https://redis.io/docs/latest/develop/data-types
레디스는 캐싱부터 큐잉, 이벤트 처리 등의 비즈니스 문제를 다양하게 해결할 수 있도록 다양한 데이터 타입들을 제공한다.
과금 모델인 Enterprise 명령어는 제외했으며, 포스팅 외의 공식문서를 참조하고 싶다면 각 링크들을 참조하자.
String
- 512MB 미만의 일반적인 문자열을 저장할 수 있다. 직렬화된 객체나 이진 배열을 포함한다.
- 바이너리 데이터를 포함할 수 있어 이미지 저장이 가능하다.
- HTML Fragments, 페이지 등의 캐싱에 유용하다.
- 증감 연산을 사용할 수 있다. (INCR, DECR)
- SETEX, PSETEX, SETNX는 2.6.12버전부터 deprecated되었고, SET에서 통합하여 사용이 가능하다.
127.0.0.1:6379> SET STRING1 "STRING1"
OK
127.0.0.1:6379> GET STRING1
"STRING1"
127.0.0.1:6379> SET STRING1 "STRING1" NX
(nil)
127.0.0.1:6379> SET STRING1 "STRING2" XX
OK
127.0.0.1:6379> GET STRING1
"STRING2"
127.0.0.1:6379> SET STRING2 "STRING2" EX 1
OK
# 1초 뒤
127.0.0.1:6379> GET STRING2
(nil)
SET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SET | key value [NX | XX] [GET] [EX s | PX ms | EXAT unix-s | PXAT unix-ms | KEEPTTL] |
데이터를 저장한다. key가 있으면 덮어쓴다. | O(1) |
| SETRANGE | key offset value | 지정된 offset에서 시작하여 value의 전체 길이로 덮어쓴다. | O(1) |
| MSET | key value [key value ...] | 여러 데이터를 한 번에 저장한다. | O(N) |
| MSETNX | key value [key value ...] | 여러 데이터를 한 번에 저장한다. 이미 존재하는 키가 있을 경우, 아무 작업도 수행하지 않는다. |
O(N) |
| APPEND | key value | 데이터가 존재하는 경우, value를 추가한다. 데이터가 존재하지 않을 경우 데이터를 저장한다 (=SET) |
O(1) |
- NX(Not Exists) | XX(Exists): key가 없을 경우에만 저장 | 존재할 경우 업데이트
- EX | PX: 초 단위, 밀리초 단위 만료 설정
- EXAT | PXAT: 초 단위의 unixtimestamp 만료 설정, 밀리초 단위의 unixtimestamp 만료 설정
- KEEPTTL: 업데이트 시 기존 TTL을 유지
GET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| GET | key | key에 해당하는 value를 조회한다. | O(1) |
| GETRANGE | key start end | start ~ end의 idx에 해당하는 value를 조회한다. (substr) | O(N) |
| MGET | key [key ...] | key에 해당하는 value들을 조회한다. | O(N) |
| STRLEN | key | value의 길이를 조회한다. | O(1) |
INCR 명령어
64비트 Integer 혹은 Float를 증감시킨다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| INCR | key | value를 1 증가시킨다. | O(1) |
| INCRBY | key increment | increment만큼 value를 증가시킨다. | O(1) |
| INCRBYFLOAT | key increment | increment만큼 부동소수점을 증감시킨다. | O(1) |
| DECR | key | value를 1 감소시킨다. | O(1) |
| DECRBY | key decrement | decrement만큼 value를 감소시킨다. | O(1) |
기타
| 명령어 | 구문 | 설명 | 시간복잡도 |
| GETDEL | key | key에 해당하는 value를 조회하고, 삭제한다. | O(1) |
| GETEX | key [EX s | PX ms | EXAT unix-s | PXAT unix-ms | PERSIST] |
key에 해당하는 value를 조회하고, 만료일을 설정할 수 있다. | O(1) |
| GETSET | key value | key에 해당하는 value를 조회하고, value로 덮어씌운다. | O(1) |
| LCS | key1 key2 [LEN] [IDX] [MINMATCHLEN min-match-len] [WITHMATCHLEN] |
O(key1*key2)의 LCS(Longest Common Subsequence)를 가져온다. | O(N*M) |
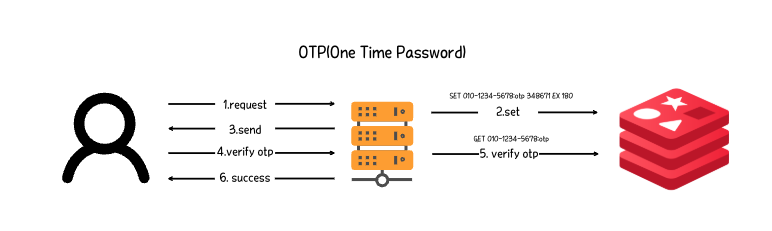
활용 예시
회원가입, 정보 변경 등에 사용되는 휴대폰 인증 등의 OTP 등에 사용할 수 있다.
List
LinkedList로 저장한다.
- LinkedList의 특성에 맞게 데이터 추가와 삭제에 최적화되어있다. (O(1))
- LPUSH + LTRIM으로 List의 크기를 항상 일정하게 고정시킬 수 있다.
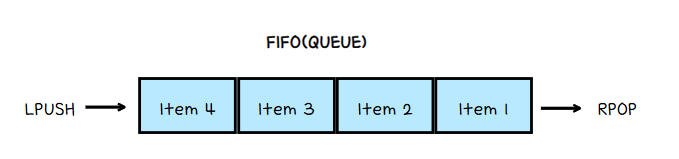
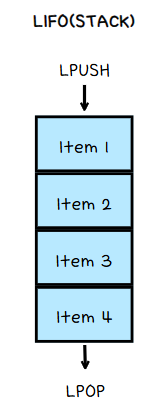
- Queue (LPUSH + RPOP) / Stack (LPUSH + LPOP) 으로 사용할 수 있다.
- 위의 특성들로 메세지 브로커를 구축하는 데 적합한 구조이다.
SET(PUSH) 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| LPUSH | key element [element ...] | 리스트의 0번째 index에 element를 저장한다. 리스트가 존재하지 않으면, 생성 후 저장한다. |
O(1) |
| LPUSHX | key element [element ...] | 리스트가 존재할 경우에만 LPUSH를 수행한다. | O(1) |
| LSET | key N element | 리스트의 N번째 index를 element로 덮어씌운다. 범위를 벗어난 index의 경우 Out Of Range 에러가 반환된다. |
O(N) |
| LINSERT | key <BEFORE | AFTER> N element |
첫 번째로 발견된 N 위치의 앞/뒤에 element를 저장한다. | O(N) |
| RPUSH | key element [element ...] | 리스트의 마지막 index에 element를 저장한다. 리스트가 존재하지 않으면, 생성 후 저장한다. |
O(1) |
| RPUSHX | key element [element ...] | 리스트가 존재할 경우에만 RPUSH를 수행한다. | O(1) |
GET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| LRAGNE | key S stop | start ~ end의 요소들을 조회한다. | O(S + N) |
| LINDEX | key index | index의 value를 조회한다. | O(N) |
| LLEN | key | 리스트의 LENGTH. | O(1) |
- O(S+N)에서의 S는 작은 리스트의 경우 HEAD에서부터 시작 인덱스 까지의 거리, 큰 리스트의 경우 HEAD / TAIL (가까운 끝지점)으로부터의 거리이다. N은 |stop - start| 값이다.
POP 명령어
기본적으로 POP이란, GET과 DELETE가 결합된, 데이터를 가져오고 리스트에서 삭제한다고 이해하면 된다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| LPOP | key [N] | 리스트의 0번째 index부터 데이터를 POP한다. | O(N) |
| LMPOP | N key [key ...] <LEFT | RIGHT> [COUNT M] |
여러 개의 리스트에서 여러 개의 요소를 한 번에 POP (N만큼의 리스트에서 LEFT|RIGHT의 방향에서 M만큼 POP) |
O(N + M) |
| RPOP | key [N] | 리스트의 마지막 index부터 데이터를 POP한다. | O(N) |
BLOCK 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| BLPOP | key [key ...] timeout | 리스트의 0번째 index를 POP. 리스트에 데이터가 없다면 timeout만큼 BLOCKING된다. |
O(N) |
| BLMOVE | source destination <LEFT | RIGHT> <LEFT | RIGHT> timeout |
LMOVE + BLOCKING | O(1) |
| BLMPOP | timeout N key [key ...] <LEFT | RIGHT> [COUNT M] |
timeout만큼 BLOCKING되는 LMPOP | O(N + M) |
| BRPOP | key [key ...] timeout | 리스트의 마지막 index를 POP. 리스트에 데이터가 없다면 timeout만큼 BLOCKING된다. |
O(N) |
| BRPOPLPUSH | source destination timeout |
BRPOP + LPUSH source 리스트에서 데이터를 꺼내서 destination의 왼쪽에 넣는다. |
O(1) |
- 리스트에 데이터가 들어올 때 까지 대기 할 수 있다는 특성을 이용하여 Task Queue, 실시간 이벤트 처리, 로드 밸런싱 등으로 활용된다.
기타 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| LMOVE | source destination <LEFT | RIGHT> <LEFT | RIGHT> |
source의 POP위치, destination의 SET 위치를 결정하여 source 리스트에서 destination 리스트로 데이터 이동. |
O(1) |
| LPOS | key element [RANK rank] [COUNT num-matches] [MAXLEN len] | 리스트 내에서 rank번째로 등장하는 element를 최대 count만큼 len 내에서 찾는다. |
O(N) |
| LTRIM | key start stop | start ~ stop 범위에 속하지 않는 데이터를 삭제한다. | O(N) |
127.0.0.1:6379> RPUSH LPOS A B C B E C B D
(integer) 8
127.0.0.1:6379> LRANGE LPOS 0 -1
1) "A"
2) "B"
3) "C"
4) "B"
5) "E"
6) "C"
7) "B"
8) "D"
127.0.0.1:6379> LPOS LPOS B
(integer) 1
127.0.0.1:6379> LPOS LPOS B RANK 2
(integer) 3
127.0.0.1:6379> LPOS LPOS B RANK 2 COUNT 2
1) (integer) 3
2) (integer) 6
127.0.0.1:6379> LPOS LPOS B RANK 3 COUNT 2
1) (integer) 6
127.0.0.1:6379> LPOS LPOS B MAXLEN 1
(nil)
127.0.0.1:6379> LPOS LPOS B COUNT 2 MAXLEN 4
1) (integer) 1
2) (integer) 3
Set
우리가 아는 그 Set 자료구조이다.
- 집합 연산(교집합, 합집합, 차집합 등)을 수행할 수 있다.
- 주로 관계를 나타낼 때 사용한다.
- Set의 저장 가능한 최대 원소 개수는 2^32-1개이다.
SET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SADD | key member [member ...] | 데이터를 저장한다. 이미 존재하는 데이터는 무시된다. | O(1) |
| SMOVE | source destination member |
source에서 destination으로 데이터를 옮긴다. 이미 존재한다면 추가되지 않는다. |
O(1) |
GET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SMEMBERS | key | SET 전체를 조회한다. | O(N) |
| SISMEMBER | key member | SET 내부에 member가 있다면 1, 없다면 0을 반환한다. | O(1) |
| SMISMEMBER | key member [member ...] |
SISMEMBER의 다중 검사 | O(N) |
| SRANDMEMBER | key [N] | SET의 임의의 데이터 N개를 반환한다. | O(N) |
| SCARD | key | 카디널리티를 반환한다. (SET은 중복이 불가능하므로 SIZE와 동일하다.) |
O(1) |
| SSCAN | key cursor [MATCH pattern] [COUNT count] |
SET 내부의 일정 단위 개수만큼 데이터를 가져온다. |
- SRANDMEMBER의 N
- 양수일 경우 반복되는 요소는 없으며, SET의 SIZE보다 클 경우 SET 전체를 반환한다.
- 음수일 경우 반복되는 요소가 존재하며, SET의 SIZE보다 크더라도 N개 만큼의 요소가 완전히 무작위로 반환된다.
- SSCAN
- 작은 데이터셋일 경우 COUNT와 무관하게 전체 데이터를 가져올 수 있다.
- 패턴은 item*처럼 패턴을 사용할 수 있다.
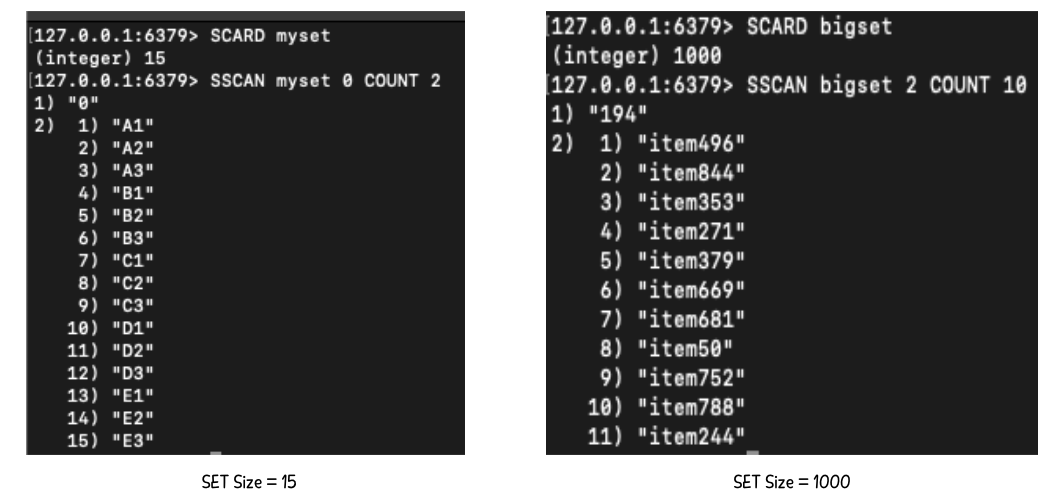
Redis의 SCAN 명령어(SSCAN, ZSCAN, HSCAN)는 모두 Hash Bucket 기반으로 동작한다.
명령어의 COUNT 옵션은 버킷 개수를 조정하는 힌트 역할을 하며 정확한 개수를 보장하지는 않는다.
데이터셋이 작다면 위 사진처럼 COUNT값을 조정해도 전체 데이터를 한 번에 반환할 가능성이 크다.
이러한 특징으로 대용량 데이터를 순회하는 데 유리하다.
POP 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SPOP | key [N] | SET의 임의의 데이터 N개를 POP | O(N) |
REMOVE 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SREM | key member [member ...] | SET에서 지정한 요소들을 삭제한다. | O(N) |
집합 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SUNION | key [key ...] | SET들의 합집합 | O(N) |
| SUNIONSTORE | destination key [key ...] | 합집합을 destination SET에 저장 | O(N) |
| SINTER | key [key ...] | SET들의 교집합 | O(N * M) |
| SINTERSTORE | destination key [key ...] | 교집합을 destination SET에 저장 | O(N * M) |
| SINTERCARD | M key [key ...] [LIMIT limit] |
교집합의 카디널리티(개수)를 반환 | O(N * M) |
| SDIFF | key [key ...] | SET들의 차집합 | O(N) |
| SDIFFSTORE | destination key [key ...] | 차집합을 destination SET에 저장 | O(N) |
활용 예시
좋아요 기능을 Set으로 간단하게 구현할 수 있다. 좋아요 기능처럼 자주 I/O가 발생하고, UNIQUE를 동시에 제어해야하는 상황 등에 알맞게 사용할 수 있다.
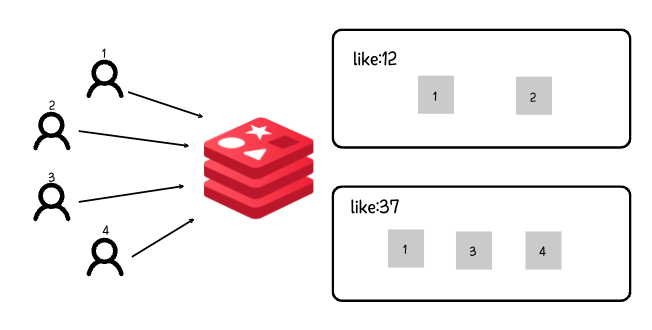
SortedSet (ZSet)
정렬을 지원하는 SET으로 SET에 저장된 score를 기준으로 자동 정렬된다.
- Skip List 구조로 정렬된 상태를 유지하며, 탐색에는 O(logN)의 시간이 걸림.
- 시간 기반 정렬과 범위 삭제(Sliding Window)에 최적화되어있다.
- 리더보드(랭킹)나 우선순위 큐(Priority Queue)를 쉽게 구현할 수 있다.
- ZREMRANGEBYSCORE, ZCOUNT를 활용하여 Rate Limiter을 쉽게 구현할 수 있다.
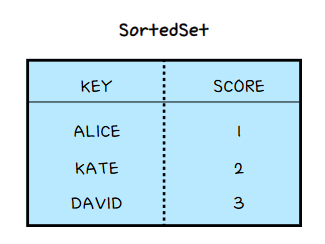
특정 API에 Rate Limit을 설정하고 싶다고 해보자. 내가 설정한 정책은 1분에 5번의 요청만 가능하도록 설정해두었다. 이럴 때 아래처럼 URI:User로 SortedSet을 생성하여, 요청에 대한 시간값을 score로 담는다. 요청을 수행하기 전에 ZCOUNT로 60초 이내에 해당 유저가 몇 번 요청을 하였는지 확인하고 5번을 초과하였다면 429를 반환할 수 있다. 60초가 지났다면 ZREMRANGEBYSCORE를 통해 범위 밖의 데이터들을 초기화해줄 수 있다.
SET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| ZADD | key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...] |
score을 가진 요소를 추가한다. | O(logN) |
- NX(Not Exists) | XX(Exists): 새로운 요소만 추가 | 기존 요소를 업데이트
- LT(Less Than) | GT(Greater Than): 요소가 이미 있을 때, 현재 score보다 낮거나 높은 경우에만 추가한다.
- CH(Changed): 변경된 요소의 개수를 반환한다. (설정하지 않으면 변경되었는지 보이지 않는다.)
- INCR(Increase): 요소가 있다면 score만큼 누적시킨다. (없다면 요소를 추가)
GET 명령어
ZRANGEBYLEX, ZRANGEBYSCORE, ZREVERANGE, ZREVERANGEBYSCORE, ZREVERANGEBYLEX는 6.2.0버전부터 deprecated되었고, ZRANGE에 통합하여 사용이 가능하다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| ZRANGE | key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES] |
start ~ stop의 인덱스 요소를 반환 | O(logN + M) |
| ZCARD | key | 카디널리티(개수)를 반환 | O(1) |
| ZCOUNT | key min max | score 범위의 개수를 반환 '(' 를 사용해서 초과, 미만 표현 가능 |
O(logN) |
| ZLEXCOUNT | key min max | member로 범위의 개수를 반환 '['를 붙여 사용하며, '(' 를 사용해서 초과, 미만 표현 가능 |
O(logN) |
| ZSCAN | key cursor [MATCH pattern] [COUNT count] |
SET의 SSCAN과 동일 | O(1) |
| ZSCORE | key member | member의 score를 반환 | O(1) |
| ZRANK | key member [WITHSCORE] |
member의 현재 rank를 반환 | O(logN) |
| ZREVRANK | key member [WITHSCORE] |
member의 현재 rank를 DESC로 반환 | O(logN) |
- BYSCORE: score기준으로 범위 검색 (ZRANGEBYSCORE)
- BYLEX: 알파벳 정렬 범위 검색 (ZRANGEBYLEX)
- REV(Reverse): 내림차순 정렬 (ZREVRANGE)
- LIMIT: 페이징처리
- WITHSCORE: score도 함께 반환 (RANK)
POP 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| ZPOPMIN | key [count] | count개 만큼 score가 낮은(rank가 높은) 요소를 POP | O(logN * M) |
| ZPOPMAX | key [count] | count개 만큼 score가 높은(rank가 낮은) 요소를 POP | O(logN * M) |
| ZMPOP | K key [key ...] <MIN | MAX> [COUNT count] |
여러 개의 SortedSet에서 ZPOPMIN | ZPOPMAX | O(K) + O(logN * M) |
| BZPOPMIN | key [key ...] timeout | BLOCKING이 추가된Z POPMIN 비어있으면 새 데이터가 추가될 때까지 timeout만큼 대기 후 POP |
O(logN) |
| BZPOPMAX | key [key ...] timeout | BLOCKING이 추가된 ZPOPMAX 비어있으면 새 데이터가 추가될 때까지 timeout만큼 대기 후 POP |
O(logN) |
| BZMPOP | timeout K key [key ...] <MIN | MAX> [COUNT count] |
여러 개의 SortedSet에서 BZPOPMIN | BZPOPMAX | O(K) + O(logN * M) |
REMOVE 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| ZREM | key member [member ...] |
member를 REMOVE | O(logN * M) |
| ZREMRANGEBYRANK | key start stop | rank의 start ~ stop 범위를 REMOVE | O(logN + M) |
| ZREMRANGEBYSCORE | key min max | score의 min ~ max 범위를 REMOVE '(' 를 사용해서 초과, 미만 표현 가능 |
O(logN + M) |
| ZREMRANGEBYLEX | key min max | member의 min ~ max 범위를 REMOVE '['를 붙여 사용하며, '(' 를 사용해서 초과, 미만 표현 가능 |
O(logN + M) |
INCR 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| ZINCRBY | key increment member |
member의 score를 increment만큼 증가 | O(logN) |
집합 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| ZUNION | numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>] [WITHSCORES] |
여러 개의 SortedSet의 합집합 | O(N) + O(MlogM) |
| ZUNIONSTORE | destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>] |
여러 개의 SortedSet의 합집합을 새로운 ZSET에 저장 | O(N) + O(MlogM) |
- WEIGHTS: 가중치 (key들에 대한 곱연산 적용)
- AGGREGATE: 중복 요소를 합치는 방식 (SUM, MIN, MAX)
- destination: 새로 생성할 ZSET key
활용 예시
SortedSet을 활용하여 트래픽 제어를 통한 안정성 확보 뿐 아니라 위처럼 과금별 Rate Limits를 제어하는 등의 비즈니스 모델도 수립할 수 있다. 이와 같은 Window Rate Limiter을 SortedSet을 통해 정책 시간 별 카디널리티가 초과되었다면 429를 반환하여 Rate Limiter을 구현할 수 있다.

Hash
Field - Value형태로 Map / Dictionary 형태와 유사하다.
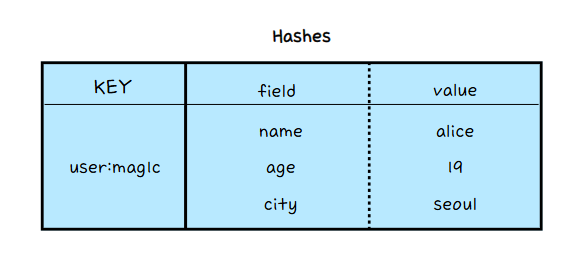
SET 명령어
HMSET은 4.0.0버전부터 deprecated되었고, HSET을 사용하여 Multi-Set이 가능하다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| HSET | key field value [field value ...] |
field와 value를 SET | O(N) |
| HSETNX | key field value | field가 없을 경우 value를 SET | O(1) |
GET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| HGET | key field | field의 value를 반환 | O(1) |
| HMGET | key field [field ...] | field들의 values 반환 | O(N) |
| HGETALL | key | Hash의 field, value를 전부 반환 | O(N) |
| HKEYS | key | Hash의 fields를 반환 | O(N) |
| HVALS | key | Hash의 values를 반환 | O(N) |
| HLEN | key | fields 개수를 반환 | O(1) |
| HSTRLEN | key field | field의 value LENGTH를 반환 | O(1) |
| HSCAN | key cursor [MATCH pattern] [COUNT count] [NOVALUES] |
Hash 내부의 일정 개수만큼 field / value를 반환 NOVALUES를 사용하면 field만 반환 |
O(N) |
| HEXISTS | key field | field가 있다면 1, 없다면 0을 반환 | O(1) |
REMOVE 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| HDEL | key field [field ...] | fields REMOVE | O(N) |
INCR 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| HINCRBY | key field increment | Integer을 increment만큼 증가시킨다. | O(1) |
| HINCRBYFLOAT | key field increment | Float을 increment만큼 증가시킨다. | O(1) |
Streams
로그 데이터를 처리하기 위해 5.0버전에서 도입된 데이터 타입이다. Append-Only, 즉 데이터의 추가만 가능하다. Redis의 영속성을 지원하는 AOF(Append-Only File)도 Append-Only 로그의 일종이다.
- Stream에 추가되는 메세지(이벤트)는 UUID를 가지며 해당 field를 읽을 때 O(1)의 시간 복잡도를 가진다.
- Consumer Group이 포함되어있다. Consumer Group을 이용하여 분산시스템의 다수의 컨슈머의 메세지 처리 과정에서 중복 문제를 쉽게 해결할 수 있다.
- Kafka등의 메세지 스트리밍 시스템과 유사하게 동작한다.
- 주로 이벤트 로그 저장, 실시간 데이터 처리, Pub/Sub 메세지 큐 등의 용도로 활용된다.
- 데이터 순서 보장이 필요한 경우 적합하다.

SET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| XADD | key [NOMKSTREAM] [<MAXLEN | MINID> [= | ~] threshold [LIMIT count]] <* | id> field value [field value ...] |
Integer을 increment만큼 증가시킨다. | O(N) |
- NOMKSTREAM: 스트림이 존재하지 않으면 생성하지 않음
- MAXLEN | MINID: 최대 메세지 개수 제한 (FIFO) | 특정 ID보다 작은 메세지를 삭제
- MINID: 특정 ID보다 작은 메세지를 삭제
- = | ~: Strict | Approximate
- threshold: 최대 개수 | 최소 ID를 반환
- LIMIT count: 한 번에 삭제할 최대 개수
- * | id: 자동 ID 생성(unix timestamp) | 사용자가 직접 ID를 지정 (timestamp - sequence)
GET 명령어
XREAD를 사용하여 실시간 데이터 처리가 용이하다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| XRANGE | key start end [COUNT count] |
start ~ end의 스트림 반환 | O(N) |
| XREVRANGE | key start end [COUNT count] |
start ~ end의 스트림 역순 반환 | O(N) |
| XREAD | [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...] |
여러 키의 스트림에서 특정 id 이후의 메세지를 동시에 반환 BLOCKING을 활용한 비동기처리 가능. |
|
| XLEN | key | 스트림 내 총 메세지 개수 조회 | O(1) |
REMOVE 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| XDEL | key id [id ...] | 스트림 삭제 | O(1) |
| XTRIM | key <MAXLEN | MINID> [= | ~] threshold [LIMIT count] |
조건에 따라 스트림의 메세지를 삭제 | O(N) |
컨슈머 그룹 명령어
XREADGROUP은 컨슈머 그룹을 사용해 메세지를 여러 개의 컨슈머에 분배하는 명령어이다. 한 메세지는 한 컨슈머에게만 전달되며, 그룹 내부에서는 PEL(Pending Entries List)을 관리하여 메세지 상태를 추적할 수 있으며 비동기 방식(BLOCK)으로 사용이 가능하다.
PEL(Pending Entries List)
컨슈머 그룹이 메세지를 읽을 때 Redis에서는 PEL에 메세지를 저장하고 XACK를 호출해야 메세지가 PEL에서 제거된다. PEL에 남아있는 메세지는 처리 중이거나 실패한 메세지로 간주된다. 하지만 NOACK 옵션을 통해 자동으로 Acked(확인)된 것으로 간주하여 PEL에 저장하지 않을 수도 있다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| XACK | key group id [id ...] | 컨슈머에 메세지 처리 완료 알림 처리. 컨슈머 그룹의 PEL에서 메세지 삭제. |
O(1) |
| XCLAME | key group consumer min-idle-time id [id ...] [IDLE ms] [TIME unix-mils] [RETRYCOUNT count] [FORCE] [JUSTID] [LASTID lastid] |
미처리 메세지를 다른 컨슈머에 재할당 | O(logN) |
| XAUTOCLAME | key group consumer min-idle-time start [COUNT count] [JUSTID] |
오래된 미처리 메세지를 자동으로 재할당 XCLAME + XPENDING |
O(1) |
| XREADGROUP | GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...] |
컨슈머 그룹을 활용한 메세지 분배 후 POP | O(N) |
| XPENDING | key group [[IDLE min-idle-time] start end count [consumer]] |
컨슈머 그룹의 미처리 메세지 조회 | O(N) |
| XGROUP | CREATE key group <id | $> [MKSTREAM] [ENTRIESREAD entries-read] |
새로운 컨슈머 그룹 생성 | O(1) |
| CREATECONSUMER key group consumer |
특정 컨슈머 그룹에 새로운 컨슈머 추가 | O(1) | |
| SETID key group <id | $> [ENTRIESREAD entries-read] |
컨슈머 그룹의 마지막 메시지 ID 변경 | O(1) | |
| DELCONSUMER key group consumer |
컨슈머 그룹에서 특정 컨슈머 제거 | ||
| DESTROY key group | 컨슈머 그룹 제거 | O(N) |
- min-idle-time: 최소 대기 시간 (이 시간 동안 PEL에 있던 메세지만 가져옴)
- FORCE: 기존 컨슈머가 존재하지 않아도 강제로 메세지를 가져옴
- JUSTID: 메세지 ID만 반환
기타 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| XINFO | GROUPS key | 컨슈머 그룹 메타데이터 반환 | O(1) |
| STREAM key [FULL [COUNT count]] |
스트림 메타데이터 반환 | O(1) |
Geospatials
좌표를 저장하고 검색할 수 있는 데이터 타입으로 거리 계산, 범위 탐색 등을 지원한다. SortedSet에 저장되기 때문에, ZSET 명령어를 통한 조회, 삭제 등이 가능하다.
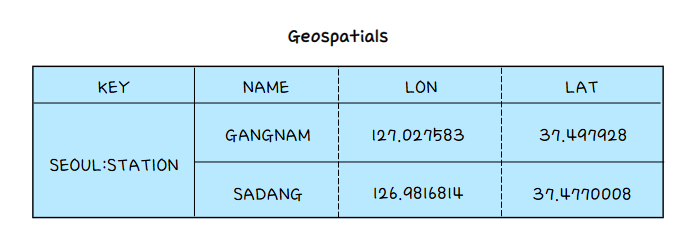
SET 명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| GEOADD | key [NX | XX] [CH] longitude latitude member [longitude latitude member ...] |
지리 정보(경도, 위도, 이름)를 추가한다. | O(logN) |
GET 명령어
GEORADIUS 명령어들은 6.2.0버전부터 deprecated되었다. GEOSEARCH에 통합하여 사용이 가능하다.
| 명령어 | 구문 | 설명 | 시간복잡도 |
| GEOPOS | key [member [member ...]] | 특정 위치의 좌표(Lat, Lon) 조회 | O(1) |
| GEODIST | key member1 member2 [M | KM | FT | MI] |
두 지점 간의 거리 계산 | O(1) |
| GEOHASH | key [member [member ...]] | 특정 위치의 Geohash 값을 반환 | O(1) |
| GEOSEARCH | key <FROMMEMBER member | FROMLONLAT longitude latitude> <BYRADIUS radius <M | KM | FT | MI> | BYBOX width height <M | KM | FT | MI>> [ASC | DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST] [WITHHASH] |
지정된 범위 내 위치 검색 | O(logN + M) |
| GEOSEARCHSTORE | destination source <FROMMEMBER member | FROMLONLAT longitude latitude> <BYRADIUS radius <M | KM | FT | MI> | BYBOX width height <M | KM | FT | MI>> [ASC | DESC] [COUNT count [ANY]] [STOREDIST] |
위치 검색 후 결과를 새로운 GEO에 저장 | O(logN + M) |
- FROMMEMBER: 특정 멤버 기준으로 검색
- FROMLONLAT: 특정 좌표에서 검색
- BYRADIUS: 특정 반경 내에서 검색
- BYBOX: width * height 크기의 BOX 내에서 검색
- COUNT: 가져올 결과 개수 (ANY를 사용 시 성능 최적화)
- WITHCORD: 위치 좌표를 함께 반환
- WITHDIST: 거리를 함께 반환
- WITHHASH: GEOHASH를 함께 반환
Geospatial을 이용해 홍대 ~ 강남역 까지의 직선거리를 구해보자.
GEOADD TEST 127.027583 37.497928 GANGNAM
(integer) 1
127.0.0.1:6379> GEODIST TEST GANGNAM HONGDAE KM
"11.2561"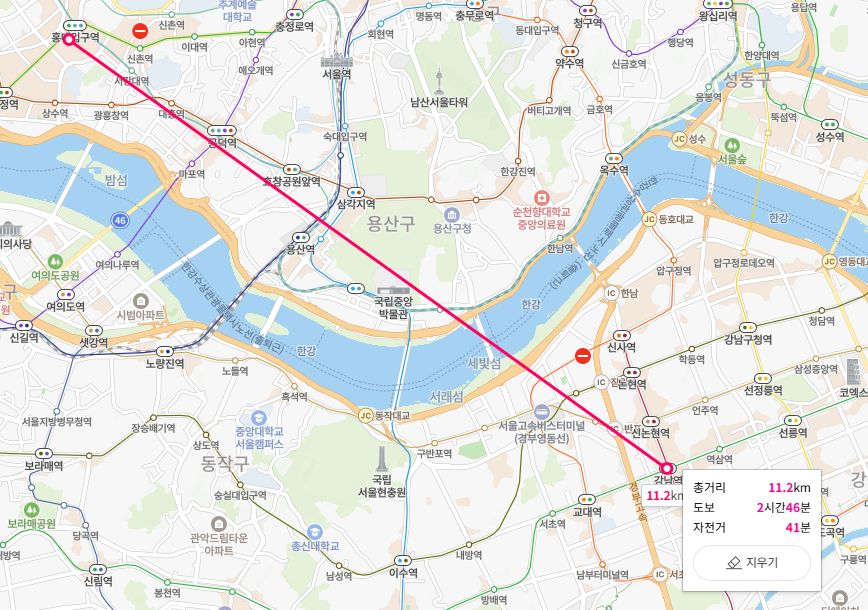
추가로, 반경과 x*y 박스의 범위검색 또한 가능하다.
Bitmaps
실제의 데이터 타입은 아니며, String 타입을 기반으로 비트 단위 연산을 지원한다. 비트 단위로 값을 설정하고 읽을 수 있기 때문에, 매우 작은 메모리 공간으로도 데이터를 표현할 수 있으며, 효율적인 공간 활용 및 빠른 연산이 특징이다. 사용자 로그인 여부, 출석 체크, 중복 체크 등의 비트로도 수행할 수 있는 연산에 활용하면 효율적이다.
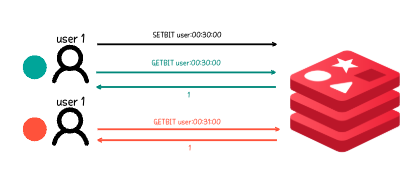
# 로그인 기록으로 사용
SETBIT user:1001 0 1 # 첫날 로그인
SETBIT user:1001 1 0 # 둘째 날 미로그인
SETBIT user:1001 2 1 # 셋째 날 로그인
명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| SETBIT | key offset value | offset에 value를 저장 | O(1) |
| GETBIT | key offset | offset의 비트 값을 반환 | O(1) |
| BITCOUNT | key [start end [BYTE | BIT]] |
1로 설정된 비트 개수를 반환 | O(N) |
| BITOP | <AND | OR | XOR | NOT> destkey key [key ...] |
비트 연산 결과를 destkey의 새로운 Bitmaps에 저장 | O(N) |
| BITPOS | key bit [start [end [BYTE | BIT]]] |
지정한 비트가 처음으로 등장하는 위치를 반환 | O(N) |
| BITFIELD | key [subcommand [argument] ...] |
더 작은 크기의 정수 필드 단위로 읽고 수정하는 명령어. | O(1) |
활용 예시
온라인 상태 표시 등의 수시로 변경되는 값에 사용한다.
HyperLogLogs
집합의 카디널리티를 추정할 수 있는 확률형 자료구조이다.
- member의 값을 해싱하여 버킷에 해시 값에 맞게 표시한다.
- 동일한 아이템이 추가 될 경우 카디널리티를 일정하게 계산할 수 있다.
- Set과 유사하지만 실제 값을 저장하지 않기 때문에 매우 작은 저장 공간(12kb)을 사용한다.
- 실제 값을 저장하지 않기 때문에 저장된 데이터를 다시 확인할 수 없다.
- 확률적인 계산식을 사용하기 때문에 결과값이 실제와 일정 부분 오차가 발생할 수 있다.
- 정확성을 일부 포기하는 대신 저장 공간을 효율적으로 사용할 수 있으며, 평균 에러율은 0.81%이다.
명령어
| 명령어 | 구문 | 설명 | 시간복잡도 |
| PFADD | key [element [element ...]] | 요소를 저장 | O(1) |
| PFCOUNT | key [key ...] | 저장된 요소의 개수(카디널리티)를 반환 | O(1) |
| PFMERGE | destkey [sourcekey [sourcekey ...]] |
로그들을 destkey로 병합 | O(N) |
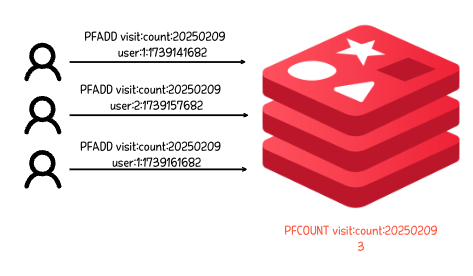
활용 예시

일일 방문자 수를 Hyerploglog로 구현해보자. 유의할 점은 100% 정확한 수치가 아닐 수도 있다는 점이다.