

GitHub - mag123c/nest-graphQL
Contribute to mag123c/nest-graphQL development by creating an account on GitHub.
github.com
graphQL
graphQL은 기존 데이터로 쿼리를 실행하기 위한 API를 위한 쿼리 언어이자 런타임이다. 클라이언트가 필요한 것만 정확히 요청할 수 있게 해준다.
공식 문서의 설명을 읽어보면 자세한 특징을 서술해두었고, 읽어보면 공통적으로 나오는 키워드들은 빠르다, 단일 요청, 쿼리와 타입 정도가 있다.
또한 공식 문서 내의 포스팅 중 REST와 비교한 글이 있었는데, "graphQL은 REST와 크게 다르지 않지만, API를 구축하고 소비하는 개발자 경험에 큰 차이를 만드는 작은 몇가지의 변화를 가지고 있다"고 한다.

REST API의 문제점
OverFetching
아래의 페이지는, 현재 근무하는 회사의 서비스인 아이웨딩의 페이지 일부이다.
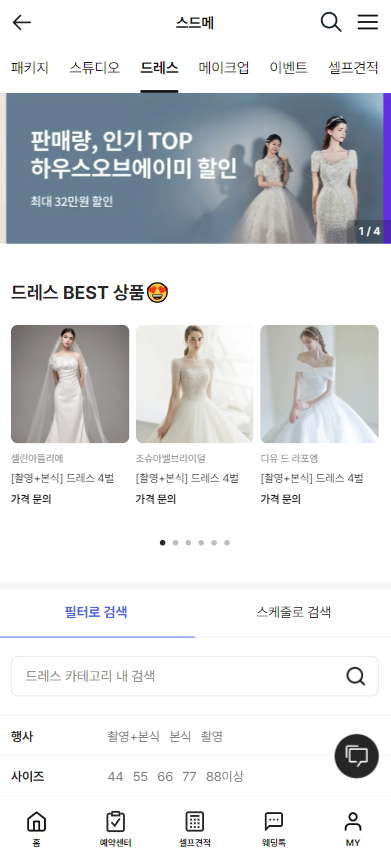

이 페이지를 구성하기 위해 적어도 해당 카테고리에 맞는 상단 배너와 베스트 상품, 리스트 API로 데이터를 받아와서 화면을 구성해야 할 것이다.
GET api/v1/banner?category=${category}
GET api/v1/products/best?category=${category}
GET api/v1/products?category=${category}

상품의 리스트 부분에서, 클라이언트에게 필요한 것은 브랜드명, 상품명, 가격 정보다.
하지만 product 내에 해당 정보를 포함한 다른 정보들도 들어 있는 경우도 많다. 수 년 동안 같은 리스트의 정보에 대한 요구사항이 변했을 수도 있고, 그런 이유가 아니더라도 API의 규격에서 확장하거나 축소해서 커스텀하는 경우도 있을 것이다. (이런걸 REST라고 해야하나..?)
우리의 Product List API 또한 그런 형태가 되어있었다.

굳이 클라이언트에게 필요 없는 데이터들이 REST 에서는 같이 나가게 되는 경우가 빈번하고 이럴 경우 네트워크의 대역폭이 낭비되게 된다. 데이터가 필요 이상으로 커지기 때문이다. 이런 현상을 OverFetching이라고 한다
UnderFetching
이번엔 외부로 시선을 돌려보았다.
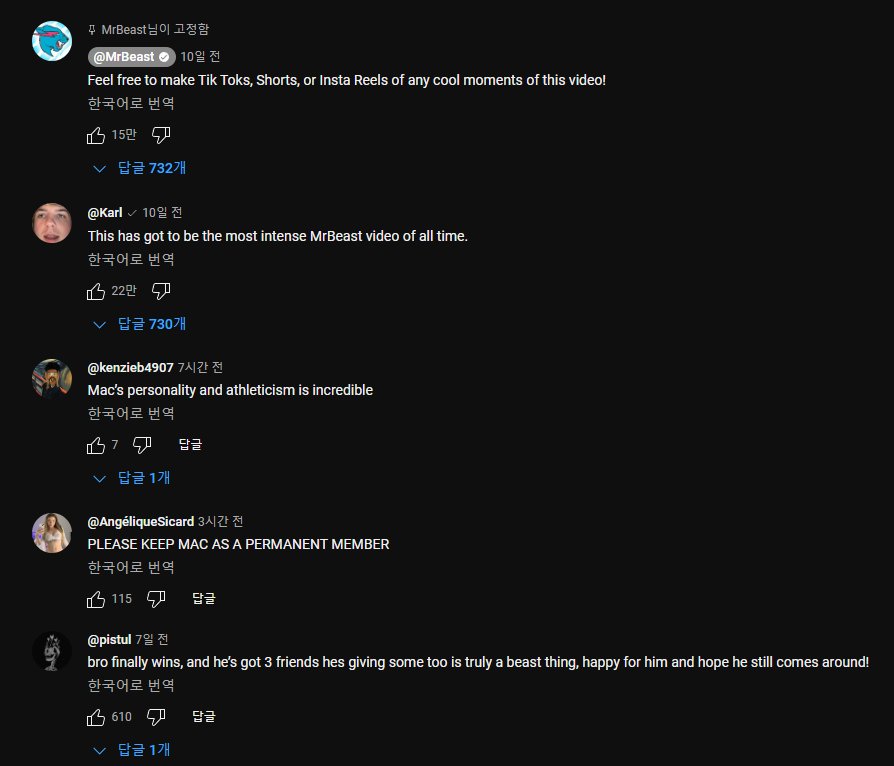
영상의 댓글을 가져오기 위해 나는 GET videos/1/comments API를 호출했다. 하지만 comments API의 응답에는 댓글을 쓴 사람의 nickname, thumbnail 정보가 포함되어 있지 않다.
따라서 댓글 작성자의 정보를 얻기 위해 추가적으로 GET user/{userId} API를 호출해서 유저 정보를 받아와야 한다.
(만약 클라이언트 사이드의 모든 상황에서 comments에 유저 정보를 필요로 한다면 comments API 자체를 커스터마이징하면 된다.)
이 때 두가지 문제가 발생하는데, 첫 번째는 해당 API에서 원하는 정보를 모두 가져오지 못해 추가적인 API 호출이 이루어졌다는 점이고, 두 번째는 user API 역시 nickname, thumbnail을 포함한 유저 정보가 들어있기 때문에 OverFetching이 일어났다는 점이다.
이렇게 하나의 API에서 모든 데이터를 처리하지 못해 추가로 요청하여 처리해야하는 현상을 UnderFetching이라 하며, UnderFetching은 추가 데이터 요청 과정에서 OverFetching까지 초래할 수 있다.
graphQL로 전환
다시 위 사진에서 graphQL API인 POST /graphql 로 요청을 보낸다면 아래처럼 응답을 받을 수 있다.
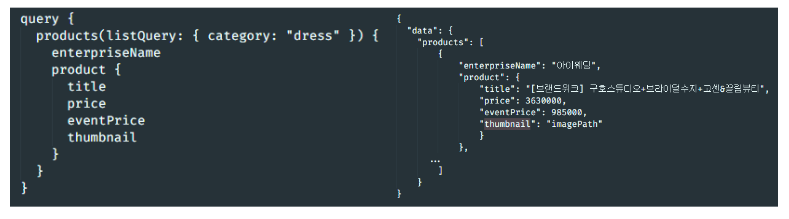
딱 원하는 데이터에 대한 응답만 받을 수 있는 것이다.
graphQL의 단점
캐싱
개발을 하면서, 304(Not Modified)라는 상태코드를 본 적이 있을 것이다. 요약하자면 클라이언트가 요청한 리소스가 변경되지 않았음을 나타내는 이 상태 코드는 클라이언트가 캐시된 데이터를 사용할 수 있게 한다. 이는 서버의 응답을 줄이고 네트워크 트래픽을 절약하는 데 유용하다.
HTTP에서 제공하는 캐싱 정책은 단순히 헤더에 명시하는 것만으로 쉽게 적용할 수 있다. 또한 HTTP 캐싱 전략은 각 URL에 고유한 정책을 설정하는 형태로 이루어진다. REST API는 각 엔드포인트마다 다른 캐싱 정책을 설정할 수 있어 HTTP의 캐싱 전략을 그대로 사용할 수 있다. 그러나 graphQL은 단일 엔드포인트인 /graphql로 들어오기 때문에 기존의 HTTP 캐싱 전략을 적용하기 어렵다.
이로 인해 서버와 클라이언트 측 모두 적절한 캐싱 처리를 구현해야 하며, 캐싱 전략도 별도로 사용해야 한다.
기타
이 외에도, 파일 업로드를 위한 추가처리, REST와 달리 버전 관리의 어려움의 단점이 있으며
graphQL 스키마 설계와 리졸버, 쿼리 최적화 등의 높은 러닝커브 또한 단점으로 꼽힌다.
Nest + TypeORM + graphQL
apollo, mercurius을 기본적으로 지원하고, 커스텀 드라이버도 사용할 수 있다고 한다. 나는 apollo를 사용했고, 접근성이 좋은 블로그나 SNS 등의 일반적인 포맷인 게시물 + 유저 형태로 코드를 작성해가며 학습했다.
리졸버의 사용에 익숙해지고, graphQL의 데코레이터들에만 익숙해진다면 금방 따라갈 수 있다.
내가 학습하면서 기록하고 싶은 부분들을 서술해보고자 한다.
독립적으로 구현 가능
posts API에서 우리는 정책상 comments, author을 모두 들고오기로 했다고 해보자.
@Injectable()
export class PostService {
constructor(
private postRepo: PostRepository,
) {}
async getPostsAuthorAndComments(authorId?: number) {
return await this.postRepo.findPostsAuthorAndComments(authorId);
}
}@Injectable()
export class PostRepository implements BaseRepository<Post> {
constructor(
@InjectRepository(Post) private postRepo: Repository<Post>,
) { }
async findPostsAuthorAndComments(authorId?: number): Promise<Post[]> {
const query = this.postRepo.createQueryBuilder('post')
.leftJoinAndSelect('post.author', 'user')
.leftJoinAndSelect('post.comments', 'comment')
.leftJoinAndSelect('comment.author', 'commentAuthor')
if (authorId) {
query.where('post.authorId = :authorId', { authorId });
}
return await query.getMany();
}
}
위와 같이 작성한다면 findPostsAuthorAndComments 함수는 authorId에 따라 포스트와 관련된 모든 데이터를 한번에 가져온다. 아래처럼 완전 분리해서 구현도 가능하다.(커넥션이 많아져서 선호하진 않지만)
@Injectable()
export class PostService {
constructor(
private postRepo: PostRepository,
private commentRepo: CommentRepository,
private userRepo: UserRepository,
) {}
async getPostsAuthorAndComments() {
const posts = await this.postRepo.findAll();
await Promise.all(posts.map(async (post) => {
post.author = await this.userRepo.findOne(post.authorId);
post.comments = await this.getCommentsByPostId(post.id);
}));
return posts;
}
}
리졸버에서도, 똑같이 ResolveField 데커레이터를 사용해서 쿼리의 데이터 내부의 관계에 따라 추가적인 동작을 할 수 있다.
@Resolver(of => Post)
export class PostResolver {
constructor(
private postRepo: PostRepository,
private userRepo: UserRepository,
private commentRepo: CommentRepository,
) { }
@Query(() => [Post])
async posts(
@Args('authorId', { type: () => Number, nullable: true }) authorId?: number,
): Promise<Post[]> {
console.log('전체 글 목록을 가져오는 리졸버')
return this.postRepo.findAll(authorId);
}
@ResolveField(() => User)
async author(@Parent() post: Post): Promise<User> {
console.log('글의 작성자를 가져오는 리졸버')
return await this.userRepo.findOne(post.authorId);
}
@ResolveField(() => [Comment])
async comments(@Parent() post: Post): Promise<Comment[]> {
console.log('코멘트를 가져오는 리졸버')
return await this.commentRepo.findByPostId(post.id);
}
}
@Resolver(of => Comment)
export class CommentResolver {
constructor(private userRepo: UserRepository) {}
@ResolveField(() => User)
async author(@Parent() comment: Comment): Promise<User> {
console.log('코멘트의 작성자를 가져오는 리졸버')
return await this.userRepo.findOne(comment.authorId);
}
}
@ResolvedField는 특정 엔터티의 필드가 다른 엔터티와 연관이 되어 있을 때, 해당 연관된 데이터를 가져오는 로직을 정의하는 데 사용된다. 위처럼 각 로직들을 개별 메서드로 분리하여 코드의 가독성과 유지보수를 높일 수 있다.

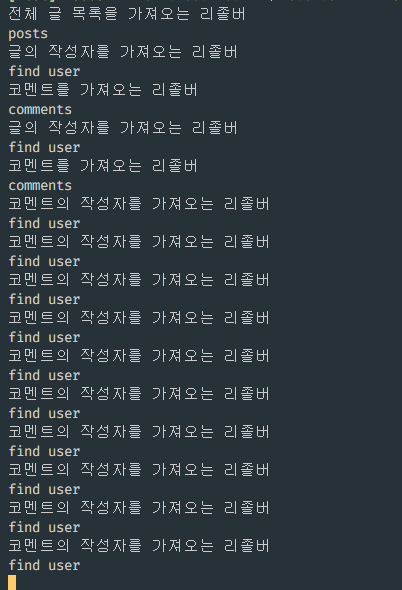
이런 요청을 보내면, 순차적으로 posts를 찾고 posts에 대한 author, posts에 대한 comments를 찾은 뒤 각 코멘트의 author을 찾는 순서로 이루어진다. ResolvedField로 관계 매핑을 확인하여 해당 로직으로 데이터를 가져와 넣어주게 된다.
(글을 2개써서 2번의 글 작성자를 가져왔다)
InputType, ObjectType, ArgsType
이 데커레이터들은 데이터를 주고 받는 구조를 명확히 정의할 수 있는 데커레이터들로, 데이터 교환이 일관되고 예측 가능하게 한다. nest에서는 이 위에 Validation, Trasnforming등을 할 수 있어 강력한 검증이 가능하다.
기존의 Dto를 graphQL을 사용하기 위해 데커레이터를 덧씌워준다고 생각하면 되겠다. gql 타입 정의를 통해 자동 문서화도 된다.
@InuptType()은 주로 뮤테이션의 인자로 사용되는 입력 객체를 정의할 때 사용한다.
@ObjectType()은 객체 타입을 정의할 때 사용하고, 데이터를 반환할 때 사용되는 타입을 정의한다.
@InputType()
export class WritePostReq {
@Field(() => String, { nullable: false })
title: string;
@Field(() => String, { nullable: false })
content: string;
@Field(() => Int, { nullable: false })
authorId: number;
}
@ObjectType()
export class WritePostRes {
@Field(() => String, { nullable: false })
title: string;
@Field(() => String, { nullable: false })
nickname: string;
@Field(() => Date, { nullable: false })
createdAt: Date;
}@Mutation(() => WritePostRes)
async writePost(
@Args('postInput') postInput: WritePostReq,
): Promise<WritePostRes> {
const post = await this.postRepo.savePost(postInput);
const author = await this.userRepo.findOne(post.authorId);
return {
title: post.title,
nickname: author.nickname,
createdAt: post.createdAt,
};
}
@ArgsType()은 쿼리나 뮤테이션의 파라미터를 정의할 때 사용되며, @Args()와 함께 사용하여 특정 필드를 파라미터로 받을 수 있다. 위의 posts Query를 아래와 같이 변경할 수 있다.
@ArgsType()
export class PostArgs {
@Field(() => Int, { nullable: true })
authorId?: number;
@Field(() => Int, { nullable: true })
limit?: number;
@Field(() => Int, { nullable: true })
offset?: number;
}@Query(() => [Post])
async posts(@Args() postArgs: PostArgs): Promise<Post[]> {
return this.postService.findAll(postArgs);
}
//@Args('authorId', { type: () => Number, nullable: true }) authorId?: number,
//@Args('limit', { type: () => Number, nullable: true }) authorId?: number,
//@Args('offset', { type: () => Number, nullable: true }) authorId?: number,
REST vs graphQL
기술 블로그들에 잘 설명 되어있는 정보 전달성 versus를 제외하고, 실무에서 써본적이 없는 주니어 개발자인 내가, 현재 업무와의 연관성을 지어보면서 단순 학습만으로 어떻게든 둘의 차이를 느껴보려고 했다.
OverFetching + UnderFetching
실제 프로덕션을 보면서 생각보다 이런 문제가 심각할 수도 있는 경우가 아마 클라이언트 측 사양이 낮은 경우가 있지 않을까 싶다. 항상 최신식에 가까운 사양의 장비들로 개발을 하다보니 이런 부분을 놓칠 수 있다. 이런 측면에서 봤을때 graphQL은 괜찮은 대안이 될 수 있을 것 같다.
문서화(Swagger는 어려워요)
Swagger은 API 문서화를 위한 강력한 도구지만, 아무리 서술을 잘 해두어도 프론트 개발자 분들이 Swagger만 보고 완벽하게 개발을 할 수는 없다. API를 개발한 당사자의 의도도 100% 파악하기 어렵다. graphQL은 보다 직관적이게 쿼리나 뮤테이트의 타입들만 보고 확인할 수 있으니 데이터의 구조와 관계를 더 명확히 이해할 수 있을 것이고 협업 시에 더 이점을 제공할 것 같다.
참조
GraphQL | A query language for your API
Evolve your API without versions Add new fields and types to your GraphQL API without impacting existing queries. Aging fields can be deprecated and hidden from tools. By using a single evolving version, GraphQL APIs give apps continuous access to new feat
graphql.org
Documentation | NestJS - A progressive Node.js framework
Nest is a framework for building efficient, scalable Node.js server-side applications. It uses progressive JavaScript, is built with TypeScript and combines elements of OOP (Object Oriented Programming), FP (Functional Programming), and FRP (Functional Rea
docs.nestjs.com
Streamlining APIs, Databases, & Microservices | Apollo GraphQL
Unlock microservices potential with Apollo GraphQL. Seamlessly integrate APIs, manage data, and enhance performance. Explore Apollo's innovative solutions.
www.apollographql.com
diehreo@gmail.com
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!


![[NestJS] enum과 literal type 중 어떤걸 사용할까? (feat. Tree-shaking, Template Literal Ty](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbFh5aG%2FbtsFYsHVUJD%2FAAAAAAAAAAAAAAAAAAAAALOutFWN8rHk5w6wTXomzS3yskPG71vS5qgtiy32sbWQ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3Dw8O%252FUirZ5acVGPN0neknUDthsDA%253D)
![[NestJS] JWT Token 인증 - (3) Refresh Token 사용](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FOg7S7%2FbtsArwhY9kt%2FAAAAAAAAAAAAAAAAAAAAAFIMG3_Usht8EFjAk73N0pKQrrcX3EW2piGkpE3Qbf_l%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DXgPmVFmar5a06aLsQN4%252B%252FcFk2b0%253D)