CPU를 갈아 넣는 작업은 워커나 별도 프로세스가 담당한다.
저도 Java를 짧게 다루다가 Node로 처음 기술 스택을 전환했을 때 위와 같은 개념을 먼저 접했던 것 같습니다.
그리고 이런 개념들은, Node의 JavaScript 실행 방식은 기준점이 되어 프로그래밍을 하면서 항상 생각하고, 녹여내려고 했습니다.
기본적인 async/await는 물론이고, 이벤트 루프를 막을 법한 무거운 연산은 워커로 빼는 식의 설계를 자연스럽게 떠올리게 됐습니다.
최근 Python으로 스택 전환을 하면서, Python은 동시성 처리를 어떻게 해야할까? 라는 생각에 조금씩 학습을 하고 있습니다.
제가 Node에서 체화했던 동시성 처리 부분이 Python에서 혼동이 생겨 동시성 처리의 핵심이 되는 GIL(Global Interpreter Lock)에 관련된 내용을 정리하고자 합니다. 미리 요약하면 다음과 같습니다.
- GIL이란? CPython에서 GIL이 생긴 이유
- 멀티스레딩이 실제로 어떻게 제한되는지
- Node.js와 Python의 동시성 모델 비교
- 그래서 어떤 설계를 선택할지
- GIL과 관련해서 2025년 기준의 방향성
에 대해 정리해보겠습니다.
GIL(Global Interpreter Lock)
The global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. - Python Wiki
GIL(Global Interpreter Lock)은 한 번에 하나의 스레드만 Python 바이트코드를 실행할 수 있도록 보장하는 뮤텍스이며 CPython의 특성입니다. GIL 덕분에 thread-safe를 보장하지만, 같은 프로세스 안에서 스레드가 여러 개 있어도 한 번에 하나의 인터프리터만 실행시키는 제약이 생깁니다.
1. CPython
JavaScript는 V8, SpiderMonkey, NodeJS, Deno, Bun 등 여러 런타임이 존재합니다.
Python도 실행하는 인터프리터의 종류가 다양하며, 그 중 가장 널리 쓰이는 공식 구현체가 C로 작성된 CPython입니다.
2. Mutex
Mutex(Mutual Exclusion)는 공유 자원에 대한 동시 접근을 막는 동기화 메커니즘입니다.
GIL은 일종의 열쇠입니다. 이 GIL을 통해 하나의 스레드에서 작업을 수행하고 반납하면, 다음 스레드에서 GIL을 얻어 작업을 수행합니다.
동작 방식을 시각화해보면 다음과 같습니다.
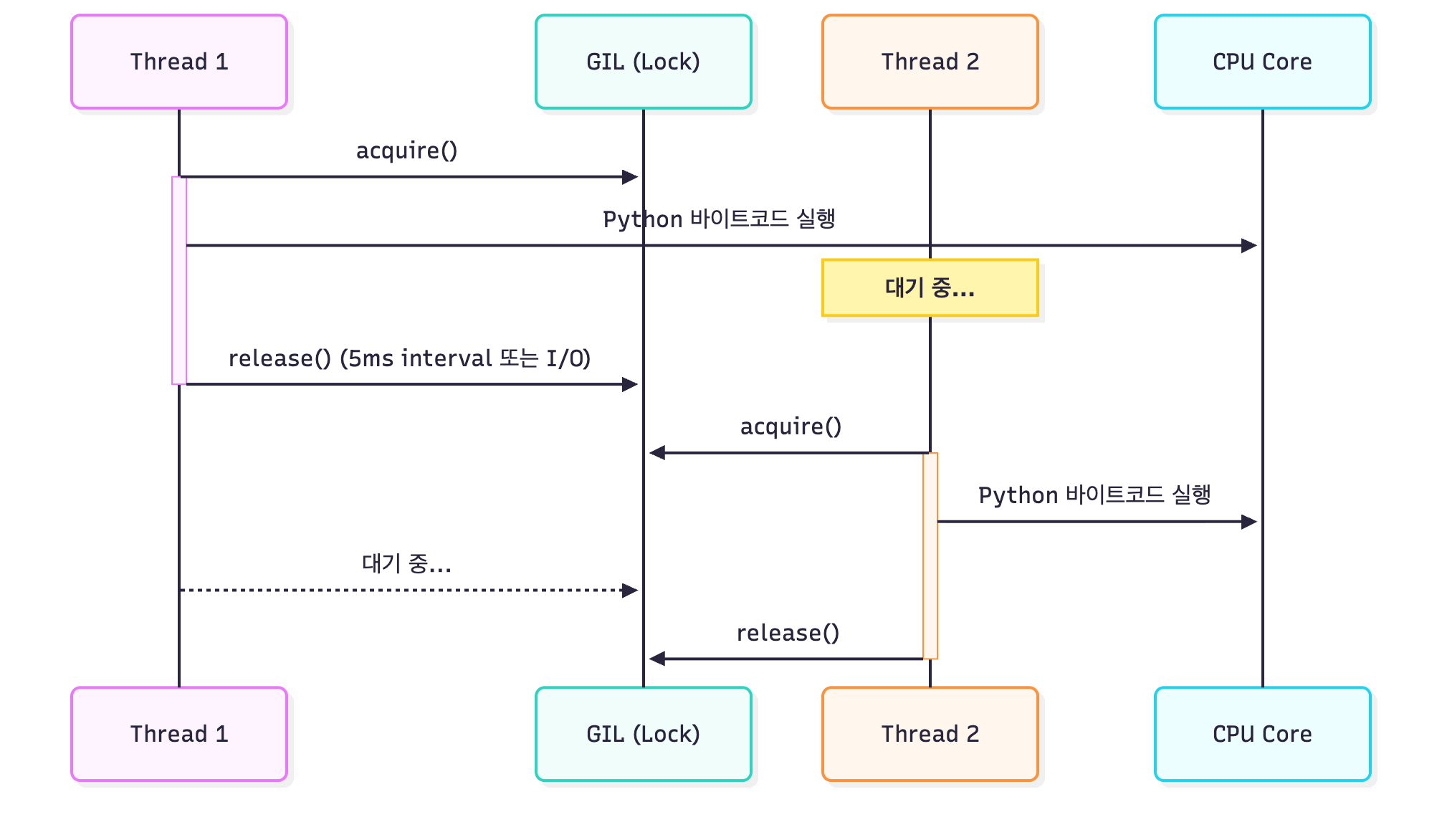
Python 3.2 기준으로 CPython은 기본적으로 5ms 간격으로 GIL을 해제하여 다른 스레드에게 실행 기회를 줍니다.
이 간격은 sys.getswitchinterval() 로 확인해볼 수 있습니다.
GIL은 왜 존재할까?
GIL 때문에 멀티스레드가 제한된다는 건 알겠습니다. 근데 왜 굳이 이런 제약을 만들었을까요? 동시성에 제약이 생긴다는 것은 많은 부분에서 성능 이슈들이 발생할 잠재적인 원인이 될 수 있는데 말이에요.
이해를 돕기 위해 CPython의 메모리 관리 방식을 조금 뜯어보았습니다.
CPython의 메모리 관리
CPython은 참조 카운팅(Reference Counting) 기반의 GC를 사용합니다.
import sys
a = [] # 리스트 객체 생성, refcount = 1
b = a # 같은 객체 참조, refcount = 2
print(sys.getrefcount(a)) # 3 (함수 인자로 전달되면서 +1)
del b # refcount = 2
del a # refcount = 1 → 스코프 종료 시 0 → 메모리 해제
모든 Pyhthon 객체는 내부적으로 ob_refcnt 라는 참조 카운터를 가지고 있어요.
typedef struct _object {
Py_ssize_t ob_refcnt; // 참조 카운트
PyTypeObject *ob_type; // 타입 정보
} PyObject;
객체를 참조할 때마다 이 카운터가 증가하고, 참조가 해제되면 감소하는 구조입니다. 카운터가 0이 되면 메모리에서 해제되는거죠.
GIL이 없다면?
만약 GIL이 없어 여러 스레드가 동시에 같은 객체를 참조한다면, 예상하시다시피 Race Condition이 발생하게 되죠.
이 현상은 참조 카운터에도 동일하게 적용됩니다.
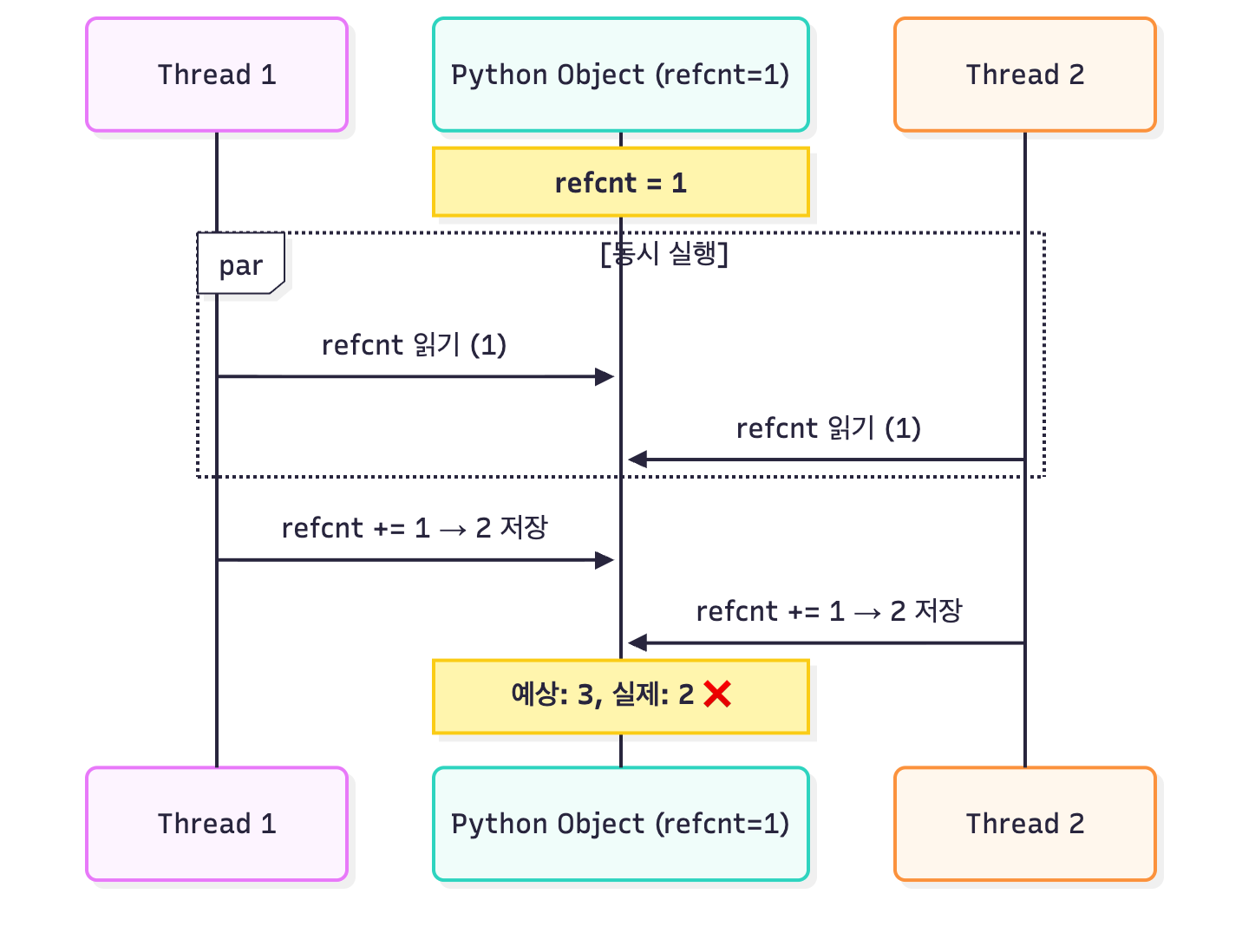
현재 참조 카운트가 1인 객체를 스레드 1과 스레드 2가 동시에 참조했습니다.
두 번의 참조가 추가되었기 때문에 당연히 3일 줄 알았지만 결과는 2가 될 수 있어요.
이런 상황이 반복되면 실제로 참조중이지만 GC에 의해 객체가 메모리에서 해제되어 참조에 실패하게되고
반대의 경우에는 참조가 끝났지만 메모리에 남아있어 메모리 누수가 발생하게 됩니다.
왜 하필 GIL인가?
여기까지 이해한 내용을 바탕으로 곱씹어보니, 참조 카운트마다 개별 락을 걸어도 될 것 같다는 생각이 들었습니다.
물론 당연히 구현 복잡도는 올라가겠지만 현대의 프로그래밍에서 이 정도의 복잡성을 해결하지 못할 리가 없으니까요.
하지만, Python이 만들어졌을 때는 1991년으로 싱글 코어 CPU가 일반적이었다고 해요.
GIL은 그 당시 시대성을 반영한 단일 스레드 성능의 최적화 라는 관점에서의 합리적인 선택이었다고 합니다.
Node와의 동시성 모델 비교
저를 포함한 Node 개발자 입장에서 동시성 처리에 혼동이 오는 이유는, Node의 동시성과 병렬 처리 방식과 Python의 방식이 다르기 때문이라고 생각합니다.

Node와 JavaScript의 철학은 다음과 같죠
- JavaScript 코드는 싱글 스레드에서 실행
- I/O 작업은 libuv의 스레드 풀에서, 또는 OS 비동기 API로 위임
- I/O 완료를 기다리지 않고 다음 작업을 진행하는 Non-Blocking 모델
- 콜백과 Promise로 결과 처리
const fs = require('fs').promises;
async function readFiles() {
// 두 파일 읽기가 "동시에" 진행
const [file1, file2] = await Promise.all([
fs.readFile('a.txt'),
fs.readFile('b.txt')
]);
return [file1, file2];
}
Node가 싱글 스레드 + 이벤트 루프인데 반해 CPython은 멀티스레드 + GIL 조합을 사용합니다.

여러 스레드를 생성할 수 있지만, GIL 때문에 Python 코드를 실행하는 스레드는 하나일 수밖에 없습니다.
데이터베이스의 락처럼, 해제를 기다리게 되죠. (단, I/O 작업에는 GIL이 해제되어 다른 스레드가 실행될 수 있습니다.)
NodeJS에서 Promise.all로 동시에 파일을 읽었다면, Python에서는 스레드를 직접 생성해서 처리합니다.
import threading
def read_file(filename):
with open(filename) as f:
return f.read()
# 스레드 생성
t1 = threading.Thread(target=read_file, args=('a.txt',))
t2 = threading.Thread(target=read_file, args=('b.txt',))
t1.start()
t2.start()
t1.join()
t2.join()
차이점 정리

CPU bound 와 I/O bound
GIL의 영향이 작업 유형에 따라 달라지는데요.
CPU bound 작업과 I/O bound 작업을 비교해보겠습니다.
CPU bound
CPU bound 작업에서는 멀티스레드를 활용하더라도 작업 속도 개선에 도움되지 않는데요. 바로 코드로 확인해보겠습니다.
import threading
import multiprocessing
import time
def count_primenum(n):
"""2부터 n-1까지 소수 개수 세기"""
count = 0
for i in range(2, n):
if all(i % j != 0 for j in range(2, int(i**0.5) + 1)):
count += 1
return count
def main():
N = 1000000
# 순차 실행
start = time.time()
count_primenum(N)
count_primenum(N)
print(f"순차: {time.time() - start:.2f}초")
# 멀티스레드 실행
start = time.time()
t1 = threading.Thread(target=count_primenum, args=(N,))
t2 = threading.Thread(target=count_primenum, args=(N,))
t1.start()
t2.start()
t1.join()
t2.join()
print(f"멀티스레드: {time.time() - start:.2f}초")
# 멀티프로세싱 실행
start = time.time()
with multiprocessing.Pool(2) as p:
p.map(count_primenum, [N, N])
print(f"멀티프로세싱: {time.time() - start:.2f}초")
if __name__ == '__main__':
main()

순차 실행과 멀티 스레드의 실행 속도가 거의 동일합니다.
GIL 때문에 두 스레드가 번갈아 실행되지만, 결국 한 번에 하나의 스레드만 Python 코드를 실행하기 때문에 총 소요 시간은 순차 실행과 다를 바가 없습니다. 별개로 위 예제에서는 멀티프로세싱은 프로세스를 여러 대 활용하는 것이기 때문에, 영향을 받지 않습니다.
공부하면서 코드로 실제로 확인해보고나니 오히려 스레드가 많아지면 GIL 획득과 해제 오버헤드가 추가되어 더 느려질 수도 있겠다는 생각이 드네요. GIL의 간격마다 해제되고 새로 GIL을 획득하는 과정을 반복하게 되기 때문이겠죠.
I/O bound
위에서 언급했다시피 I/O 작업에서는 조금 다른데요. 블로킹 작업에서는 GIL이 해제됩니다.
import threading
import time
import requests
URL = "https://example.com"
def io_work():
requests.get(URL)
def run_sequential(num_requests=20):
start = time.time()
for _ in range(num_requests):
io_work()
return time.time() - start
def run_threads(num_threads=20):
threads = []
start = time.time()
for _ in range(num_threads):
t = threading.Thread(target=io_work)
t.start()
threads.append(t)
for t in threads:
t.join()
return time.time() - start
if __name__ == "__main__":
print(f"순차 (20회): {run_sequential(20):.2f}초")
print(f"멀티스레드 (20개): {run_threads(20):.2f}초")

CPU 작업과는 달리 20개 요청이 거의 단일 요청 시간과 비슷하게 완료되는데요.
스레드에서 I/O 대기중에는 GIL이 해제되기 때문에, 다른 스레드에서 GIL을 획득하여 그 시간을 활용할 수 있습니다.

20개의 스레드는 너무 많기에, 3개만 압축해서 플로우 차트를 그려봤어요.
세 개의 스레드로도 복잡한데요. 요약하자면 Python 코드, 즉 바이트 코드를 실행하기 위해서 GIL이 필요합니다.
하지만 I/O bound는 커널 혹은 OS 레벨의 작업이 필요하기 때문에 GIL을 반환하게 돼요. 이 때 다른 스레드에서 GIL을 획득해요.
백그라운드 작업이 끝난 뒤에도 마찬가지입니다. 그 뒤에 실행 로직들이 있다면 다시 GIL을 획득해야만 작업할 수 있어요.


다시 정리하겠습니다.
I/O 대기중에는 GIL이 풀리므로 다른 스레드가 그 시간을 활용할 수 있어요.
반면 CPU 작업에서는 GIL을 번갈아 잡기 때문에 스레드가 많을수록 오버헤드가 생깁니다.
동시성과 최적화 모두 잡기
GIL에 대해 알아봤어요.
그렇다면 극단적으로 보이는 GIL 위에서, 개발자인 저는 상황에 맞게 동시성을 제한하거나, 동시성을 극대화하는 등 다양한 방향으로 구현을 해야할텐데요. 실제로 어떻게 구현을 해야할까요? 무엇을 어떻게 써야할까요?
멀티프로세싱
위에서 보여드린 예제처럼, 멀티프로세싱을 활용하는 방법이 있습니다.
위 내용들에서 눈치채셨겠지만, GIL은 프로세스 단위로 존재해요.
스레드는 같은 프로세스 내에서 메모리를 공유하기 때문에 GIL로 동기화가 필요하지만, 프로세스는 완전히 독립된 메모리 공간을 가지기 때문에 독립적인 Python 인터프리터와 GIL을 갖게 됩니다. 즉 4개의 프로세스를 띄우면 4개의 GIL이 독립적으로 동작하고, 각 프로세스는 서로의 GIL에 영향을 받지 않아 병렬 실행이 가능해지죠.

아래의 상황에서 고려해볼 수 있을 것 같아요.
- CPU bound 작업이 명확한 이미지 처리나 연산 처리 등
- 작업 단위가 독립적이고 데이터/상태 공유가 적음
- 작업 하나의 실행 시간이 프로세스 생성 오버헤드보다 클 때
하지만 IPC 오버헤드가 우려되거나, 비동기 처리가 더 효율적일 때는 사용을 피하는 게 좋습니다.
비동기처리
NodeJS의 async/await와 유사한 모델인 asyncio를 사용할 수도 있어요.
asyncio는 코루틴 기반의 비동기처리 모델로 싱글 스레드에서 이벤트 루프를 통해 여러 I/O 작업을 동시에 처리합니다.
스레드를 여러 개 만들지 않고도 I/O 대기 시간을 효율적으로 활용할 수 있어요.
Node 개발자라면 익숙한 패턴이죠
import asyncio
import aiohttp
async def fetch_url(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ['https://example.com'] * 10
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
results = await asyncio.gather(*tasks)
return results
asyncio.run(main())
threading(멀티스레딩)과 asyncio는 뭐가 다를까요? 저는 위에서 threading 방식도 I/O bound 작업에 효과적이라고 언급했습니다.
핵심 차이는 동시성을 만드는 방식에 있어요.
- threading: OS가 스레드를 관리하고, OS가 컨텍스트 스위칭 결정
- asyncio: 이벤트 루프가 코루틴을 관리하고, await 지점에서 능동적으로 제어권을 넘김
이런 방식의 차이 때문에, asyncio는 스레드를 만들지 않기 때문에 컨텍스트 스위칭 오버헤드가 적고 메모리 사용량도 낮습니다.
동시 요청이 수백 ~ 수천 개로 늘어나도 threading처럼 리소스가 폭발적으로 사용되진 않아요.
다만 제약도 있습니다.
- 사용하는 라이브러리가 async를 지원해야함
- CPU bound 작업에는 여전히 적합하지 않음 (싱글 스레드니까)
일반적인 서버 애플리케이션은 네트워크, DB, 파일 등 I/O 작업 비중이 높기 때문에 async 지원 라이브러리를 쓰고 있다면 asyncio가 자연스러운 선택이 될거에요.
GIL을 해제하기
NumPy, Pandas 같은 라이브러리는 C로 작성된 부분에서 GIL을 해제한다고 합니다.
import numpy as np
# NumPy 연산은 C 레벨에서 GIL 해제 후 병렬 처리
a = np.random.rand(10000, 10000)
b = np.random.rand(10000, 10000)
c = np.dot(a, b)
또, Cython에서는 명시적으로 GIL을 해제할 수 있어요. 마치 free 처럼요
# example.pyx
from cython.parallel import prange
def parallel_sum(double[:] arr):
cdef double total = 0
cdef int i
with nogil: # GIL 해제
for i in prange(arr.shape[0]):
total += arr[i]
return total
Python ^3.13: Free Threaded Python
Python 3.13부터 Cpython에서는 GIL을 비활성화한 빌드인 free threading을 실험적으로 지원합니다.
자세한 내용은 PEP 703에서 제안한 Making the Global Interpreter Lock Optional in CPython을 확인해보시면 좋습니다.
저는 pyenv를 사용해서 한 번 적용해보겠습니다.
# free-threaded 버전 확인
pyenv install --list | grep 3.13t
# free-threaded 버전 설치 (3.13t가 있으면)
pyenv install 3.13t-dev # 또는 3.13.0t 같은 형식
# 해당 디렉토리에서 사용
pyenv local 3.13t-dev
import sys
print(sys._is_gil_enabled()) # False = Free-threaded
세팅을 마무리하고, 위의 CPU bound의 예제 코드인 primenum 코드를 다시 실행시켜볼게요.

이전 결과와는 많이 다른 모습을 볼 수 있어요. GIL이 없기 때문에 두 스레드가 각자의 CPU 코어에서 진짜 동시에 실행 된거죠.
주의사항: 명시적 동기화 필수
Free threaded가 적용된 Python에서는 GIL이 암묵적으로 보장하던 안전성이 사라집니다.
락이 걸리지 않고 동시에 같은 자원을 공유할 수 밖에 없기 때문에, Race Condition이 발생한다고 이해하면 쉬워요.
한 번 확인해보겠습니다.
import threading
shared_iter = iter(range(100000))
results = []
def consume():
for item in shared_iter:
results.append(item)
threads = []
for _ in range(10):
t = threading.Thread(target=consume)
t.start()
threads.append(t)
for t in threads:
t.join()
print(f"예상: 100000개, 실제: {len(results)}개")
print(f"중복 있음: {len(results) != len(set(results))}")
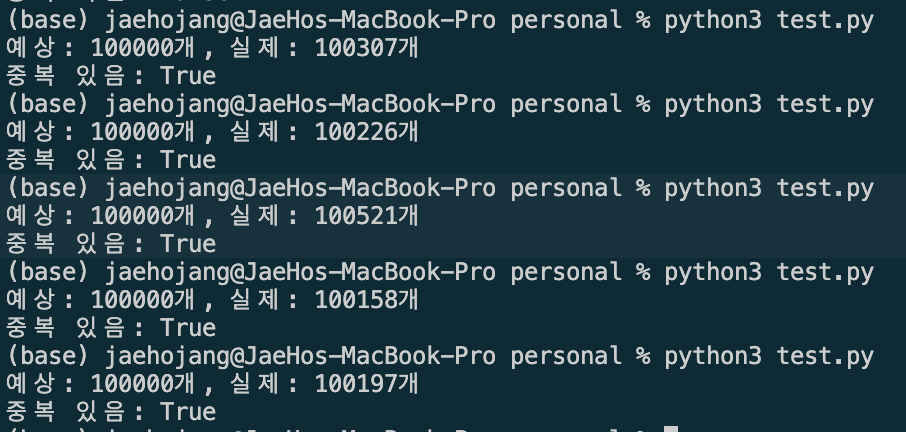
간단하게, 여러 스레드에서 공유하는 하나의 이터레이터를 카운팅하는 로직을 만들어봤습니다.
결과는 보시다시피 서로 공유된 자원을 마구마구 침범하는(?) 결과를 보실 수 있어요.
이런 문제가 발생하지 않게 하기 위해서는, 공유 자원을 적절하게 관리하는 추가적인 방법을 생각해야합니다.
GIL 제거 로드맵
PEP 703에서 정리한 GIL 제거에 대한 내용을 로드맵 형태로 정리해봤습니다.

아마 이 GIL이 구시대에 적합한 유물(?)이다보니 제거하는 방향으로 나아가고 있는 것 같아요.
정리
제가 GIL을 바라보는 시각은 여전히 부정적이에요.
하지만 저는 개발을 2022년, 매우 현대적인 환경에서 접했고 Python이 태어난 년도와는 근본적으로 여러 환경의 차이가 있습니다.
그 당시의 CPython을 개발할 때, 당시 시대상을 반영한 동시성/성능의 타협점이 아니었을까 생각합니다.
Python 또한 이런 문제점들을 개선하기 위해 GIL을 제거하려고 준비하고 있으니 제가 현재 속해있는 레거시 환경에서도 변화를 적용할 준비를 해야겠습니다. (아직 3.9버전대를 사용중이에요)
Node에서 Python으로 스택 전환을 하면서, 해당 기술의 컨셉들을 하나씩 파보는 것을 목표로 하고 있어요.
다음 포스팅은, 또 다른 레거시의 산물인 WSGI에 대해 조금 깊게 들여다보려고 합니다.
References
https://wiki.python.org/moin/GlobalInterpreterLock
https://docs.python.org/3/library/threading.html
https://docs.python.org/3/c-api/init.html
https://peps.python.org/pep-0703
https://peps.python.org/pep-0779
https://docs.python.org/3/howto/free-threading-python.html
https://docs.python.org/3/whatsnew/3.13.html
https://realpython.com/python313-free-threading-jit
